
🧠 A new research explores "The Impact of Artificial Intelligence on Human Thought"
AI reshaping human thought, China’s big research and chip push, Tongyi scaling agents, and Grok-4-fast redefining multimodal reasoning with a 2M context window.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-Sept-2025):
🧠 A new research explores "The Impact of Artificial Intelligence on Human Thought"
🏆 Another DeepSeek moment? This time for Deep Research: China's Tongyi Lab and Alibaba brought Scaling Agents via Continual Pre-training
📡There was major news from China in the AI race this week
🛠️ 🏗️ 🇨🇳 Huawei unveiled plans for its next generation of Ascend AI chips and superclusters, positioning itself against Nvidia.
👨🔧Grok-4-fast, a multimodal reasoning model with a 2M context window that sets a new standard for cost-efficient intelligence.
A new research explores "The Impact of Artificial Intelligence on Human Thought"

AI is shifting real thinking work onto external systems, which boosts convenience but can weaken the effort that builds understanding and judgment. A pattern the paper frames through cognitive offloading and cognitive load theory, and then tracks into social effects like standardized language and biased information flows, and manipulation tactics that target human psychology. It says use AI to cut noise and routine steps, keep humans doing the heavy mental lifting, and add controls because personalization, deepfakes, and opaque models can steer choices at scale.
⚙️ The Core Concepts
Cognitive load theory says working memory is limited, so AI helps when it reduces extraneous load and hurts when it replaces the germane load needed to build skill. In plain terms, let tools clean up the interface and fetch data, but keep people doing the analysis, explanation, and sense‑making.

🧰 Offloading and memory
Handing memory, calculation, or choosing to an external aid frees attention now, yet steady offloading can dull recall and critical habits later. The paper casts web search, note apps, and assistants as a human‑machine transactive memory system, useful when sources are reliable, risky when they are biased or wrong. That is why trust and verification routines matter as much as speed.

🌍 Homogenization risk
Generative systems pull toward dominant styles and references, so writing and framing drift toward Western‑centric patterns and lose local nuance. A study the paper cites shows prompts nudged non‑Western participants to adopt a more Western style, which is the mechanism behind cognitive standardization.

🧪 Critical thinking effects
When answers arrive instantly, people practice evaluation and reasoning less, and the paper reports measurable declines in critical‑thinking scores among heavy users explained by offloading behavior. The punchline is not anti‑tool, it is that over‑delegation breeds standardized critical thinking, where everyone leans on the same shortcuts.

🎯 Targeted persuasion and bubbles
The manipulation chapter shows platforms learning each person’s biases, then tailoring content to fit them, which is why psychological micro‑targeting works. One cited field program hit 40% more clicks and 50% more purchases when ad style matched a user’s traits, then personalization locked users into filter bubbles that reinforce those traits.

🎭 Disinformation and deepfakes
Generative models automate fake text, audio, and video that can look more real than real, and bots then scale the reach of those fakes. The paper walks through cases from election‑season voice scams to wartime videos, making the risk concrete.

🧩 Opaque models
Chapter 6 explains why modern systems are black boxes, they learn billions of parameters, and their internal steps are hard to audit, so trust hinges on process not intuition. That opacity amplifies manipulation risk because people often over‑trust fluent outputs.

🛡️ Practical guardrails
The paper argues for mechanistic checks like verifiable internal logs, weight‑attestation, and split‑knowledge controls, plus human‑facing habits like a cognitive diet that rebuilds skepticism. The goal is simple, keep human autonomy and diversity of thought while still using AI to strip busywork.
In summary:
Use AI to shave off friction, then deliberately keep humans doing analysis, verification, and creative synthesis. Expect personalization and fakes, add process controls and training so teams notice when they are being steered. Treat model outputs as inputs to thinking, not conclusions.
🏆 Another DeepSeek moment? This time for Deep Research: China's Tongyi Lab and Alibaba brought Scaling Agents via Continual Pre-training

