
🏆 Alibaba’s new Qwen3 scores higher than rivals in key benchmarks
Qwen3’s small patch boosts performance, Gemini 2.5 adds image segmentation, and Kimi K2 shows how self-critic RL sharpens clarity, brevity, and safety, Elon Musk plans 50Mn NVIDIA H100 GPUs
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-July-2025):
🏆 Alibaba’s new Qwen3 scores higher than rivals in key benchmarks
🚨 Google Gemini 2.5 introduces conversational image segmentation for AI, enabling advanced visual understanding
📡 Kimi K2 Technical paper is out: Self-critic RL aligns clarity, brevity, and safety together
🛠️ OpenAI and Oracle will add a huge 4.5 gigawatts of Stargate data-center capacity
🗞️ Byte-Size Briefs:
Elon Musk just said 50M NVIDIA H100 grade accelerators to come online for xAI within 5 years.
🏆 Alibaba’s new Qwen3 scores higher than rivals in key benchmarks
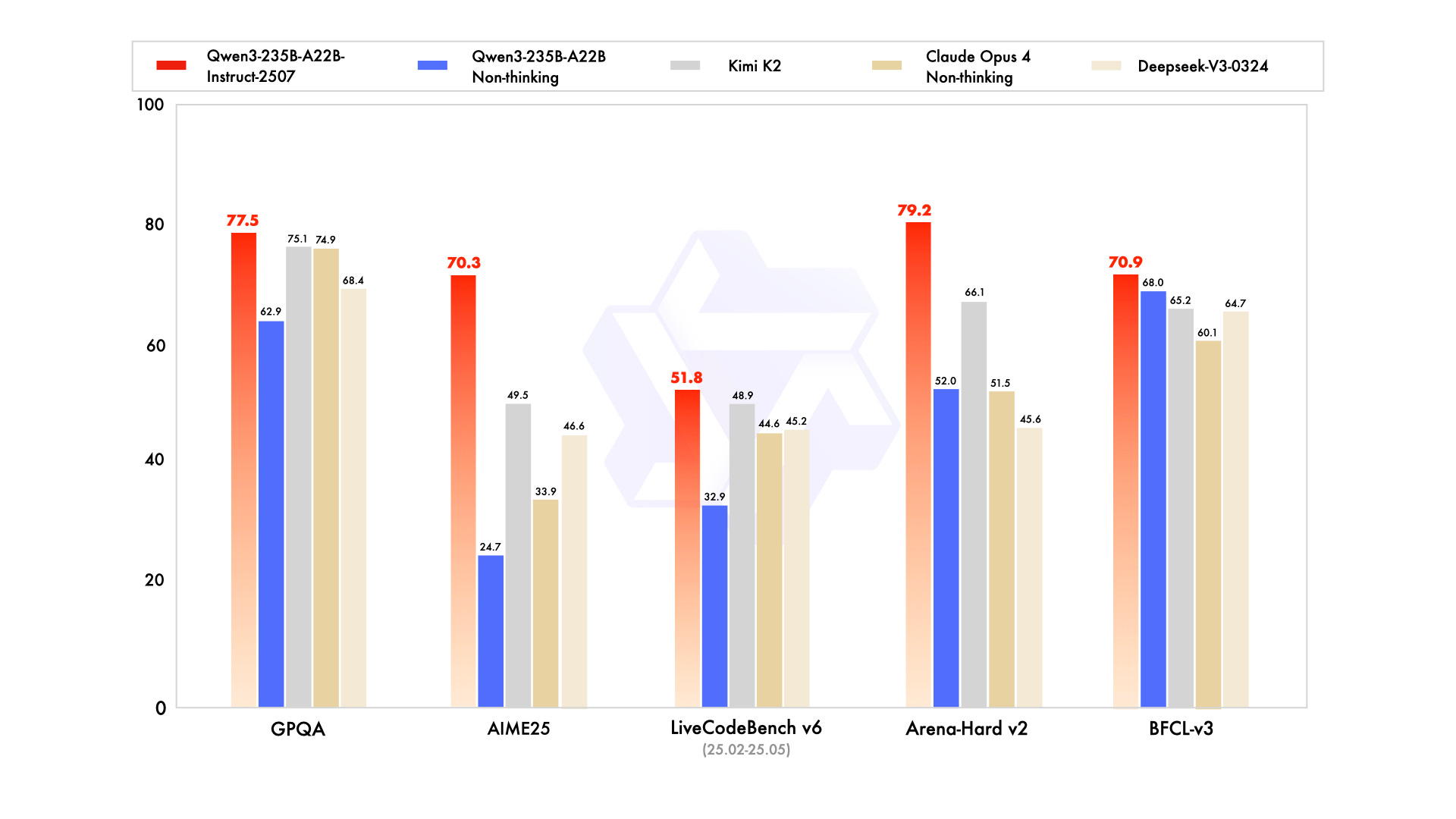
Qwen released Qwen3-235B-A22B-2507, a minor upgrade to Qwen3-235B-A22B, which provides a significant performance boost. It takes back the benchmark crown from Kimi 2.
