
🏦 45 Million U.S. Jobs at Risk from AI
AI may replace 45M U.S. jobs, UBI resurfaces, ChatGPT Projects go free, EmbeddingGemma from Google released, Agentic design book drops, OpenAI hits $500B, 40% of code now AI-written at Coinbase

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (-Sept-2025):
🏦 45 Million U.S. Jobs at Risk from AI, Report Calls for UBI as a Modern Income Stabilizer
🧰 OpenAI brings ChatGPT Projects to free users with file uploads and customisation
📡 Google released EmbeddingGemma, new open embedding model for on-device AI applications
👨🔧 Google Senior Engineer just dropped a Free 400+ page book “Agentic Design Patterns”
🏦 NEWS: OpenAI is allowing current and former employees to sell more than $10 billion worth of stock in a secondary share sale, at a $500B valuation
📢 Coinbase CEO Brian Armstrong just confirmed 40% of daily code written are AI-generated
🏦 45 Million U.S. Jobs at Risk from AI, Report Calls for UBI as a Modern Income Stabilizer
The Gerald Huff Fund for Humanity has published a new study, Impact of AI on Workers in the United States, showing that artificial intelligence could affect about 1 in 4 jobs in the country by 2028. The report cautions that this shift may spark a once-in-a-century level of economic disruption, calling for strong policies to safeguard households and communities.
The study maps 745 occupations across 20 industries using the U.S. Department of Labor’s Occupational Information Network (O*NET) plus the North American Industry Classification System (NAICS), so every estimate traces back to concrete job tasks.
They define AI Disruption Score as the chance that tasks get automated, AI Creation Score as the chance AI spawns new roles, and AI Impact Score as disruption minus creation, then weight by industry size and employment share.
By this method Retail Trade shows 6.6 million jobs at risk, Healthcare and Social Assistance 6.4 million, Educational Services 4.6 million, and Finance and Insurance 2.2 million.
The shift targets white collar and administrative work in HR, finance, customer support, education, and care settings, not only physical labor.
The report argues retraining has limits, since displaced workers often land in lower wage tracks or face long income losses.
The authors push UBI as a modern stabilizer, saying predictable cash lets people search for better matches, try training with less risk, or start small businesses.
They also call to protect open workforce data and to double down on human skills like empathy, adaptability, creativity, and judgment that are hard to codify.
The model is explicit about tradeoffs by netting job creation against disruption, so it avoids counting only one side of the ledger.
🧰 OpenAI brings ChatGPT Projects to free users with file uploads and customisation
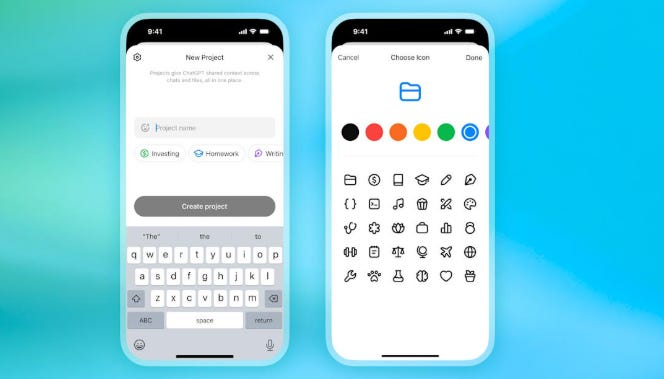
The headline feature is memory control, so a project can either use memories from outside chats or run project only to block context bleed.
Each project works like a workspace where ChatGPT remembers prior messages, grounds answers in your files, and follows project instructions without repeating them.
Free users can attach 5 files per project, Plus and Edu allow 25, and Pro, Business, and Enterprise allow 40, and only 10 files can be uploaded at once. Users can create unlimited projects, set colors and icons for quick scanning, and move old chats into a project so they inherit context.
Enterprise workspaces carry over controls like tool restrictions, retention rules, regional data residence, and encryption, and project data is available to compliance auditing tools.
Deleted projects are purged within 30 days unless retention is legally required. The rollout covers web and Android now with iOS following soon, and free accounts face tighter rate limits than paid plans.
For recurring research, writing, or planning, this keeps threads focused and cuts instruction churn because every turn starts inside the right project context.
📡 Google released EmbeddingGemma, new open embedding model for on-device AI applications

EmbeddingGemma, is Google’s new open embedding model for on-device AI applications.
Highest ranking open multilingual text embedding model under 500M on the Massive Text Embedding Benchmark (MTEB). and performs close to models nearly 2x larger.
Packs only 308M parameters, accepts 2K tokens, and with quantization runs in <200MB RAM on everyday hardware.
Based on the Gemma 3 architecture,
small enough to run on less than 200MB of RAM with quantization.
ultimate flexibility with Matryoshka Representation Learning (MRL) to provide multiple embedding sizes from one model.
full 768-dimension vector for maximum quality or truncate it to smaller dimensions (128, 256, or 512) for increased speed and lower storage costs.
Latency is <15ms per embedding at 256 input tokens on EdgeTPU, which keeps mobile interactions snappy.
In a RAG flow, it embeds the query and local docs, retrieves nearest chunks, then Gemma 3n generates the answer grounded in those chunks.
Training spans 100+ languages, and sharing a tokenizer with Gemma 3n reduces memory in the pipeline while keeping everything on device for privacy.
Support already exists across sentence-transformers, llama.cpp, MLX, Ollama, transformers.js, LlamaIndex, LangChain, and vector stores like Weaviate.

