
🧠 A New Paper Gives a Brilliant Way To Improve LLMs by Editing Their Context Instead of Their Weights
LLM context-editing, rude prompts outperforming polite ones, AI job loss projections, and a fresh 2025 State of AI report — all in today’s roundup.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (11-Oct-2025):
🧠 A New Paper Gives a Brilliant Way To Improve LLMs by Editing Their Context Instead of Their Weights
💼 A new U.S. Senate report says “AI and automation could replace about 97M to 100M U.S. jobs in 10 years”.
📡 A solid compilations of the State of AI 2025 is published
🛠️ Rude prompts to LLMs consistently lead to better results than polite ones - New Paper finds
🧠 A New Paper Gives a Brilliant Way To Improve LLMs by Editing Their Context Instead of Their Weights

New Stanford + SambaNova + UC Berkeley paper proposes quite a revolutionary idea. 🤯
Proves LLMs can be improved by purely changing the input context, instead of changing weights. Introduces a new method called Agentic Context Engineering (ACE).
It helps language models improve by updating what they read and remember, instead of changing their core weights. It has three parts: a Generator that works on tasks, a Reflector that learns from mistakes, and a Curator that updates the notebook with helpful lessons.
So ACE works like this. The model first tries to solve a task. While doing that, it writes down its reasoning steps, which show what helped and what caused mistakes.
That record is passed to another model, called the Reflector. The Reflector reads it and writes short lessons based on it, such as useful tricks, common errors, or patterns that worked better.
Then another component, the Curator, takes these lessons and turns them into small, clearly written notes called delta items. These are merged into the existing playbook using simple rules. The system does not rewrite the whole context, it only adds or edits these tiny pieces.
Because of this, it keeps all the useful older notes while gradually improving the context with every new task. Over time, the playbook becomes a stronger, richer guide that helps the model perform better on future tasks without retraining or changing weights.
This design avoids full rewrites that can trigger “context collapse”, where a long, useful context shrinks and accuracy drops. Instead, the context grows steadily and stays specific to the domain. ACE, consistently outperforms strong baselines across agent and domain-specific reasoning tasks.

This diagram shows how ACE improves a model’s performance by evolving its context, not its weights.