Hybrid thinking mode is dropped.
So, this model now supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
Key takeaways
Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage.
Markedly better alignment with user preferences in subjective and open-ended tasks, enabling more helpful responses and higher-quality text generation.
Instruct and Thinking models will now be trained separately.
Qwen3-235B-A22B-Instruct-2507 and its FP8 variant are now released
Total number of Parameters: 235B and 22B activated
Number of Experts: 128
Number of Activated Experts: 8
Context Length: 262,144 natively.
Number of Layers: 94
Number of Attention Heads (GQA): 64 for Q and 4 for KV
After this update Qwen3 reclaimed the benchmark lead from Kimi K2.

But note that their intended use differs.
Kimi K2 markets itself as an “open agentic intelligence” engine that can plan multi‑step tool calls, run shell commands and even refactor full codebases out of the box.
Qwen3 stays in non‑thinking chat mode and leaves agent orchestration to its companion Qwen‑Agent library, focusing the base model on raw language, reasoning and long‑context performance.
Let’s look at how Qwen3 235B-A22B stacks up differently against Kimi 2:
235B total parameters versus 1T, so Qwen3 is about 4.25× smaller.
22B activated parameters versus 32B, giving Qwen3 roughly 1.45× fewer active weights per token.
Qwen3 keeps 94 transformer layers; Kimi K2 instead cuts attention heads for efficiency rather than disclosing depth.
Both use sparse MoE, but Qwen3 lists 128 experts with 8 active while Kimi only says it raises sparsity further.
Qwen3 reads up to 262144 tokens in one pass; Kimi K2 does not publish a context limit.
Kimi K2 trains on 15.5T tokens with the MuonClip optimizer and qk-clip fix; Qwen3 card does not mention such tricks.
Kimi K2 is tuned for multi-step tool use and general RL on synthetic agent traces, while Qwen3 stays in non-thinking chat mode and leaves orchestration to external libraries.
On AIME25 reasoning, Qwen3 scores 70.3 versus 49.5 for Kimi.
On ARC-AGI open-domain reasoning, Qwen3 posts 41.8 against Kimi’s 13.3.
🚨 Google Gemini 2.5 introduces conversational image segmentation for AI, enabling advanced visual understanding

Gemini 2.5 introduces conversational image segmentation for AI, enabling advanced visual understanding through object relationships, conditional logic, and in-image text.
It supports five query styles for segmentation: relational, conditional, abstract, text found in images, and multilingual prompts.
Understands natural, everyday descriptions.
Handles label output in several languages including French and Spanish.
Generates task-based masks for creative work, safety analysis, and insurance needs.
Accessible through API without the need for custom training.
Can be used interactively in Google AI Studio or in a Python Colab setup.
🔍 The model understands relationships like “the person holding the umbrella”, ordering such as “the third book from the left”, and comparisons like “the most wilted flower”. Those patterns form the first of the 5 query buckets.
⚙️ Conditional logic comes next, letting prompts exclude or filter, for example “people who are not sitting”, and Gemini returns masks only for the standing crowd.
💡 Abstract requests such as “damage” or “a mess” rely on the model’s world knowledge instead of simple visual templates, so claims adjusters can isolate dents or broken tiles without extra labels.
🔤 In‑image text spotting means a bakery sign saying “Pistachio Baklava” becomes a direct handle in the prompt, and multilingual support keeps the same power for many languages.
🎨 Creative workers skip fiddly lasso tools by typing “the shadow cast by the building”; factories spot rule breaks with “employees not wearing a hard hat”; insurers highlight storm‑hit houses in one shot.
🚀 For builders, language‑first segmentation removes the need for separate detectors, masks, and OCR stacks. Use gemini‑2.5‑flash, request JSON, and keep thinkingBudget at 0 for fastest replies.
