
Ai2’s Olmo 3 family challenges Qwen and Llama with efficient, open reasoning and customization
Olmo 3 challenges top open models, Google stirs things up, Cursor upgrades debugging, China stumbles on ASML clone, and Figure AI faces whistleblower lawsuit.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-Nov-2025):
🏆 Ai2 releases Olmo 3 open models, rivaling Meta, DeepSeek and others on performance and efficiency
🚨 Figure AI sued by whistleblower who warned that it’s robots could ‘fracture a human skull’
🛠️ The newest Cursor release now lets users plan interactively and catch bugs directly while coding in the editor
🛠️ OPINION: 🇨🇳 Reverse-engineering ASML isn’t going great for China, engineers allegedly broke the machine trying.
👨🔧 Google’s is shaking things up massively now.
🏆 Ai2 releases Olmo 3 open models, rivaling Meta, DeepSeek and others on performance and efficiency
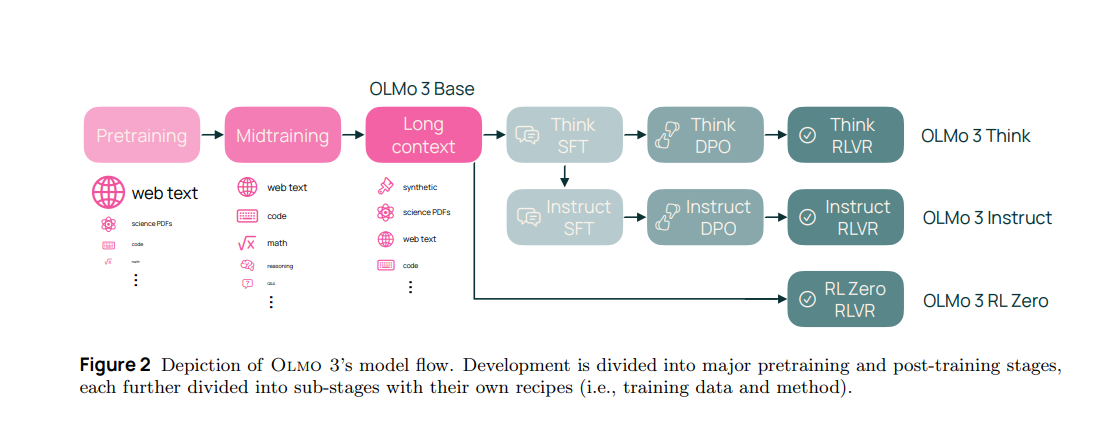
Olmo 3 is a new fully open language model family that not only pushes 7B and 32B model quality, but also exposes the full training pipeline so people can actually study and modify how the models were built. Read the tech report.
Olmo 3 sits on 3 main tracks built from the same base models, Olmo 3 Base (7B, 32B) for general capability, Olmo 3 Think (7B, 32B) for long, explicit reasoning traces, and Olmo 3 Instruct (7B) for fast chat and tool use, plus an Olmo 3 RLZero (7B) branch focused on reinforcement learning research.
The company said Olmo 3- Think is the “first-ever fully open 32B thinking model that generates explicit reasoning-chain-style content.” Olmo-3 Think also has a long context window of 65,000 tokens, perfect for longer-running agentic projects or reasoning over longer documents.
Base training runs in 3 stages, first broad pretraining over mixed web, code, math and science, then a mid training phase that concentrates on harder math, code and reading data, then a long context phase that teaches the model to handle sequences up to about 65K tokens.
On benchmarks, Olmo 3 Base 32B beats other fully open bases like Marin 32B with gains such as GSM8K 80.5 vs 69.1 and HumanEval 66.5 vs 52.3, while staying competitive with top open weight models like Qwen and Gemma at similar size.
Olmo 3 Think 32B converts the base into a reasoning model using a pipeline of supervised reasoning data, direct preference optimization and reinforcement learning with verifiable rewards, reaching MATH 96.1, strong AIME scores, and HumanEvalPlus 91.4, close to or ahead of Qwen 3 32B reasoning models while using about 6x fewer training tokens.
Olmo 3 Instruct 7B targets short, efficient replies for chat and tools, often matching or beating Qwen 2.5, Gemma 3 and Llama 3.1 on math and instruction following, while keeping a small, fully open footprint.
