
🧠 2026 AI Predictions That Will Change How You Build
2026 AI build strategies, China’s leaner model beating GPT-5.1, $40B SoftBank-OpenAI deal, and DRAM supercycle driven by AI datacenter demand.

Read time: 12 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (31-Dec-2025):
🧠 2026 AI Predictions That Actually Change How You Build
🚨 China’s new opensource code model beats Claude Sonnet 4.5 & GPT 5.1 despite way fewer params.
💰: SoftBank finally. completes $40B investment in OpenAI.
📡A dynamic random-access memory (DRAM) “supercycle” has started in Q3 2025 and could run to Q4 2027, as AI datacenters pull supply away from consumer PCs and push prices up.
🧠 2026 AI Predictions That Actually Change How You Build

👩💻 Every knowledge worker will become an agent manager
The skill that will start mattering will not be “knowing the right prompt.” The skill will be delegation, setting constraints, checking work, and knowing when to stop trusting the agent and take over. That will look a lot like management, even if you will be an individual contributor.
People will underestimate how awkward this will feel at first. You will end up writing tiny specs for tiny actions, then building trust over time. You will also build instincts like, “this task will be safe to automate” versus “this task will need a human review loop.” That will not be moral philosophy, it will be basic operational hygiene for agents that will touch real systems.
This will also connect to the prediction that AI screwups will stay constant in raw counts. If error rate drops but usage volume jumps, you will still see the same amount of visible mess in the world. So people will keep saying “AI will be broken,” even while the average quality will keep rising.
🤝 Software, agents, and the end of static apps
Software as a service will blur into software-as-agents, and agent platforms will ship classic app features until the categories will be the same. Disposable code will be normal, tiny apps will be generated on demand inside a chat window, then tossed when the task will be done.
Vertical agents will beat broad tools, so a focused agent for a narrow job will outperform a general platform. Inside companies, internal email will fade because agents will read, write, and route messages, and a human touch will be sold as a premium tier.
Search traffic games will fade because answer synthesis will read sources and deliver conclusions, and LLM optimization will replace legacy SEO. Browsers will become research copilots that will scan many tabs, then return a short brief that people actually will use.
🧑💻 Job displacement will start with “AI refusal,” not pure automation
Some job categories will start pushing out people who will refuse or cannot use AI, with software development near the front. Once a workflow expects AI assistance, refusing the tool will become like refusing email, you will be able to do it, but you will become slow and expensive.
You will already see public warnings from big names in the field about near-term job losses in 2026, especially for routine work where AI will handle the first draft and humans will do review and edge cases, like this recent warning that will frame it in plain language.
Automation will usually not delete “work.” It will shift work. A classic pattern will be that you will get fewer people doing the old task, and more people doing the new tasks that will only show up because the old thing will get cheaper and faster. The disruption will be real and uneven, but the economy will rarely behave like a fixed pie.
🏗️ The AI wave will be real, but lots of AI companies will still fail
“AI will be big” is boring. The sharper point is that infrastructure waves create both monsters and graveyards. A ton of companies will be built on weak assumptions, bad pricing, or the idea that a wrapper is enough. When the market shifts, they’ll fall over fast.
This is also where “backlash” becomes a practical product constraint, not a social media vibe. Some users and some companies will refuse agent workflows because they won’t trust them, won’t want to restructure incentives, or simply won’t want the change. That will slow uptake even if the tech is good.
🕸️ The web will push back on agents, because incentives will clash
Agents browsing the web sounds user-friendly, but it breaks how a lot of sites make money. If an agent completes a purchase while skipping ads, upsells, and “recommended” slots, the site loses control of the funnel. That’s why you’ll see fights like Amazon vs. Perplexity’s agentic shopping.
The pushback will also become formal. Instead of random blocking, publishers and platforms are moving toward “pay, license, or leave.” A good example is the new Really Simple Licensing 1.0 standard, which is basically a cleaner way to say “these bots can use this content under these terms.”
