
5 papers to help you understand better how OpenAI's o1 model might work
Some of the crucial papers that possibly contributed to OpenAI's 01 Strawberry model release


Highlights of the following 5 Papers, that seem to have been contributed to OpenAI’s 01 Strawberry releasing for boosting its thinking and reasoning capability.
Planning In Natural Language Improves LLM Search For Code Generation
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning
[1] Lets Verify Step by Step

📚 https://arxiv.org/pdf/2305.20050
Ilya Sutskever was a co-author of this Paper.
Key Insights from this Paper 💡:
👉 To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step.
👉 This Paper finds that process supervision significantly outperforms outcome supervision for training models to solve problems from the challenging MATH dataset.
• Active learning improves process supervision data efficiency by 2.6x
• Large reward models can approximate human supervision for smaller models
• Process supervision leads to more interpretable and safer AI alignment
Original Problem 🔍:
Large language models have improved at complex multi-step reasoning but still make logical mistakes. Comparing outcome supervision (feedback on final results) with process supervision (feedback on each reasoning step) is crucial for training more reliable models.
Solution in this Paper 🧠:
• Trained process-supervised reward models (PRMs) on 800K human-labeled solution steps
• Implemented active learning to select informative samples for labeling
• Compared PRMs to outcome-supervised reward models (ORMs) trained on 100 samples/problem
• Evaluated using best-of-N search over generator solutions
• Conducted small-scale experiments using large PRM as synthetic supervisor
• Released PRM800K dataset with 800,000 step-level human feedback labels
Results 📊:
• PRM solved 78.2% of MATH test problems (best-of-1860), vs 72.4% for ORM and 69.6% for majority voting
• PRM outperformed ORM across all problem difficulties and sample sizes
• PRM showed strong out-of-distribution generalization on recent STEM tests
• Active learning improved data efficiency of process supervision by 2.6x
[2] Planning In Natural Language Improves LLM Search For Code Generation

📚 https://arxiv.org/abs/2409.03733
Enhance Claude 3.5's Code Generation capability - by just Planning In Natural Language.
A novel search algo PLANSEARCH.✨
Claude 3.5 achieves a pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%)
Original Problem 🔍:
Scaling inference compute for large language models (LLMs) hasn't yielded gains comparable to scaling training compute, likely due to lack of diversity in LLM outputs during search.
Solution in this Paper 🛠️:
PLANSEARCH, a novel search algorithm for code generation:
• Generates diverse observations about the problem
• Constructs plans for solving the problem in natural language
• Searches over plans rather than directly over code solutions
• Translates promising plans into code implementations
• Employs public test filtering to select high-quality candidates
Key Insights from this Paper 💡:
• Searching over natural language plans improves diversity and effectiveness of code generation
• Diversity in idea space strongly correlates with search performance gains
• Base models often outperform instruct models at high sample counts due to higher diversity
• Public test filtering significantly improves search method efficiency
Results 📊:
• Claude 3.5 achieves a pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%)
• Outperforms no-search baseline (41.4% pass@1) and standard repeated sampling (60.6% pass@200)
• Demonstrates superior performance across HumanEval+, MBPP+, and LiveCodeBench
• Shows strong correlation between measured idea diversity and relative gains from search
[3] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters

