
A Primer on the Inner Workings of Transformer-based Language Models
Ever wondered how LLMs think? It's all circuits and patterns Nice Paper for a long weekend read - "A Primer on the Inner Workings of Transformer-based Language Models"

Ever wondered how LLMs think? It's all circuits and patterns
Nice Paper for a long weekend read - "A Primer on the Inner Workings of Transformer-based Language Models"
📌 Provides a concise intro focusing on the generative decoder-only architecture.
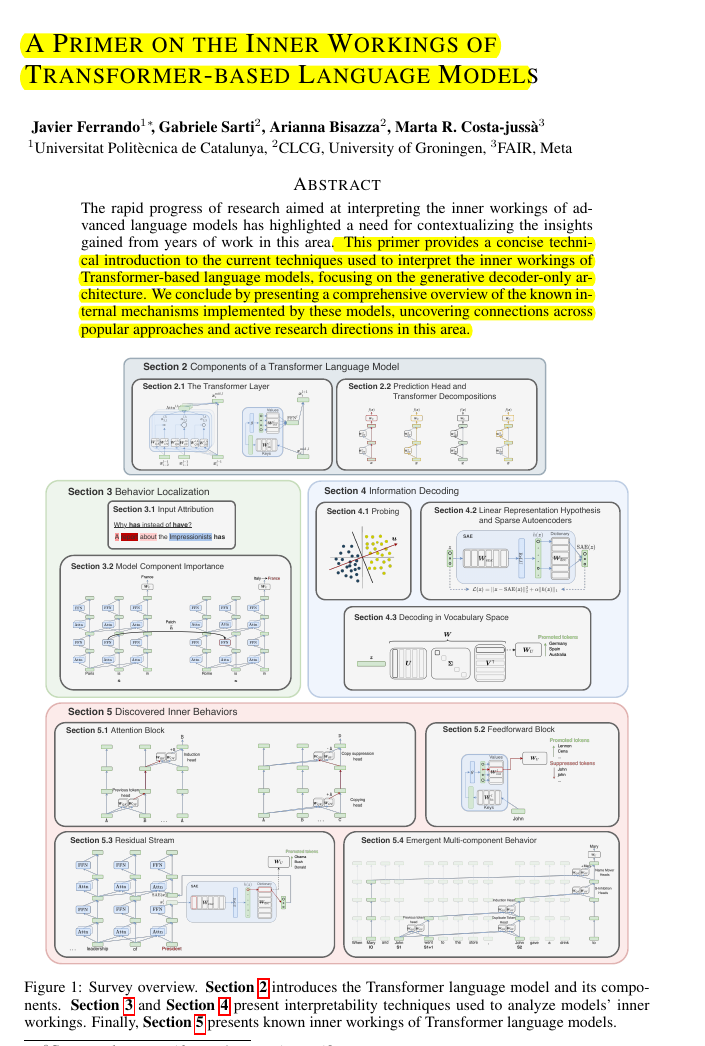
📌 Introduces the Transformer layer components, including the attention block (QK and OV circuits) and feedforward network block, and explains the residual stream perspective. It then categorizes LM interpretability approaches into two dimensions: localizing inputs or model components responsible for a prediction (behavior localization) and decoding information stored in learned representations to understand its usage across network components (information decoding).
📌 For behavior localization, the paper covers input attribution methods (gradient-based, perturbation-based, context mixing) and model component importance techniques (logit attribution, causal interventions, circuits analysis). Causal interventions involve patching activations during the forward pass to estimate component influence, while circuits analysis aims to reverse-engineer neural networks into human-understandable algorithms by uncovering subsets of model components interacting together to solve a task.
📌 Information decoding methods aim to understand what features are represented in the network. Probing trains supervised models to predict input properties from representations, while the linear representation hypothesis states that features are encoded as linear subspaces. Sparse autoencoders (SAEs) can disentangle superimposed features by learning overcomplete feature bases. Decoding in vocabulary space involves projecting intermediate representations and model weights using the unembedding matrix.
📌 Then summarizes discovered inner behaviors in Transformers, including interpretable attention patterns (positional, subword joiner, syntactic heads) and circuits (copying, induction, copy suppression, successor heads), neuron input/output behaviors (concept-specific, language-specific neurons), and the high-level structure mirroring sensory/motor neurons. Emergent multi-component behaviors are exemplified by the IOI task circuit in GPT2-Small. Insights on factuality and hallucinations highlight the competition between grounded and memorized recall mechanisms.