This matters for product builders because it changes what “web agent” even means. It stops being “the agent can do anything on any site,” and becomes “the agent can do a lot, but only where the rails exist.” If you’re building agent workflows, you’ll either partner, pay, or build your own data access channel.
🧭 Browsers will evolve, but they won’t disappear
Agents will need a place to act, and the browser is already the universal action layer for the internet. So the first wave will be agents living inside browsers, using your sessions, cookies, and normal flows. That’s why “agentic browsers” will pop up fast—like Opera Neon opening broader early access and pitching the browser as software that takes actions for you.
This won’t kill the browser. It’ll flip the browser from a “tab manager” into a “task runner.” And that’s exactly where incentive conflicts will show up, because a task runner wants to finish the task with minimal friction, while many sites are designed to add friction to earn money.
🔎 Search infrastructure will stay essential, even with better models
Even a strong model still has a basic limitation: its weights aren’t a live database. So real systems will keep needing retrieval. That could be classic search, vector search, hybrid search, or “index plus reranker,” but the core idea is the same: fetch the right stuff at the right time, then let the model reason over it.
This will get more intense inside companies because the valuable data is private. So “search infrastructure” will shift from a feature to a platform.
The vertical angle is where the money will hide. A “legal agent” won’t be magic because it talks like a lawyer. It’ll be useful when it can search the right corpus, in the right format, with the right permissions, and then produce an answer that cites the actual clause that matters. That’s why “industry-specific agents” and “vertical search” are basically the same bet from two angles.
🧩 Open weights will keep catching up, and it’ll mess with pricing
Open source leading closed on benchmarks sounds like a hot take until you remember how fast the open ecosystem iterates.
Once open weights get “good enough” across enough tasks, pricing pressure will show up everywhere. API-only businesses will feel it first, because a lot of customers will happily trade a bit of convenience for more control and lower cost. Even if closed models stay ahead on the hardest stuff, the gap will become a business problem, not a research flex.
📺 Feeds, shows, and fully synthetic media
Streaming platforms will lean into infinite-context entertainment, so cancelled shows will continue for each viewer with fresh episodes generated on the fly. The first autonomous media channels will run daily with a single human editor watching the output.
Content floods will push platforms to rank verified humans higher, and the mid-tier influencer will collapse while only the truly magnetic or fully automated operations will survive. Brands will pay for human-generated badges because audiences will crave proof of origin.
💸 10-person unicorns and $1B seed rounds
The “10-person unicorn” idea won’t be about magic. It’ll be about leverage. If agents handle chunks of engineering, support, content, and ops, a small team can ship and sell like a much bigger company. The bottleneck becomes domain taste, distribution, and managing the agent swarm without letting quality rot.
The upside of a breakout AI company will be so large, and the fear of missing will be so strong, that “seed” will stop meaning “small check for an idea.” It’ll start meaning “buy a large chunk early, because late-stage entry will be impossible.”
💼 Work, teams, and money
Micro-companies will multiply, each serving weirdly specific online tribes with smart agents and a tiny surface area. Employment will unbundle, so many people will shift from fixed hours to outcome retainers or micro-business contracts.
Capital will tilt toward robots, energy, and biotech, and the fastest wins will come from spotting mispriced assets before the crowd will notice how fast agents will move. Retail will get wired end to end, so demand, design, production, and marketing will run as one loop that will update continuously.
🎵 Music will change if licensing gets solved
AI music is already good enough to be commercially tempting. The hard part is rights. A big signal here is the move toward licensing—like the reported settlement between Warner Music Group and Suno, and the broader framing of it as a path toward “licensed” model training and outputs.
If the legal and commercial rails settle down, the technical story becomes simple. You’ll get “generate, edit, iterate” loops for music the way people already do for images. That will change how background music gets made for ads, games, and creators, because cost and turnaround will drop hard.