The 'DeepSeek' moment for AI agents is here: meet Alibaba's open source Tongyi DeepResearch Agent.
It adds a training step so models act like research agents. Regular fine tuning makes models learn skills and copy demos at once, which clashes.
Every major AI lab is pushing to build agents that can surf the web, use tools, and solve big problems. But the issue is, training has been mixing up reasoning and action learning at the same time, which creates tension.
Think of it like teaching driving by starting with Formula 1. The alternative is to teach the basics of coordination and spatial reasoning first, then advance to high-level racing. This strategy is named “Agentic Continual Pre-training” — giving models the agent mindset before moving them into task-specific learning.
Agentic continual pretraining fixes this problem by teaching behavior with plain next token learning on agent style text. First order action synthesis turns web knowledge into many question types and first step plans without real tool calls.
Higher order action synthesis expands each step with several likely thoughts and actions, so the model practices choices. Training runs in 2 stages, 32K context first, then 128K, which helps long plans.
Built on Qwen3, a 30B base called AgentFounder is then fine tuned on agent trajectories while keeping broad tool use. On public tests it reaches 39.9% on BrowseComp en and 31.5% on HLE (Humanity’s Last Exam), showing strong browsing and reasoning. The idea is learn agent habits first with cheap offline data, then align with demos, which scales with more data and bigger models.
🇨🇳 China tells tech firms to stop buying all of Nvidia's AI chips

The Chinese government instructed Chinese companies to stop buying certain Nvidia AI chips.
Huawei Unveils AI Chip Roadmap to Challenge Nvidia’s Lead
Taken together, the message is clear: China is not desperate for our chips. It is producing its own, and intends to compete globally in the semiconductor market.
Nvidia still has a substantial lead, according to most analysts, but Huawei is using its networking prowess to remain competitive. In particular, Huawei compensates for weaker individual chips by clustering more chips together.
It’s time for Washington to update its assumptions with regard to export controls. American chip companies must be allowed to sell the American technology stack abroad, albeit with security requirements, else we forfeit the AI race to China. If we refuse to do business with a country, we push it into China’s arms.
The question of what we sell China will always be complicated, and there’s room for a wide range of opinions on that. But the question of whether we sell to the rest of the world, especially our friends and allies, should be an easy one.
Excessive bureaucratic delays are a gift for Huawei, which will fill out purchase orders as American companies fill out forms. The hawkish position with respect to China is to help American companies win the AI race, not to help Huawei create a Digital Silk Road.
🇨🇳 Huawei unveiled plans for its next generation of Ascend AI chips and superclusters, positioning itself against Nvidia.

