
🇨🇳 Alibaba’s cracked “Qwen Team” open-sourced 20B param Qwen-Image
China’s Qwen-Image goes public, NVIDIA vs Huawei in the global GPU arms race


Read time: 13 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (4-Aug-2025):
🇨🇳 Alibaba’s cracked “Qwen Team” open-sourced Qwen-Image, its 20B image model
🧑🎓 Opinion: NVIDIA is locking horns with China’s AI chips (Huawei) in the global GPU War: The current state of things
🇨🇳 Alibaba’s cracked “Qwen Team” open-sourced Qwen-Image, its 20B image model

🇨🇳 Next great opensource model from China. Meet Qwen-Image — a 20B Multimodal Diffusion Transformer model for next-gen text-to-image generation. Especially strong at creating stunning graphic posters with native text. Now open-source.
Runs under Apache 2.0 so anyone can deploy it for free. Support for embedded text in English & Chinese, i.e. it can write crisp English and Chinese right inside pictures.
Qwen-Image separates itself from other generative image models by handling text within images much more precisely — something many others still haven’t nailed.
It works well with both letter-based and symbol-based writing systems, and it handles tricky things like detailed typography, multi-line arrangements, full paragraphs, and mixed-language text like English and Chinese.
This makes it useful for creating stuff like movie posters, slide decks, storefront visuals, handwritten poems, or infographic-style content — all with text that looks clean and fits exactly what the prompt asked for.
Under the hood it blends Qwen2.5-VL for text understanding, a high-res VAE for pixels, and a MMDiT diffusion core; MSRoPE keeps every character anchored to its spot .
Training drew on billions of pairs: 55% nature photos, 27% design layouts, 13% people imagery, plus 5% in-house synthetic text scenes to balance rare characters while avoiding third-party artifacts .
Benchmarks show it topping or tying closed models on GenEval, DPG, OneIG-Bench, CVTG-2K and more; on the human-voted AI Arena it sits #3 overall and #1 open-source .
Architecture
Its a MMDiT i.e. Multimodal Diffusion Transformer model. So it runs a diffusion process yet swaps the usual U-Net backbone for transformer blocks that handle image patches and prompt tokens together in one long sequence .
During training the model sees a noisy latent picture plus the text embeddings. Each layer holds two weight sets, one tuned for vision, one for language, but a shared attention pattern lets the tokens talk to each other. The network learns to predict the clean latent step by step, so at inference it can peel noise away and paint pixels while reading the prompt word by word.
That tight coupling pays off because the transformer can track where every letter or object should land, giving sharper text, cleaner layouts, and stronger prompt loyalty than older hybrids that bolt a text encoder onto a U-Net. It also scales smoothly, which is why Stable Diffusion 3 and Qwen-Image push the idea up to billions of parameters.
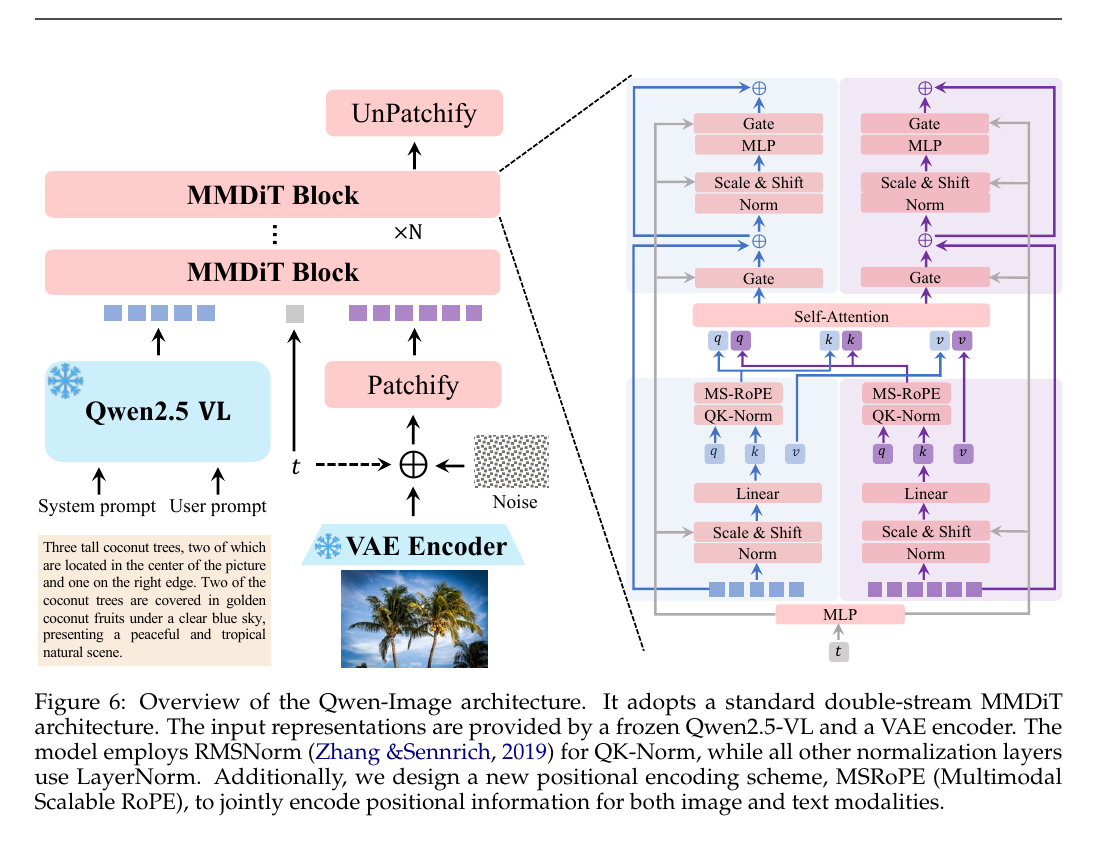