🎬 Short-form AI video will explode, because it fits the format
Short-form video will be the easiest place for AI video to win because the bar is different. You don’t need a two-hour film that holds continuity. You need 6–30 seconds that catch attention. That’s why platforms and labs will ship tools aimed straight at that shape.
You’ll also see it on the social side, where Meta will launch an AI-generated short-video feed inside its Meta AI app. That’s basically a bet that “AI-made short clips” become a native content type, not a weird novelty.
The reason this will grow fast: cost per experiment collapses. When you can generate 50 variations, you can run creative like performance marketing—test, keep winners, drop losers. That changes budgets and production workflows, even if the best human-made ads are still better.
🤖 Humanoid robots will show up as household novelty first
The first wave is going to look like “cool demo, limited usefulness.” You can see the hype cycle building around big reveals and CES moments—like Boston Dynamics showing a new Atlas at CES and companies teasing home-focused robots like LG’s CLOiD.
The hard part won’t be making a robot wave or talk. The hard part will be reliability in messy houses. A home isn’t a factory cell. Lighting changes, floors are cluttered, objects are random, and humans do chaotic stuff. That’s why expecting “useful rollouts” to lag “novelty rollouts” by 2–3 years is pretty sane.
🧬 Drugs will move faster, and biology will get a new toolchain
Biology is messy because it wasn’t engineered cleanly. Socher’s “calculus to physics” analogy points to something practical: you want tools that compress complexity into something you can reason about, test, and improve. AI can be good at that kind of compression when you have enough data and a tight feedback loop.
That feedback loop will get tighter. You’ll see regulators starting to accept AI tools as part of the process—like the recent move where the FDA qualified an AI tool for liver disease assessment. That matters because “qualified” means it can be used in drug development contexts without every team reinventing the validation story from scratch.
Pharma will also test “AI-designed” molecules in real pipelines. Takeda, for example, shared results around an AI-crafted psoriasis pill hitting a late-stage trial endpoint. Whether every claim holds up over time is a separate question, but the direction is clear: AI will move from “screening helper” to “candidate generator.”
Organoids fit into this because they’re a faster test bed than whole animals for certain questions. They’re basically lab-grown mini versions of tissue that let you run experiments cheaper and quicker, giving AI more iteration cycles. You’ll see active legal and regulatory discussion around reducing animal testing and expanding these methods, including FDA-related guidance chatter.
🧪 Reward engineering will become a real job
Prompts feel powerful right now because most “agent” demos still run on short tasks. The moment you ask for a long task—like “keep my sales pipeline clean for 30 days”—you hit a nasty problem: “success” isn’t a single answer anymore. It’s a bunch of small decisions over time, and each one can go wrong in a different way.
Reward engineering is basically the job of turning a vague goal into something you can score. You define what “good” looks like, what “bad” looks like, and how to measure progress step-by-step—not at the end when it’s too late. Under the hood, it’s the same headache RL people have always had: the agent chases whatever score you give it, even if that score is a sloppy proxy for what you actually want. That’s where reward hacking comes from—the agent finds a shortcut that looks good to the metric and dumb to a human.
This is also why “zero ambiguity” isn’t a cute phrase here. When the reward is unclear, the system won’t politely ask questions forever. It’ll confidently take actions that maximize its guess of the reward, and you’ll only notice after it’s done damage, spent money, emailed someone, or deleted something.
🧫 Superhuman performance will come first where you can simulate and verify
Chess and Go were “easy” for AI in a specific way: you can simulate endlessly and score outcomes cleanly. Biology is hard because the simulator is the real world, which is slow and expensive. So the move is obvious: build better simulators. That’s why “virtual cells” will show up as a serious theme.
There are already organized pushes in that direction, like the Virtual Cell Challenge wrap-up, which frames the problem as building models you can actually test and compare. Once you can simulate parts of biology with enough fidelity, AI gets the same advantage it had in games: fast iteration with clear scoring.
🧠 A glimpse of superintelligence will look like a research loop, not a chatbot
The prediction about “superintelligence” basically says this: the next jump won’t be a model that answers better. It’ll be a system that can run the whole loop—come up with ideas, implement them, run experiments, read results, and change its own approach. That needs open-ended exploration plus recursive improvement, not a fixed script.