The process begins when the Generator uses the current playbook (the context) to answer a new query. While solving it, the Generator produces a detailed reasoning trail, called a trajectory. This trajectory records both successes and mistakes.
Next, the Reflector reads that trajectory and analyzes what went right or wrong. It writes short insights or lessons from this reflection. These are not full rewrites but targeted pieces of feedback.
Then, the Curator takes these insights and turns them into small “delta” context items. These deltas are small updates that can be merged into the playbook without erasing older knowledge. The Curator uses simple deterministic logic for this merge, not another LLM.
Once merged, the playbook becomes slightly better and more complete. The system then repeats the loop: each new query uses the improved playbook, produces new traces, reflections, and deltas. Over time, the context keeps growing, getting smarter and more accurate, even though the model’s weights stay fixed.
💼 A new U.S. Senate report says “AI and automation could replace 100M U.S. jobs in 10 years”.
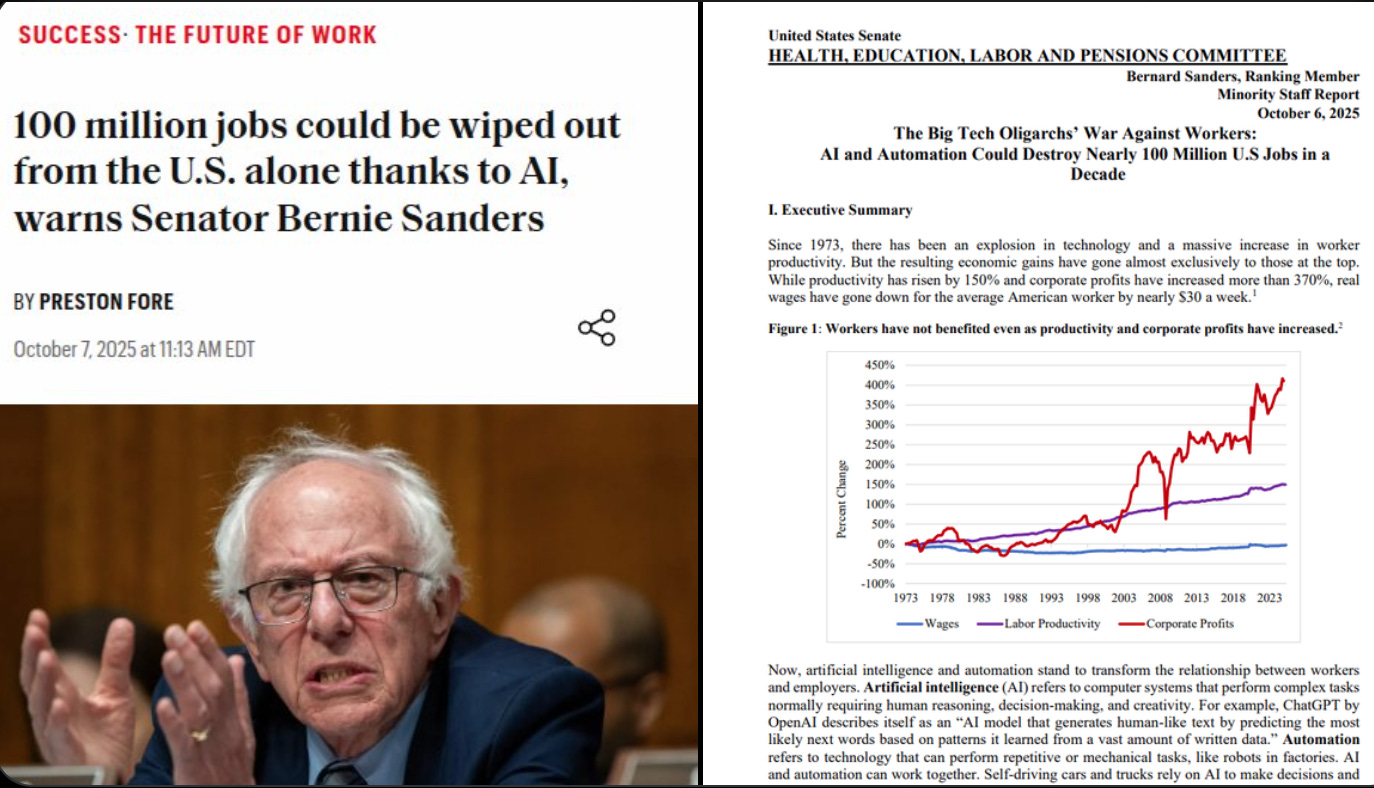
Almost 100M jobs could be lost to AI, automation: Senate report.
With the heaviest hits in fast food, customer support, retail, and logistics.
The analysis uses federal job descriptions and asks a model to rate how much each task could be automated, then scales that task score by how many people hold that job today to estimate displacement.
The headline numbers include 89% of fast food and counter workers, 83% of customer service representatives, 76% of stockers and order fillers, 64% of accountants, 54% of software developers, and 47% of heavy truck drivers at risk of replacement.
The report argues companies are already piloting “artificial labor” and points to corporate materials that sell agent software and self-driving fleets on cost cuts from fewer humans. The core claim is if employers push hard on AI agents and robotics across functions, the displacement wave could outrun normal job churn and even wipe out new roles that might have been created.
The policy section proposes making a 32-hour workweek with no pay cut, profit sharing of 20% stock to workers, worker seats on boards at 45%, stronger unions, and a robot tax, aiming to shift AI gains to labor rather than only to shareholders.
Policy recommendation