📚 https://arxiv.org/abs/2408.03314
This Paper from Google's may have been long known by OpenAI.
In any case its a landmark paper from Google Deep Mind
The paper basically says - Searching at inference will give you great final result from the LLM.
Now from rumors Strawberra y is using some form of inference time compute strategies using Search techniques over the response space to improve reasoning.
------
How Search and Test-Time Compute are related
Search algorithms, when applied to LLMs, involve generating multiple candidate solutions or exploring different paths to find the best answer. This process happens entirely at inference time, making it a prime example of test-time computation.
The paper demonstrates that in certain scenarios, optimally allocated test-time compute (which includes search strategies) can indeed outperform larger models.
📌 By applying compute-optimal scaling strategies, the paper demonstrates improvements in test-time compute efficiency by a factor of 2-4x compared to baselines like best-of-N sampling.
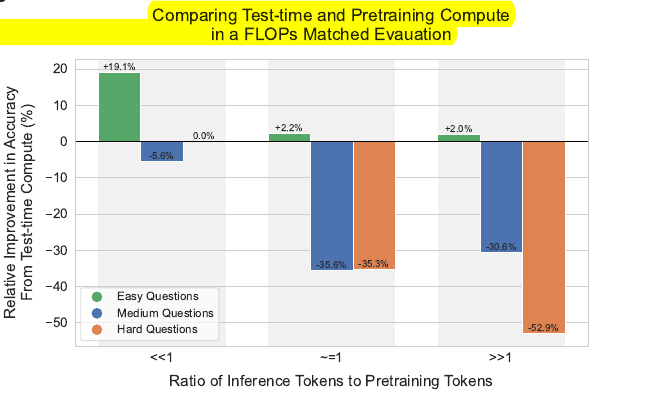
As the inference to pretraining token ratio increases, test-time compute remains preferable on easy questions. Whereas on harder questions, pretraining is preferable in these settings.
[4] Selective Reflection-Tuning: Student-Selected Data Recycling for LLM Instruction-Tuning

📚 https://arxiv.org/abs/2402.10110
The initial Reflection-Tuning approach of 2023 had some fundamental flaws.
So an improved version called "Selective Reflection-Tuning" came (June-2024 ). This approach allows the student model to select which enhanced data from the teacher model is most useful for its training
Original Problem 🔍:
Instruction tuning for LLMs relies heavily on high-quality data, but pre-existing methods often overlook compatibility with the student model being fine-tuned.
Key Insights from this Paper 💡:
• Introduces a teacher-student collaboration pipeline for data improvement
• Proposes Instruction-Following Difficulty score (IFD) and reversed-IFD metrics for evaluating sample difficulty and feasibility
• Demonstrates effectiveness of selective reflection-tuning with fewer training samples
Solution in this Paper 🛠️:
• Selective Instruction Reflection:
Teacher model reflects on and improves instruction
Student model selects based on IFD score (difficulty)
• Selective Response Reflection:
Teacher reflects on and improves response
Student selects based on reversed-IFD score (feasibility)
• Fine-tune student model on resulting high-quality dataset
Results 📊:
• sRecycled WizardLM 13B achieves 85.96% win rate on AlpacaEval
• Outperforms models trained on 125K-774K samples with only ~46K samples
• 926 automatically generated samples rival manually curated datasets
• Improves both Open LLM Leaderboard and AlpacaEval scores
[5] Think Before You Speak

📚 https://arxiv.org/pdf/2310.02226
Delayed token generation with Pauses in pretraining with and finetuning unlock latent Transformer capabilities on diverse tasks. 🤔
Original Problem 🔍:
Transformer-based language models generate tokens in immediate succession, with the (K+1)th token based on K hidden vectors per layer. This imposes an arbitrary computational constraint limiting the number of operations for the next token to the number of tokens seen so far.
Key Insights from this Paper 💡:
• Appending learnable "pause" tokens allows more computation before output
• Training and inference with pauses enables tapping into untapped model capacity
• Benefits emerge when pauses are used in both pretraining and finetuning
• Optimal number of pauses varies by downstream task
Solution in this Paper 🧠:
• Introduce learnable token appended to inputs
• Pause-pretraining: Insert random pauses, ignore loss on predicting pauses
• Pause-finetuning: Append fixed number of pauses to prefixes
• Pause-inference: Append pauses, ignore outputs until last pause
• Evaluate on 1B and 130M parameter decoder-only models
• Test on tasks spanning reasoning, QA, general understanding, and fact recall
Results 📊:
• 1B model shows gains on 8 tasks with pause-pretraining + pause-finetuning:
• 18% EM score increase on SQuAD
• 8% gain on CommonSenseQA
• 1% accuracy gain on GSM8k reasoning task
• Benefits seen when pauses used in both pretraining and finetuning
• Minimal gains when pauses only added during finetuning