The diagram maps the full flow from words to finished picture. A user prompt and an optional system prompt go through a frozen Qwen2.5-VL text model, which turns the words into a string of language tokens that carry meaning and layout hints.
A separate VAE encoder turns the target image into latent patches, sprinkles controlled noise over them, then hands the noisy patches to a patchify step. Each patch now sits in the same token list as the language tokens, so the network can look at everything side by side.
Inside the pink MMDiT blocks the model runs a Transformer that holds two aligned streams, one for vision patches, one for text tokens. Shared attention lets tokens swap clues about what should appear and where. MSRoPE positional encoding keeps every letter, symbol, and pixel in the right spot while scale-and-shift layers nudge features into a common range.
After several denoising cycles, unpatchify stitches the cleaned-up patches back into an image. The VAE decoder then lifts the latent image into full resolution pixels.
This tight coupling of text and vision is what lets Qwen-Image place Chinese and English words crisply inside posters, slides, and other layout-heavy scenes while still following the user’s creative brief.
🧑🎓 Opinion: NVIDIA is locking horns with China’s AI chips (Huawei) in the global GPU War: The current state of things

Nvidia’s top AI GPUs are off-limits in China, so Huawei built an enormous AI machine – the CloudMatrix 384 – to fill that gap.
This new system links 384 Ascend 910C AI chips with ultra-fast optical connections, is Huawei’s brute-force approach to fight with its rivals (NVIDIA).
🔗 A Look at CloudMatrix 384 (Huawei’s Supernode)

Physically, CloudMatrix 384 is huge. It spans 16 server racks in a data center. Out of those, 12 racks are filled with compute nodes (Ascend chips) and 4 racks are dedicated to networking gear (optical switches and cabling). In each compute rack there are 32 Ascend 910C processors. The system uses full optical interconnects instead of copper wiring between chips and racks. This is cutting-edge: optical links carry data as light, allowing higher bandwidth and longer reach with less signal loss compared to traditional electrical cables.
Recent testing by China’s DeepSeek AI team revealed that Huawei’s Ascend 910C chips deliver 60% of NVIDIA H100’s performance with “unexpectedly good” results. DeepSeek converted its systems from NVIDIA’s software to Huawei’s with just one line of code.
Now let’s see NVIDIA’s lineup:

NVIDIA’s datacenter GPU roadmap since 2020 shows 4 clear jumps in raw AI throughput, rising from 312 TFLOPS FP16 in A100 to about 4 PFLOPS FP8 in H100, then 8 PFLOPS in the dual-chip GH200, and finally 20 PFLOPS FP4 in the new Blackwell B200, each launch roughly doubling or better the peak performance of its predecessor.
And, Last week Bloomberg released a long video stating, NVIDIA’s current flagship data-center GPU, the H100, delivers roughly 3-4X the computing power of “local design chips”, a group that includes Huawei’s Ascend series. Huawei and several U.S. officials also acknowledge that Ascend is at least 1 generation behind the H100 and its upcoming successor, the H200.
This Bloomberg really sums up the current situation.
