
🇨🇳 Alibaba unveils new Qwen3.5 model for ‘agentic AI era’, Qwen3.5-397B-A17B. Apache 2.0 license
Qwen3.5-397B-A17B for agentic AI under Apache 2.0, a Chinese 3B LLM beats Qwen, Seedance 3.0 nears final sprint, and Pentagon pressures labs over military guardrails.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (16-Feb-2026):
🇨🇳 Alibaba unveils new Qwen3.5 model for ‘agentic AI era’, Qwen3.5-397B-A17B. Apache 2.0 license
🇨🇳 A recruiting platform in China trained a 3B parameter LLM that outperformed Qwen.
🚨 Big rumor around Seedance 3.0 is that it’s entered a closed-door “final sprint” phase, with multiple disruptive breakthroughs supposedly landing back-to-back.
🗞️ The U.S. Pentagon is pressuring top AI labs to let the military use their models for “all lawful purposes,” and a dispute over guardrails has reportedly put Anthropic at risk of being cut off.
🇨🇳 Alibaba unveils new Qwen3.5 model for ‘agentic AI era’, Qwen3.5-397B-A17B. Apache 2.0 license

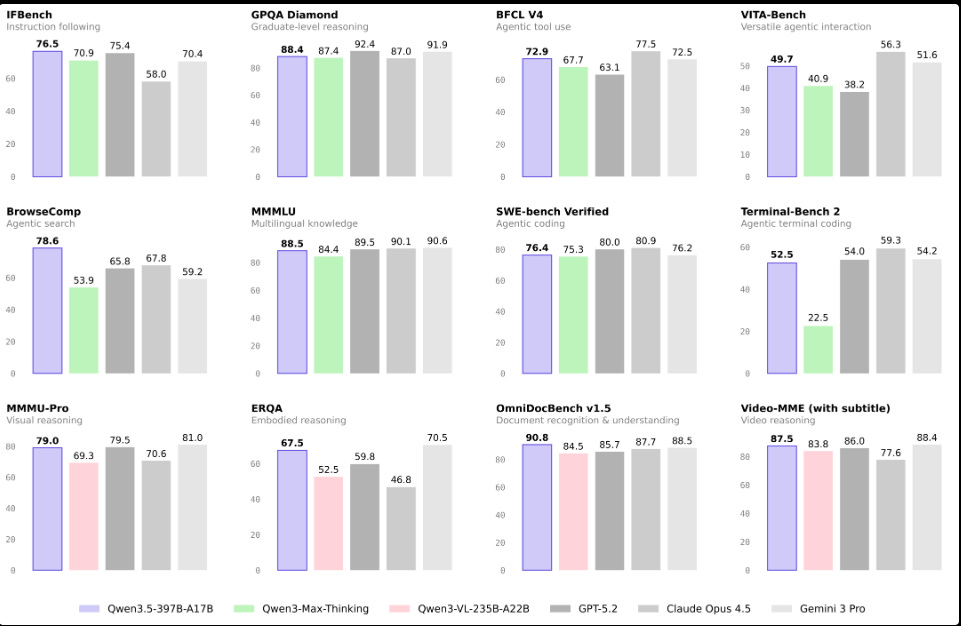
8.6x higher decode throughput than Qwen3-Max at 32K context and 19.0x at 256K, while also being 3.5x and 7.2x faster than Qwen3-235B-A22B at those same lengths.
On quality, it reports IFBench 76.5 for instruction following, BFCL v4 72.9 for tool-call correctness, AIME26 91.3 for contest math accuracy, and SWE-bench Verified 76.4 for fixing real coding tasks.
Most of the claimed jump over Qwen3 comes from scaling reinforcement learning across many harder, tool-using, multi-turn environments rather than tuning for a narrow benchmark.
Older long-context models bog down because standard attention has to compare every token to many other tokens, so memory and compute rise fast as context gets longer.
Agent post-training also gets brittle when reinforcement learning runs in a small set of environments, since the model can memorize patterns instead of learning robust tool habits.
Qwen3.5 reduces the long-context bottleneck by mixing linear attention, via Gated DeltaNet, with regular attention layers so memory growth is better controlled at very long lengths.
For multimodality it uses early fusion, meaning text and visual tokens are processed together in 1 native stack instead of stitching a vision encoder onto a language model.
They also announced Qwen3.5-Plus, which is the managed, hosted API version of Qwen3.5-397B-A17B on Alibaba Cloud Model Studio, positioned for people who want the same core model without running multi-GPU inference themselves.
It ships with a 1M token context window by default, which is larger than the open-weight checkpoint’s typical long-context setups in most self-hosted stacks.
It also comes with “official built-in tools” and “adaptive tool use,” meaning the service can expose tool capabilities and handle when to call them in a more production-oriented way than a raw weights deployment.
On the API side, Alibaba documents OpenAI-compatible Chat Completions, plus an OpenAI Responses-style interface that includes built-in tools like web search, a code interpreter, and a web extractor, with the service managing conversation state so clients do less bookkeeping.
The release comes as Alibaba looks to attract more users to its Qwen chatbot app in China, a landscape currently dominated by rival tech giant ByteDance’s Doubao and DeepSeek
One of the key strengths behind its efficiency is Hybrid attention.
They do not run full softmax attention in every layer, they mix a linear attention layer called Gated DeltaNet with a smaller number of attention layers that behave more like regular attention but with an extra learned gate on the output.
The specialty is that Gated DeltaNet can update a compact running “state” as tokens stream in, so compute and memory grow roughly linearly with context length instead of blowing up the way full attention does when it has to compare each new token against a huge key value cache.
The reason they still keep some attention style layers is that full attention is good at sharp retrieval, like grabbing a specific earlier detail exactly, while linear state models can smear or forget fine-grained facts when the context is very long.
The “gated attention” part is basically attention plus a learned valve that can downweight or zero out parts of a layer’s output, which helps stability and lets the model decide how much new context mixing it really wants at that depth.
🇨🇳 A recruiting platform in China trained a 3B parameter LLM that outperformed Qwen.

