
AI Paper Explained - "Schrodinger’S Memory: Large Language Models"
Proposes that LLMs' memory operates like "Schrödinger's memory," observable only when queried.


Memory plays a foundational role in human intelligence, enabling everything from daily routines to complex problem-solving.
Large Language Models (LLMs) mimic this ability by generating outputs based on input cues, but do they truly possess "memory"? This question drives the paper's discussion, leading to the concept of "Schrödinger’s memory," where memory remains unobservable until triggered by a specific query.
We call this ”Schrödinger’s memory” because we can only determine whether the LLM has this memory by asking it and analyzing its response; otherwise, the memory remains indeterminate.
Key Insights from this Paper 💡:
LLMs can dynamically approximate functions, exhibiting a form of memory.
Memory in LLMs is not static but inferred from input cues.
Longer texts challenge LLMs' memory capacity.
Human and LLM memories share dynamic response mechanisms.
Key Proposals: Universal Approximation Theorem (UAT) and Memory in LLMs
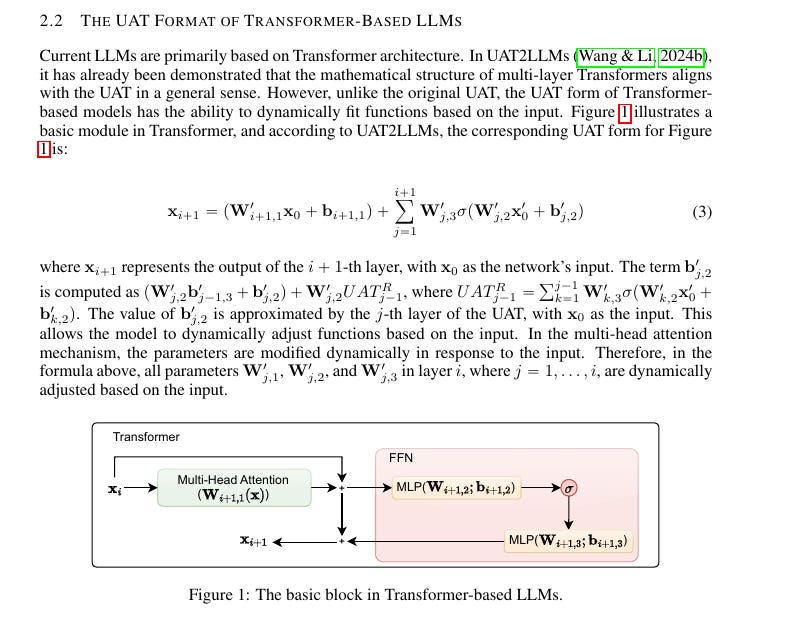
Unlike simple feedforward neural networks, Transformers use multi-head attention and feedforward layers to continuously recalibrate relationships between different parts of the input. This dynamic recalibration enables the model to fit inputs to outputs in a contextually relevant way, effectively mimicking memory.
The paper extends the UAT to explain that each layer in a Transformer dynamically adjusts the approximation function based on the input. The weights and attention mechanisms change depending on the specific prompt, making the "memory" adaptive rather than static.
The Universal Approximation Theorem (UAT) asserts that neural networks can approximate any continuous function with enough layers and parameters. This means they can "fit" any data pattern they’ve encountered, including mapping input prompts to appropriate outputs. In LLMs based on Transformers, this approximation capability is not static—it dynamically adjusts based on new inputs.
Transformers refine the basic UAT by introducing mechanisms like multi-head attention and feedforward layers. Each Transformer layer "recalculates" relationships between inputs to create contextually relevant outputs. The paper argues that this dynamic fitting behavior forms the backbone of LLM memory.
Memory vs. Retrieval: Core Differences from Human Memory
The authors compare LLM memory to "Schrödinger’s cat," where the memory state is indeterminate until it’s probed. In human memory, we often perceive recall as retrieving static information. However, even in humans, memory is a reconstructive process influenced by context and prior associations.
LLMs parallel this by reconstructing answers on the fly rather than pulling pre-stored content. This behavior makes it difficult to classify LLM outputs as pure retrieval or inference—it’s often a mix of both.
The model's "knowledge" only becomes observable when a prompt aligns closely with a learned approximation. Without the input, we cannot know what the model "remembers" or how accurate its recall will be.
Understanding the Concept of "Schrödinger's Memory"
The paper compares LLM memory to "Schrödinger’s cat"—a concept from quantum physics where the cat in the box is both alive and dead until observed. Similarly, an LLM’s memory for a piece of information is indeterminate until we prompt it with a relevant query.
Memory depends on the input. The model doesn’t explicitly store sentences like "Newton’s first law" in a specific neuron or weight. Instead, when queried, the LLM reconstructs the answer dynamically based on learned patterns. This reconstruction process makes it seem like the model "remembers" the answer.
Experimental Setup: Evaluating LLM Memory
The authors tested LLM memory by training models on poetry datasets—Chinese poems (CN Poems) and English poems (ENG Poems). For each poem, the inputs included metadata like the author and title, while the output was the poem text itself.
After training, when prompted with only the author and title, the LLMs reproduced entire poems. High accuracy indicated strong memory retention. For instance, larger models like Qwen2-1.5B-Instruct recalled over 96% of the poems, showing that model size influences memory precision.
Memory Mechanism in Transformers
Transformers use multi-layer feedforward neural networks to approximate input-output relationships. In UAT terms, this approximation is expressed as a function of weights, biases, and activation functions.
A key feature is the attention mechanism, which assigns different weights to different parts of the input. When reconstructing an answer, the model dynamically decides which input tokens are most relevant. This dynamic adjustment makes the "memory" flexible and dependent on input cues.
Impact of Input Length on Memory
The study found that longer inputs challenge memory capabilities. For Chinese poems, increasing the input length from 256 to 512 characters reduced recall accuracy significantly.
Human vs. LLM Memory: Parallels and Differences
Human memory is not a static storage unit; it reconstructs memories dynamically, often filling gaps with context. Similarly, LLMs generate outputs by approximating patterns, not retrieving static records.
Both systems rely on a "fitting" process. In the human brain, the hippocampus helps update long-term memory weights. In LLMs, the parameters across attention heads and layers act as "learned weights" that adapt based on inputs.
Conclusion
This paper highlights that LLMs don’t "store" memories like a database. Instead, they approximate learned outputs dynamically, fitting responses to queries based on prior training. By framing memory as a dynamic process, the authors show that LLM memory can be remarkably human-like, yet its precision depends on factors like model size, data quality, and input length.