Underneath, Olmo 3 trains on the new Dolma 3 corpus of about 9.3T tokens, with a 6T Dolma 3 Mix, a 100B token Dolma 3 Dolmino mid training mix, and a 50B token Dolma 3 Longmino long context mix, plus the Dolci post training suite for SFT, DPO and RL data.
The team also optimized the training stack on up to 1,024 H100 GPUs, getting SFT throughput improvements of about 8x and RL training about 4x faster through continuous batching, better threading and in flight weight updates.
A key difference from most releases is that Olmo 3 ships full checkpoints at each stage, all training and post training datasets, and a tooling stack (Olmo Core, Open Instruct, datamap rs, duplodocus, OLMES and decon) plus OlmoTrace to map outputs back to training data, so researchers can actually run ablations and debug behaviors rather than treat the model as a black box.
🚨 Figure AI sued by whistleblower who warned that it’s robots could ‘fracture a human skull’

The lawsuit claims Figure AI rushed its humanoid robots toward home use, ignored serious safety warnings, and then fired its Head of Product Safety after he kept pushing for fixes. Robert Gruendel, a robot safety engineer with 20 years in the field, says he joined in 10-24 to build safety processes but soon saw powerful robots moving near people without solid procedures or incident tracking.
In the lawsuit he says the robot could hit hard enough to fracture a human skull and had already punched a stainless steel fridge, cutting a roughly 0.25 inch gash during a malfunction. He says tests showed forces over 20 times typical human pain levels and describes robots that moved unpredictably within a couple of feet of workers, nearly kicking someone in the head.
According to the filing, leaders downgraded or removed safeguards such as certified emergency stop hardware and a physical safety feature dropped because an engineer disliked its look, which he argues shows style and speed winning over risk reduction. He also claims Figure pitched investors an ambitious safety roadmap, then weakened it after closing over $1 billion in funding. Figure says he was fired for poor performance and will contest his story, but the allegations underline how hard it is to make full strength humanoids safe around untrained people and how crucial real safety engineering is.
🛠️ The newest Cursor release now lets users plan interactively and catch bugs directly while coding in the editor
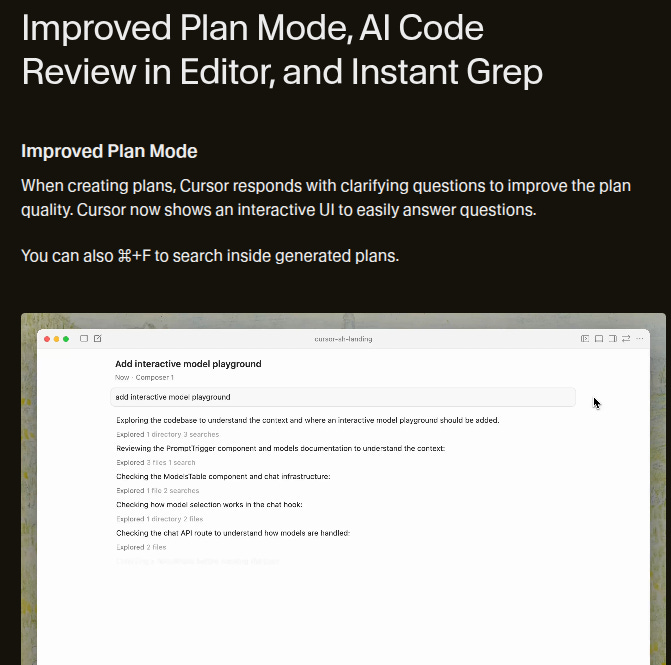
Cursor 2.1 adds interactive planning, in editor AI code reviews, and instant grep so the agent can understand changes better and move through large codebases with less friction.
Plan Mode now asks clarifying questions, shows an interactive UI for answers, and lets you search inside plans, so edits start from a concrete description instead of a vague prompt.
AI code reviews in editor scan your local diffs for likely bugs or risky patterns, list issues in a side panel that jumps to the right lines, and complement Bugbot’s pull request checks on GitHub and GitLab by catching problems before you push.
Instant grep gives near zero wait text search for the agent and the sidebar, supports regex and word boundary filters across all Cursor models, and is rolling out to 2.1 users so big repo navigation feels less sluggish.