"China's created a colossal $48 billion semiconductor investment fund to build up its chip manufacturing. But despite the money, it still can't match other manufacturers. The precision required is so advanced, it's kind of like landing on the moon, And I don't think that's an overstatement at all. It requires the use of very specific lasers through sort of a web of mirrors, and the technology is really mind boggling. It’s very, very difficult to do, even if China is trying very hard. They're still multiple generations behind. So I think that really creates, obviously, a very high in demand product. Despite the advances in Chinese semiconductor manufacturing by the likes of Huawei, Chinese firms still aspire to buy massive volumes of banned Nvidia chips. One of Nvidia's H100 chip can achieve maybe 3 to 4 times more computing power than local design chips. So that's how Nvidia chips have been sought after in China. By Huawei's own account, and that of several U.S. government officials, the best Chinese chip, the Huawei Ascend series, is still at least a generation behind."
Because of that gap, a workload that finishes on 1 H100 would need several Ascend devices or significantly longer run-times to reach the same training throughput, and it would draw more electricity per unit of work. This performance and efficiency lead Chinese operators to pursue Nvidia H100 or H200 parts even though the chips are restricted, while Huawei’s Ascend, though improving, still trails by 1 full generation in both raw speed and power efficiency.
However, Huawei narrowed the gap with its 910C is a dual-chiplet AI processor.
But lets see the notable drawbacks of Huawei 910C when comparing to Nvidia:
Power Consumption: CloudMatrix’s performance-per-watt is much lower. Each computing operation on Huawei’s system costs about 2.3× more energy than on Nvidia’s system. Over time, this can mean higher electricity bills and more heat to manage. For some operators outside China (or even within, depending on location), this inefficiency would be a deal-breaker. Huawei basically needs a much bigger electric feed and cooling setup to do the same job. In environments where power is limited or very expensive, this is a serious disadvantage.
Density and Space: Because Huawei uses five times more chips spread across many racks, the footprint is larger – roughly 16 racks versus maybe 1–2 racks for an Nvidia DGX SuperPOD of similar capacity. 16× the floor space is a lot; not every data center can accommodate that easily. Nvidia’s solution is much more compact and compute-dense. If you’re a cloud provider or enterprise where data center space (and the cost of building/renting it) matters, Nvidia’s approach wins on density.
Per-Chip Performance: Each Ascend 910C chip is weaker than a state-of-the-art GPU. This matters for workloads that can’t perfectly scale across hundreds of chips. Not every AI job splits nicely – sometimes having a single very fast GPU is better (for example, for running smaller models or doing single-stream inference with low latency). Nvidia’s GPUs shine in single-chip or few-chip scenarios. Huawei’s solution really makes sense when you need a huge cluster; for smaller workloads, it’s overkill and individually slow. Also, Nvidia’s GPUs have certain features like Tensor Cores optimized for training, FP8 support, and a track record of well-tuned performance – Ascend is catching up but not there yet on a per-chip basis.
Maturity and Ecosystem: Perhaps the biggest disadvantage for Huawei is software (more on that below). Nvidia has decades of refinement in its CUDA software, driver optimizations, and developer tools. Huawei’s hardware is new, and early reports indicate developers have a tougher time getting peak performance out of Ascend chips. One Huawei engineer described using the previous-gen Ascend 910B as “a road full of pitfalls,” where he constantly hit bugs and had to get help from Huawei’s support team to make things work. This suggests that, while the hardware is solid on paper, the usability and stability of the software stack is not yet on Nvidia’s level. In enterprise settings, time is money – if it takes extra effort to debug and optimize on Huawei’s platform, that’s a hidden cost.
Huawei has developed its own software stack to support Ascend chips:
CANN (Compute Architecture for Neural Networks): This is Huawei’s equivalent of CUDA – a low-level API and driver set that lets the hardware run machine learning operations efficiently. It provides kernels, compilers, and runtime for Ascend.
MindSpore: This is Huawei’s home-grown AI framework, analogous to PyTorch or TensorFlow. It’s a high-level framework for building and training models, optimized for Ascend hardware. MindSpore can also run on GPUs and CPUs, but it’s particularly tuned for Huawei’s chips.