📡 A solid compilations of the State of AI 2025 is published
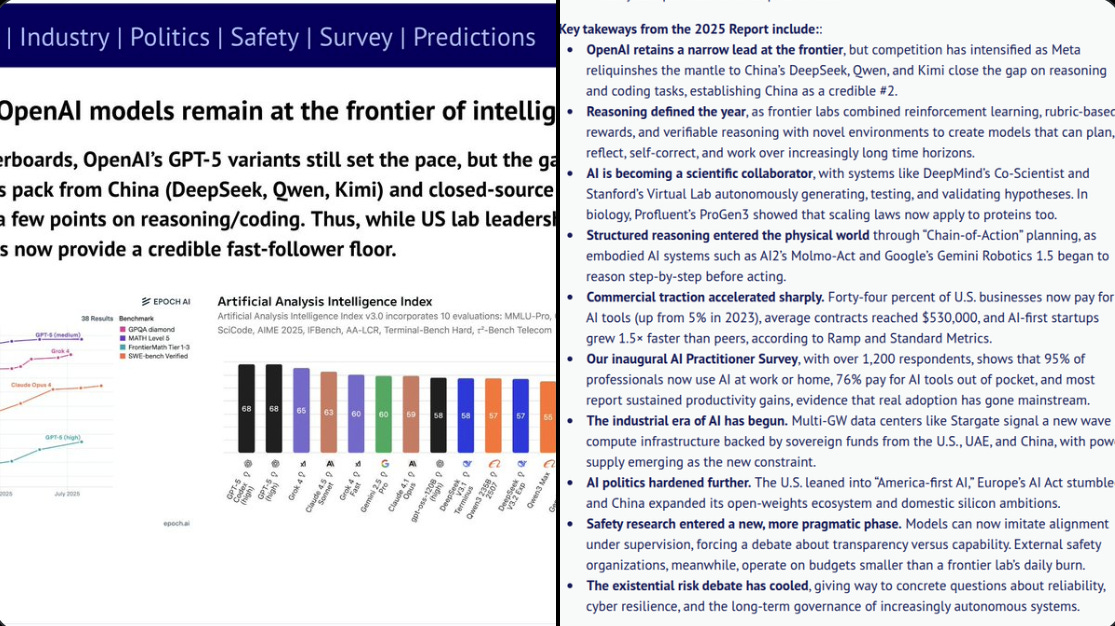
OpenAI remains ahead at the top, but China has real momentum. DeepSeek, Qwen, and Kimi are within a few points on reasoning and coding, and Qwen now powers about 40% of new fine-tunes on Hugging Face, which signals a shift in open-weights leadership.
Reasoning quality improved because labs moved from loose human feedback to rubric based rewards and tasks that can be checked. That change lets models plan, reflect, and correct themselves across longer multi step jobs.
AI is starting to act like a lab partner. DeepMind’s Co-Scientist and Stanford’s Virtual Lab can generate, test, and validate hypotheses, and work like Profluent’s ProGen3 suggests the same scaling playbook is reaching protein design.
Robotics began using step-by-step reasoning before acting, which reduces dumb mistakes in the physical world. Systems like AI2’s Molmo-Act and Google’s Gemini Robotics 1.5 are early examples of this “chain of action” approach.
Tooling is standardizing, which lowers integration friction for teams. Anthropic’s Model Context Protocol is emerging as a common way to plug models into apps and IDEs, though it also introduces new security considerations.
Adoption is finally broad based, not just a lab story. 44% of US businesses now pay for AI, average deals are about $530,000, AI-first startups grow about 1.5x faster, and capability per dollar is doubling every 3 to 6 months, which explains why buyers keep expanding pilots.
as training runs become cheaper per run, labs don’t actually spend less total compute, they just do more runs.
So even though each training run (like DeepSeek’s reported $5,000,000 one) costs less than older models, the lower cost encourages labs to retrain or fine-tune far more often, try more variants, and scale experiments faster. In effect, the total amount of compute used across all experiments still grows. So instead of shrinking global compute demand, it accelerates it.
Politics is shifting toward state backed industrial strategy. The US is taking stakes and exporting an “AI stack” to allies, Europe’s AI Act is stuck in implementation, and China is increasing science funding and leaning into domestic open-weights plus silicon.
Usage looks durable at the individual level too. In a new survey of 1,200 practitioners, 95% use AI at work or home and 76% pay out of pocket, which matches the spend patterns companies report.
🛠️ Rude prompts to LLMs consistently lead to better results than polite ones - New Paper finds

Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy.
The authors found that very polite and polite tones reduced accuracy, while neutral, rude, and very rude tones improved it. Statistical tests confirmed that the differences were significant, not random, across repeated runs.
The top score reported was 84.8% for very rude prompts and the lowest was 80.8% for very polite. They compared their results with earlier studies and noted that older models (like GPT-3.5 and Llama-2) behaved differently, but GPT-4-based models like ChatGPT-4o show this clear reversal where harsh tone works better.
Average accuracy and range across 10 runs for five different tones

A very recent another paper also shows with LLMs, friendly tone consistently underperformed in multi‑turn accuracy, while default and adversarial tones held up better.

The paper tests 3 role-play tones on the same model, default, friendly, and adversarial, then tracks accuracy over 8 follow-ups. Default and adversarial stay close at ~71% average accuracy, while the friendly tone sits lower at ~64% and stays there across rounds.
The authors also note confidence behavior, default mirrors adversarial, while friendly swings more, showing higher sensitivity to follow-up prompts. They suggest the friendly tone can make the model less assertive about correct answers, which increases sways under pressure.

This reduced accuracy is relative to the same question without the polite cue, and this holds when averaging across many models that include GPT-4o and GPT-5. Makes the case that the “be a bit rude or adversarial” strategy can yield better answers than “be very polite,”
The paper builds a 24,160‑prompt benchmark with single‑turn variants that explicitly include a “Politeness” modifier and a separate “Emotional tone” modifier. They test 15 models including GPT‑4o and GPT‑5. In single‑turn evaluation, mean accuracy under “Politeness” drops to 90.8%, which is below the control at 91.5%
And this large benchmark shows that polite language tone towards LLMs, reliably hurts single-turn accuracy, so a non-deferential or firmer stance avoids that penalty.
That’s a wrap for today, see you all tomorrow.