The core idea is straightforward, accept weaker single-chip performance, lean hard on interconnect and memory, and win by packing hundreds of thousands of chips behind fast links and pooled resources.
Huawei’s architecture stacks up as
supercluster → superpod → supernode
Where a supernode is the base building block wired with Ascend cards and custom networking to hide link latency and keep utilization high. The Atlas 950 supernode targets 8,192 Ascend chips per node and a full Atlas 950 SuperCluster with >500,000 chips, then the Atlas 960 step lifts per-node scale to 15,488 chips and a >1,000,000 chip supercluster.
Huawei says the Atlas 950 supernode will be 6.7x the compute of Nvidia’s upcoming NVL144, and it also claims the Atlas 950 SuperCluster reaches 1.3x the compute of xAI’s Colossus, which are bold numbers that will need independent validation. The current bottleneck under U.S. sanctions is single-chip speed because Huawei cannot fab at TSMC, so the company is pouring effort into link bandwidth, collective communication, flow control, congestion avoidance, and topology-aware scheduling to make many slower devices act like one large accelerator.
The near-term roadmap is Ascend 910C (2025), Ascend 950PR/950DT (2026), Ascend 960 (2027), and Ascend 970 (2028), with stated goals to double effective compute with each yearly jump. Ascend 910C is SIMD-centric and peaks around 800 TFLOPS FP16, supports FP32/HF32/FP16/BF16/INT8, has 784 GB/s chip-to-chip interconnect, 128 GB HBM, and 3.2 TB/s memory bandwidth.
Ascend 950PR/DT moves to a mixed SIMD/SIMT approach, targets 1 PFLOPS FP8 and 2 PFLOPS FP4, raises interconnect to about 2 TB/s, and ships with 144 GB at 4 TB/s on 950PR or 128 GB at 1.6 TB/s on 950DT. Ascend 960 aims for 2 PFLOPS FP8 and 4 PFLOPS FP4, around 2.2 TB/s interconnect, and jumps to 288 GB HBM with 9.6 TB/s bandwidth to keep tensors fed at scale.
Ascend 970 pushes to 4 PFLOPS FP8 and 8 PFLOPS FP4, around 4 TB/s interconnect, keeps 288 GB capacity but increases HBM bandwidth to 14.4 TB/s to relieve attention and MoE communication pressure. From 950PR onward Huawei plans self-developed High Bandwidth Memory, branded HiBL 1.0 and HiZQ 2.0, which reduces exposure to external memory vendors and lets packaging and signaling co-evolve with the interconnect roadmap.
Against that, Nvidia’s Blackwell Ultra GB300 is still stronger per chip at about 15 PFLOPS FP4 with 288 GB HBM3e and roughly 8 TB/s memory bandwidth, so Huawei’s bet is that fabric scale and scheduling can outweigh per-device gaps in dense training runs. The company’s system framing matters here, a supercluster is the top domain where many superpods share a global scheduler and memory-tiering layer, each superpod groups multiple supernodes under a high-radix fabric, and each supernode presents a single logical device to the software stack to hide cross-card hops.
Training stacks need this to work, so Huawei’s compiler, graph partitioner, and collective libraries must fuse operators across cards, pre-place parameters for sharded optimizers, and adapt routes on the fly when hotspots or failures appear. Huawei cites CloudMatrix 384 supernodes already deployed >300 times across >20 customers, which suggests the software side is at least mature enough for telecom, manufacturing, and generic model training workloads.
The TaiShan 950 SuperPoD extends the idea beyond AI into general compute using Kunpeng processors with up to 16 nodes, 32 processors, and 48 TB memory plus pooled storage and DPU offload, effectively pitching a replacement for classic mainframes with modern resource disaggregation. The Atlas product names can be confusing, but the clean mental model is this, Atlas 950/960 are AI accelerator supernodes focused on tensor compute, while TaiShan 950 is a CPU-centric supernode aimed at wide enterprise workloads with memory and I/O pooling.
The networking physics is the make-or-break, because to keep thousands of devices above 70% utilization, the topology, link speed, and scheduling must match the parallelism plan for data, tensor, and pipeline splits without drowning in all-reduce and all-to-all overhead. The memory plan is just as central, with >9 TB/s and then >14 TB/s per device on the 960 and 970 generations, activation checkpointing stays cheaper, expert routing stays fed, and sequence lengths can grow without constant rematerialization.
Power and cooling are the quiet constraints, since a >500,000 card build implies data-hall scale liquid cooling, high-voltage distribution, and recovery plans for partial failures so a single rack drop does not stall a world-scale training run. Software portability will be watched closely, because large Chinese stacks typically need compatibility with PyTorch frontends, standard kernels, and popular optimizers, or else teams must rewrite training code for custom compilers and runtime APIs.
If the claims against Nvidia’s NVL144 and xAI’s Colossus hold in practice, then the largest Chinese clouds can keep scaling frontier training onshore without direct access to top U.S. silicon, at least for workloads that parallelize well across thousands of relatively smaller chips. Nvidia still holds an edge in single-chip speed, mature libraries, ecosystem depth, and proven scale on frontier runs, so real-world parity depends on whether Huawei’s fabric and compiler keep utilization high across messy, stateful training jobs.
The live market backdrop helps Huawei, with regulatory heat on Nvidia in China and reported pauses on certain product tests, which raises the value of a credible domestic path to frontier compute. The bottom line, treat Huawei’s plan as a system-first design where the “GPU” is now the supernode and code needs to be written and profiled with that logical device in mind.
Xu Zhijun, Huawei's Rotating Chairman and Deputy Chairman said:
“Because of U.S. sanctions, we cannot manufacture our chips at TSMC, so our single-chip performance still lags behind NVIDIA. But Huawei has more than thirty years of experience in connecting people and machines. By heavily investing in interconnect technology, we’ve made breakthroughs that allow us to build super-nodes with tens of thousands of cards. This gives us the ability to deliver the most powerful compute in the world—at the system level.”