Framework support: Huawei knows everyone uses PyTorch, so they made an Ascend PyTorch plugin called
torch_npu. This allows PyTorch code to run on Ascend chips (just like you’d run on a GPU, but you change the device to NPU). In theory, this lets developers keep using familiar tools and only swap out the hardware backend. However, this plugin tends to lag behind mainline PyTorch versions and might not support every latest feature. It’s essentially a translation layer – not as battle-tested as Nvidia’s support.ONNX and model conversion: Huawei is investing in ONNX (Open Neural Network Exchange), a format to port models between frameworks. The idea is you could take a model trained on Nvidia and run it on Ascend via ONNX, or vice versa, with minimal changes. They also offer tools like MindConverter to help convert TensorFlow/PyTorch models into MindSpore or Ascend-compatible format.
Despite these efforts, Huawei’s software ecosystem is still young. There are growing pains:
Stability and support: Developers have reported that using Ascend can be challenging. Documentation can be sparse or disorganized, and the community is much smaller. One Chinese developer wrote that when he first started with Ascend, he felt “quite overwhelmed” and that with so few people using it, it was hard to find solutions to problems online. Another even suggested that CANN may not be truly mature until 2027 based on current progress. By contrast, Nvidia’s stack just works out-of-the-box in many cases – SemiAnalysis testers noted that on Nvidia “we didn’t run into any Nvidia-specific bugs” during ML benchmarks. Huawei’s platform, on the other hand, required direct help from Huawei engineers for troubleshooting in some cases. Huawei has responded by embedding engineers at client sites (reminiscent of how Nvidia evangelized CUDA in its early days) to help customers port and optimize their code. It’s a very one-on-one support model right now.
Performance tuning: Even if raw hardware is powerful, getting peak performance might need model rework. The Zhihu article mentioned in 2024 that “any public model must undergo deep optimization by Huawei” before it runs efficiently on Ascend. That implies that if you take a stock PyTorch model and try to run on Ascend, it might not be as fast as expected until you tweak things.
CUDA momentum: Many AI libraries and tools are built with Nvidia-first assumptions. Switching to Ascend might mean certain libraries (for example, some custom CUDA kernel or a specific CUDA-based optimizer) won’t have an equivalent on Ascend. Over time, Huawei can catch up by building or sponsoring similar libraries, but it’s a huge task to replicate the rich CUDA ecosystem. Nvidia’s ecosystem has a decade head start and widespread community support. Huawei is effectively asking developers to learn a new platform (MindSpore/CANN) or trust their translation layers – that’s a big ask outside of China. Inside China, though, there’s government and industry push to make this transition, so we see companies like Alibaba and Tencent at least experimenting with Ascend-powered frameworks.
On a positive note, Huawei’s software compatibility is improving. They claim Ascend 910C supports major AI frameworks – you can use TensorFlow and PyTorch on it via their tools, not just MindSpore. This means if you’re a researcher, you wouldn’t necessarily have to rewrite all your code from scratch; you might just need to install Huawei’s version of PyTorch or use their converter. It’s not plug-and-play to the same degree as switching between Nvidia and AMD GPUs (which both use commonly supported frameworks), but it’s getting closer. Huawei’s long-term strategy clearly is to build a full-stack alternative to Nvidia, encompassing chips and software. In the meantime, for developers, the learning curve is extremely steeper with Ascend.
🧭 The China Context – Why Build a GPU Rival?
The drive behind CloudMatrix 384 is largely geopolitical and strategic. Advanced Nvidia GPUs like the H100 are restricted for export to China, so Chinese tech firms can’t get NVIDIAa’s latest-and-greatest.
This created a huge incentive for a domestic alternative. Huawei’s answer is the Ascend series of AI accelerators and systems like CloudMatrix. By developing its own AI chips, Huawei reduces reliance on foreign tech and ensures Chinese companies have high-end hardware for AI.
Tech giants in China (like Baidu, ByteDance, Alibaba, etc.) still use a lot of NVIDIA GPUs, but those are either older models or special cut-down versions. Huawei is trying to step in with homegrown hardware that can keep up with global AI demands despite U.S. sanctions. In fact, Huawei has been seeding its Ascend 910C chips to major Chinese players like Baidu and ByteDance for testing. As of late 2024, nearly half of China’s top 70 large language models were trained using Huawei Ascend chips – showing significant adoption, driven in part by government push for self-sufficiency.
How this affects the fight for global dominance in AI
The direction of the global AI race could be changing. Tech market investors are starting to worry, with analysts warning that US companies might seriously fall behind if China’s market stays shut and its domestic tech becomes more popular worldwide. Many are already reassessing their bets on US tech, especially now that China looks able to do without American chips—and possibly make ones that are even more powerful.
That’s a wrap for today, see you all tomorrow.