For ultimate flexibility, EmbeddingGemma leverages Matryoshka Representation Learning (MRL)
Matryoshka representation learning is a way to train an embedding so the most important meaning is packed into the front of the vector. Because the meaning is front loaded, you can trim the vector to different sizes, like 768, 512, 256, or 128, and it still works well for similarity.
Bigger vectors usually give higher recall and better ranking, smaller vectors are faster and cheaper to store and compare.
As a developer, you ship 1 model and pick the vector length per use case, fast previews can use 128, final indexing can use 768. This means you can make a short 128 number vector for instant results, then later switch to a longer 768 number vector for best accuracy.
The model is trained so the front of the vector holds the core meaning, so even the 128 cut still ranks things sensibly. Short vectors are cheaper and faster to compute and search, and they use less memory and disk. Long vectors keep more detail, which improves recall for search and RAG.
On a phone, a notes app can embed queries at 128 for instant results, then re embed the saved notes at 512 or 768 when the device is idle.
In a vector database, cutting from 768 to 256 cuts memory and disk by about 3x, and speeds up nearest neighbor search.
For consumers, this means quick, private search and RAG on device, with the option to boost quality when there is time or power.
My take, this is a clean, practical design for tight memory and battery budgets, and the real test is how stable rankings stay across domains when vectors are shortened.
👨🔧 Google Senior Engineer just dropped a Free 400+ page book “Agentic Design Patterns”

It is the best resource for anyone serious about building real AI systems:
Key Learning Areas.
Real code examples - not just theory, but working implementations
Proven patterns - memory handling, exception logic, resource control, safety guardrail
Advanced techniques - multi-agent orchestration, inter-agent messaging, human-in-the-loop
Full chapter on MCP (Model Context Protocol) - a key framework for integrating tools with agents
It covers 21 core patterns across 4 sections:
1. Foundational patterns (prompt chaining, routing, tool use)
2. Advanced systems (memory, learning, monitoring)
3. Production concerns (error handling, safety, evaluation)
4. Multi-agent architectures
Most AI content stops at “how to call OpenAI’s API.” But in real-world systems you need to ask:
• What if the agent gets stuck mid-task?
• How do you preserve memory across long sessions?
• How do you prevent chaos when you run 10+ agents?
This book answers all that with patterns you can actually apply.
🏦 NEWS: OpenAI is allowing current and former employees to sell more than $10 billion worth of stock in a secondary share sale, at a $500B valuation

OpenAI expands secondary share sale to $10B: report, increasing the size of its secondary share sale from earlier planned $6 billion.
All the employees who have accumulated shares needed a way to offload them and this allows them to.
The window runs through September for people who have held shares for 2 or more years, with closing planned for October and buyers including SoftBank, Dragoneer, Thrive, MGX and T. Rowe Price.
A secondary share sale allows existing holders sell their private shares to new investors at a fixed price, the company raises $0 new capital and so, creates no new shares, and there is no dilution.
Companies use secondaries to mainly give employees liquidity, improve retention, reduce pressure to rush an initial public offering, and get a fresh market signal without running a new funding round.
Most large secondaries run as a tender offer that sets one clearing price, caps how much each person can sell, and checks transfer rules in the stock plan before shares move.
For OpenAI this converts paper gains into cash for long-tenured staff while the balance sheet stays unchanged after a primary earlier this year that valued the company at $300B.
The $500B print shows strong demand from late stage investors for more exposure, but it is a trading price for existing shares rather than a commitment to fund new growth.
Investors get access to a scarce position and the ownership list shifts toward crossover and sovereign pools, while board control typically does not change in a pure secondary.
Allocations finalize now, paperwork follows, and funds settle at closing in October.
🗞️ Byte-Size Briefs
Coinbase CEO Brian Armstrong just confirmed 40% of daily code written are AI-generated. and they are on their way to get it to >50% by October-2025.
Software Engineering is changing for good.


Their official blog said this
"In looking across the company, we find that teams that adopt LLMs at a faster rate are building frontend UI features, working with less-sensitive data backends, and quickly expanding their unit testing suites. Additionally, rapidly-developed greenfield products benefit greatly from the increased speed of LLM-based workflows. Where we do not see the same meaningful increase in productivity are low-level systems workflows, provisioning and cloud infra teams, complex and system-critical exchange systems, etc. We believe other parts of the development cycle such as planning, test, and observability may benefit these teams more."
That’s a wrap for today, see you all tomorrow.