Nanbeige LLM Lab released the open-weight Nanbeige4.1-3B, Apache 2.0 license.
73.2 on Arena-Hard-V2 and 52.21 on Multi-Challenge, which are chat preference stress tests built to be hard for small models.
On deep-search agent benchmarks it reports 69.90 on GAIA and 75.00 on xBench-DeepSearch-05, while Qwen3-4B-2507 is shown at 28.33 and 34.00 on those same tasks.
Supports context lengths of up to 256k tokens, enabling deep-search with hundreds of tool calls, as well as 100k+ token single-pass reasoning for complex problems
On real submissions to LeetCode Weekly Contests 484–488 it reports an 85.0% pass rate, versus 55.0% for Qwen3-4B-2507 and 50.0% for Qwen3-32B in the same setup.
The core recipe is an upgraded supervised fine-tuning (SFT) mix plus 2 reinforcement learning stages, first point-wise scoring and then pair-wise comparisons to sharpen win or loss boundaries.
In point-wise reinforcement learning, a reward model scores 8 sampled answers per prompt and the model is optimized with GRPO, which the report ties to fewer repetitive or malformed outputs.
In pair-wise reinforcement learning, a second reward model learns from strong versus weak response pairs with a swap-consistency regularizer, then trains on a binary better or worse signal.
🚨 Big rumor around Seedance 3.0 is that it’s entered a closed-door “final sprint” phase, with multiple disruptive breakthroughs supposedly landing back-to-back.

According to the rumor:
1. Seedance 3.0 will be able to produce a full-length feature film from a single prompt instead of 5- to 20-second clips. Internal tests reportedly hit 18 minutes without noticeable collapse.
A “narrative memory chain” keeps plot, character traits, and world details consistent across multi-act story arcs and multi-shot transitions.
2. Native multilingual, emotion-aware dubbing. Video and dialogue are generated together, not added later. It outputs lip-synced speech in Chinese, English, Japanese, Korean, and more, and modulates delivery like tone, breathing, laughing, crying based on character emotion.
3. Director-style control at shot level. Storyboard text works directly, for example Shot 1 wide dolly push, Shot 2 fast-cut chase, and it executes camera language and cut structure in real time. Built-in grading presets include IMAX-style, film look, Netflix-style, with 1-click export.
4. 8x cheaper per minute. Distillation plus inference optimization reportedly drops compute cost to 1/8 of Seedance 2.0 for 1 minute of cinematic output, down to a few hundredths of the cost of a traditional crew scene.
🗞️ The U.S. Pentagon is pressuring top AI labs to let the military use their models for “all lawful purposes,” and a dispute over guardrails has reportedly put Anthropic at risk of being cut off.

Anthropic is holding firm on 2 hard limits, no fully autonomous weapons and no mass domestic surveillance of Americans, and it says government discussions so far were about usage policy boundaries, not specific operations. From the Pentagon side, the problem is operational reliability, because if a model refuses a request mid-task, the military either has to renegotiate edge cases or swap systems under pressure.
The dispute matters because Claude was reportedly the 1st frontier model brought onto Pentagon classified networks, and per Axios Anthropic’s Pentagon contract was valued up to $200M. Reuters also reported the Pentagon has been pushing AI companies to run tools on classified “secret” networks without many standard user-facing restrictions.
U.S. operation involving Venezuela’s Nicolás Maduro, where Wall Street Journal reported Claude was used via Anthropic’s partnership with Palantir, and Anthropic denies policing specific operations. OpenAI, Google, and xAI are also in talks, with their tools already used in unclassified settings, and the Pentagon is trying to extend “all lawful purposes” into both unclassified and classified work.
That’s a wrap for today, see you all tomorrow.