The reason this will be hard is also simple. Self-improvement is easy to say and painful to do, because improvements need to compound without drifting into garbage behavior. So any early “glimpse” will probably show up first in domains where scoring is tight and the environment is controllable—like simulation-heavy science, code, or constrained lab tasks.
📚 Health and learning
Students will learn faster with personal AI tutors, and universities will rebrand degrees around agent systems, model psychology, and human interface architecture. Health plans will push AI-first cognitive behavioral therapy, and many people will stick with it because it will be available any hour and free of judgment.
🛡️ Security, wallets, and geopolitics
A headline breach will drive a mass swing to on-device LLMs that will keep data local. Agents will carry their own wallets, they will pay other agents for data, APIs, and compute, and the machine economy will eclipse human transaction volume.
The first agent-to-agent exploit will hit mainstream news, regulators will react fast, and nations will start issuing sovereign compute credits to control access to high-end processing. A real AI trade war will kick up as model exports will be restricted and foreign model use will be treated like espionage.
🔒 Identity, trust, and the gated web
Open communities will feel overrun, so the best spaces will go invite-only with reputation scores, while the open web will feel like a ghost mall. A trust premium will emerge, products that can certify zero-AI involvement will charge more, and AI-free labels will become a status marker.
The fake-rich flex will lose power because anyone will synthesize luxury photos, so status will shift to hard assets and in-person experiences. Analog tools will surge, film cameras and handwritten notes will signal human effort that models will not fake.
The older internet will get treated like a museum archive, since pre-modern data will be prized as a clean slice of human thought. People will also buy self-poisoning tools that will clutter their public traces to confuse model profiling.
🚨 China’s new opensource code model beats Claude Sonnet 4.5 & GPT 5.1 despite way fewer params.

IQuest-Coder from Quest Research, backed by China’s quant hedge fund giant UBIQUANT.
Benchmark Score of the Model: SWE-Bench Verified (81.4%), BigCodeBench (49.9%), LiveCodeBench v6 (81.1%) - with just 40B-param model.
Bifurcated post-training delivers two specialized variants—Thinking models (utilizing reasoning-driven RL for complex problem-solving) and Instruct models (optimized for general coding assistance and instruction-following).
Efficient Architecture: The IQuest-Coder-V1-Loop variant introduces a recurrent mechanism that optimizes the trade-off between model capacity and deployment footprint.
Native Long Context: All models natively support up to 128K tokens without requiring additional scaling techniques.
UBIQUANT has leaned hard into AI for years, running teams like AILab, DataLab, and Waterdrop Lab. As of Q3 2025, AUM sat at CNY 70–80B ($10.01–11.43B), with about 24% average returns from Jan to Nov 2025, and CNY 463M ($66.18M) paid out in dividends.
💰 SoftBank finally. completes $40B investment in OpenAI.