👨🔧 xAI releases Grok 4 Fast, a multimodal reasoning model with a 2M context window that sets a new standard for cost-efficient intelligence.

Grok 4 Fast sets a new frontier in cost-efficient intelligence, outperforming Grok 3 Mini across reasoning benchmarks while slashing token costs.
Key Numbers of
40% fewer reasoning tokens used, same accuracy
98% lower compute compared to Grok 4
Multimodal input: text and images supported
Has built-in browsing and code execution
Works in Fast and Auto modes across platforms
Processes 2M-token context windows
Benchmarks
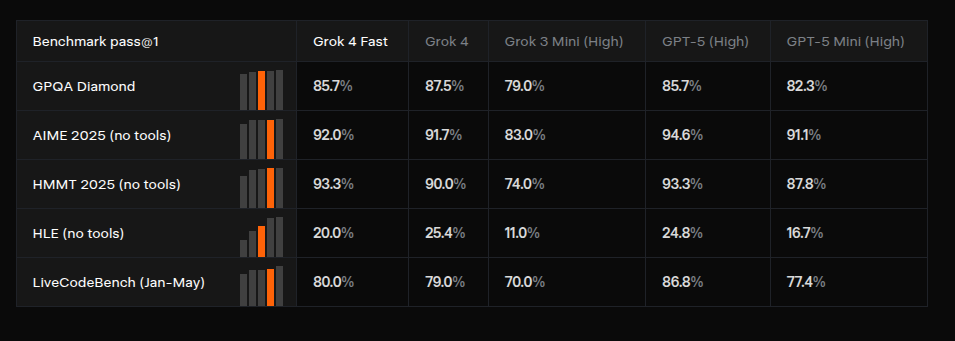
Most top models need heavy compute, but Grok 4 Fast matches their performance with 40% fewer thinking tokens. It scores 85.7% on GPQA Diamond for science and 92% on AIME 2025 in math. It’s also ranked #1 in LMArena’s Search Arena. On coding, it even outperforms the larger Grok 4, and it tops Claude 4.1 Opus and Gemini 2.5 Pro in several benchmarks.
Its doing brilliantly on Arena Learderboard.
🏆 #1 on the Search
💠 Tied for #8 on the Text
Under the hood
Grok 4 Fast cuts down on thinking tokens without losing reasoning quality, which drives compute costs lower. Inference steps are streamlined for faster, cheaper responses. Accuracy stays intact by improving reasoning chains instead of just throwing more tokens at the problem. Plus, it taps into xAI’s tool integrations like browsing and code execution for multi-step reasoning.
Showing the capabilities a smaller model can reach when given strong tools. Its also super efficient, uses about 40% fewer "thinking tokens" on average compared to the standard Grok 4, without sacrificing much accuracy. It's available for free to all users (including non-subscribers) on grok[.]com, the X iOS/Android apps (in Fast or Auto modes), and temporarily on platforms like OpenRouter and Vercel AI Gateway.
Pricing and Availability
Free access is available on grok.com, grok.x.com, plus iOS and Android apps. It’s also free for a limited period on OpenRouter and Vercel AI Gateway. API pricing is set at $0.20 per 1M input tokens and $0.50 per 1M output tokens.
That’s a wrap for today, see you all tomorrow.