Together these changes make Cursor a stronger everyday assistant because planning, review, and search now live as fast, first class flows inside the editor instead of fragile prompts in a separate chat window.
🛠️ OPINION: 🇨🇳 Reverse-engineering ASML isn’t going great for China, engineers allegedly broke the machine trying

Multiple news outlets reported , Chinese engineers broke an ASML deep ultraviolet (DUV) lithography machine while trying to reverse-engineer it, then called ASML for repairs under the guise of a malfunction.
Whats stopping China to create their own photolithography machines to create their own chips?
Simply because Its ultra HARD. China has some of the brightest minds in the world working on it, its just really hard. Lithography is a symphony of optics, lasers, motion systems, firmware, and environmental control. Even if one could disassemble a DUV machine, rebuilding it to production-grade precision requires the calibration routines, licensed software, and deep-supply cooperation that only ASML and its verified partners maintain. This is the unseen side of mastery, the part that can’t be reverse-engineered overnight.
🔧 The 193nm immersion is unforgivingly HARD
An immersion DUV scanner runs 193nm light through a thin water layer and scans wafers on dual‑stage mechanics to keep overlay tight across 300mm wafers. That whole stack depends on factory procedures, internal references, and closed‑loop tuning of stages, optics, and sensors. ASML’s public product notes on immersion and TWINSCAN stages show how much precision is baked into the platform, including metrology frames that tie projection optics and sensors to a single reference point.
Pulling a tool apart risks particle hits on ZEISS projection optics, interferometer offsets, and loss of those references, and putting it back requires vendor procedures and software keys that sit behind service licensing.
The closest thing to an ASML rival are the Japanese companies Canon and Nikon, but they have pretty much conceded the cutting edge high end part of the field to ASML.
🏭 China’s plan B, stretch DUV (Deep Ultraviolet) lithography) and stand up domestic tools
SMIC, the Chinese foundry company is trialing a domestic immersion DUV from Yuliangsheng that targets 28nm and aims at 7nm via multi-patterning. Reporting pegs broader fab use around 2027, with performance closer to older ASML gear, so tuning and yield lift will take time.
China could catch up eventually. But EUV technology quite literally took billions of dollars of direct financial assistance from the US and Dutch government to complete. You can use Japan as an example. They were competing with the Dutch to make EUV in the 2000s. It ultimately failed as they couldn’t commit sufficient consistent funding without the US. And Japan was the world leader in photolithography at the time.
EUV (Extreme Ultraviolet), as far as the actual wavelength of light goes, is pretty damn close to the physical limits of photolithography. We’ll get incremental improvements but we’re not likely to see anything like the shift from DUV to EUV again. But then again, who knows. When we first investigated EUV for photolithography in the 80’s we didn’t think it would be possible.
🚫 The export rules that drive this behavior
The Netherlands revoked licenses covering shipments of NXT:2050i and NXT:2100i to China from 1‑Jan‑2024.
In Sep‑2024, The Netherlands tightened things again so NXT:1970i and NXT:1980i shipments need Dutch licenses too, with NXT:2000i and newer already under Dutch control.
Even Servicing is also gated, since spare parts and software updates for certain China tools require a Dutch license
👨🔧 Google’s is shaking things up massively now.

A new ‘The Information’ article went viral which talks about OpenAI CEO Sam Altman’s big warning to employees in his leaked memo: ‘Google has been doing excellent...’
Sam Altman just admitted Google caught them slipping. “Economic headwinds” is CEO-speak for: we’re not winning right now. Google shipped something that spooked OpenAI enough to brief the board on it. This isn’t theoretical competition. It’s affecting hiring, pricing, and product roadmaps starting now.
OpenAI built a moat on first-mover advantage. Google just proved that moat erodes fast in AI.
Google absolutely dominate the distribution of AI, because it can bundle Gemini into Search, Android, and Workspace, which accelerates usage with near-zero marginal distribution cost.
Usage signals show Gemini app at ~650M MAU, while ChatGPT still leads with ~800M weekly actives.
Unit economics for sure will tilt toward Google since TPU fleets can avoid Nvidia premium pricing, improving $ per token for training and inference.
Strategically, Altman’s “superintelligence” push by doubling down on frontier capability is the only way it can comepte with Google. Because it can not comete with Google on price, scale, and platform reach.
That’s a wrap for today, see you all tomorrow.