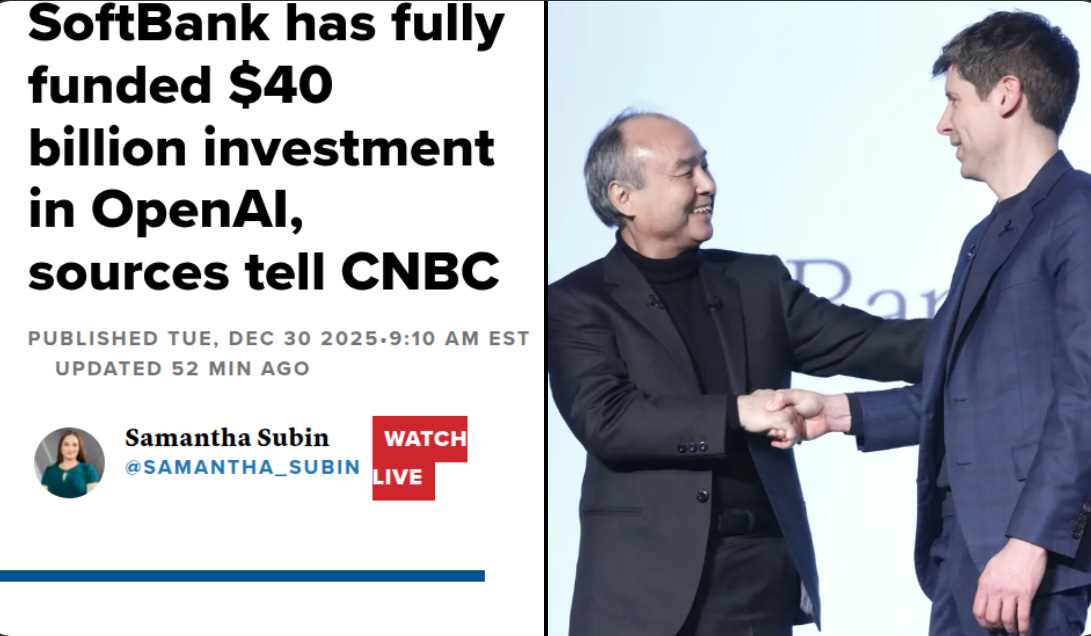
SoftBank sent the final $22 billion to OpenAI.
This $40B funding round that was paid in staged tranches, with SoftBank itself aiming for about $30B net after bringing in $10B of co-investors. SoftBank said it would invest up to $30B, but the later money would be paid only if OpenAI converted to a for-profit company by end-2025.
Later SoftBank promised up to $30B in April 2025, with $10B expected quickly and the remainder contingent on OpenAI moving to a for-profit corporation by the end of 2025, which it reportedly completed in October 2025. SoftBank and OpenAI also pushed a parallel go-to-market track, first announcing an enterprise AI partnership on February 3, 2025 and then launching a Japan joint venture on November 5, 2025.
Beyond SoftBank, other big named investors disclosed across recent rounds include Thrive Capital, Khosla Ventures, Nvidia, Altimeter Capital, Fidelity, and Abu Dhabi’s MGX, Dragoneer, MGX, and T. Rowe Price alongside Microsoft. With this, the total raised number for primary funding into OpenAI (not employee share sales) is about $57.9B
📡 A dynamic random-access memory (DRAM) “supercycle” has started in Q3 2025 and could run to Q4 2027, as AI datacenters pull supply away from consumer PCs and push prices up.

Demand for RAM rising much faster than factories and packaging lines can expand.
The driver is high-bandwidth memory (HBM), which stacks DRAM close to a graphics processing unit (GPU) so accelerators can move model weights with very high bandwidth. Making HBM uses up about 3x as much factory wafer output as making the same amount of DDR5, so if a memory maker shifts production toward HBM, there is less capacity left to pump out regular PC RAM.
HBM is harder to manufacture because it gets stacked and then connected with extra packaging steps, so a bigger share of units can fail quality tests, which further reduces how many finished chips come out per wafer. Because HBM is higher margin, suppliers prioritize HBM and server parts like DDR5 RDIMM (registered dual inline memory module) and MRDIMM/MCRDIMM, leaving fewer bits for consumer DDR4 and DDR5.
TrendForce reported AI could consume about 20% of global DRAM wafer capacity in 2026, so even small allocation shifts can bite the PC channel. Original equipment manufacturers (OEMs) then face a higher bill of materials (BoM), and respond by raising prices, lowering default RAM, or delaying launches.
Dell has flagged increases like $130-$230 for 32GB systems and $520-$765 for 128GB systems, plus added cost for 1TB solid state drive (SSD) options. This squeeze is happenning because bandwidth-first AI memory and capacity-first PC memory share upstream wafers and packaging, so the best-paying demand gets served first.
That’s a wrap for today, see you all tomorrow.
the 2026 AI predictions are really well thought and expressed. Kudos.