📡 Kimi K2 Technical paper is out: Self-critic RL aligns clarity, brevity, and safety together
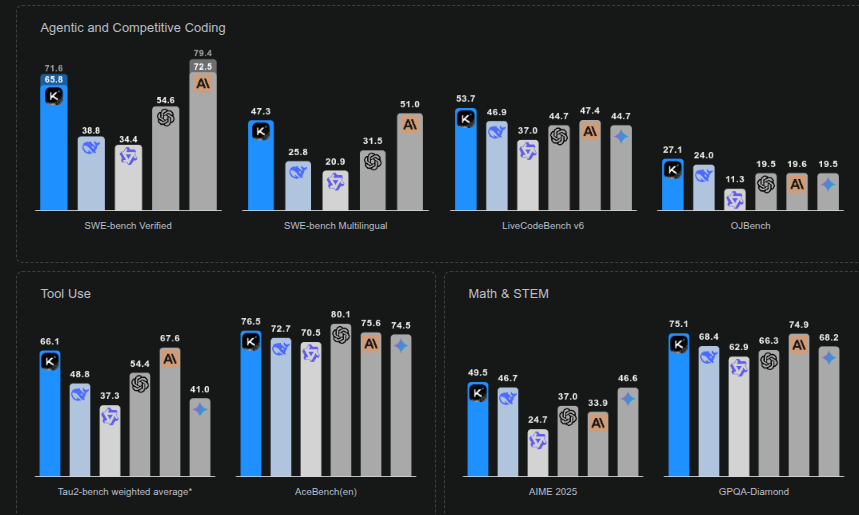
Kimi K2 is the "Open-Source Agentic Model" with a sparse mixture of experts (MoE) and with 1T total parameters (~1.5x DeepSeek V3/R1's 671B) and 32B active parameters (similar to DeepSeek V3/R1's 37B).
Key takeaways (Read the full paper here)
MuonClip blends Muon updates with a query-key rescaler so attention logits never rise past 100, holding the full 15.5T-token run rock-steady.
Chunk-wise LLM rephrasing and math “learning-note” rewrites reuse scarce text, lifting SimpleQA accuracy to 28.9% on the same token count.
A 1.04T MoE blocks fires just 8 of 384 experts each step, hidden size 7168, giving dense-like quality while spending roughly dense-32B compute.
Sparsity-48 scaling law shows the same 1.5 validation loss with about 1.7x fewer FLOPs than sparsity-8, so bigger expert pools clearly pay off.
Synthetic pipeline grows 20 000+ fake tools plus real MCP APIs, spawns agents, then filters multi-turn trajectories with an LLM judge, seeding rich tool-use data.
RL phase mixes hard verifiable scores with a self-critic rubric, while per-task token caps keep answers tight yet deep.
Activation offload, selective recompute and FP8 tiles squeeze model states into ≈30GB per H800 GPU, making trillion-scale training practical.
A checkpoint engine streams the full shard set to every inference worker in under 30 s, thanks to a two-stage H2D and IPC broadcast pipeline.
Token template lets the model issue several parallel tool calls, and an on-the-fly enforcer blocks malformed JSON before it ever escapes.
Early QK-Clip deactivates after roughly 70 000 steps, proving the clamp is only a start-up safety harness, not a lifelong crutch.
🛠️ MuonClip keeps training stable: The base Muon optimizer saves tokens but lets attention logits explode. A tiny post-update rescaler called QK-Clip stops any head from pushing logits past 100, and after about 70 000 steps the clamp turns off while the 15.5 T-token run stays smooth.
📚 Rephrasing squeezes more from each token: This is a brilliant technique they applied for Kimi K2 - Rephrasing to overcome data-scarcity.
High-quality text is limited, yet the model must see huge amounts of varied language. So the team stopped looping the same passages through many epochs because that wastes tokens and risks overfitting. Instead they built a rephrasing pipeline that turns each original chunk into several fresh versions while keeping meaning intact.
Each chunk passes through carefully crafted prompts that ask another LLM to restyle the wording or swap viewpoints. Automatic checks then compare the new text to the source and drop anything that drifts away from the facts. This preserves knowledge while adding diversity.
The team ran three experiments on the SimpleQA benchmark. Repeating raw data for 10 epochs scored 23.76%. Rephrasing once and repeating for 10 epochs jumped to 27.39%. Making 10 rephrasings and training only 1 epoch reached 28.94%. The jump shows that richer phrasing squeezes more learning signal from the same token budget.
They applied the same idea to math. Formal proofs and problem sets were rewritten into a “learning-note” style, and high-quality material in other languages was translated into English. This broader mix helps the model reason about math without memorising exact wording.
🏗️ Architecture tuned for sparse power: The model owns 384 experts but fires only 8 per token, giving sparsity 48 and keeping FLOPs in check. Hidden size is 7168, experts use 2048-unit feed-forward blocks, and the team halves attention heads from 128 to 64 because doubling heads improves loss by only 1.2%.
🤖 Synthetic tool-use data teaches real agency: A three-step pipeline spawns 20 000 + synthetic tools, thousands of agents, and rubric-checked tasks. Simulated users chat, agents call tools, a judge LLM filters successful trajectories, and real sandboxes verify code, letting the model practice multi-turn fixes and error recovery.
🎲 RL with self-critique sharpens answers: After supervised fine-tune, the model runs policy optimisation where a built-in critic ranks its own rollouts for clarity, fluency, and safety. Verifiable tasks give hard rewards, subjective tasks lean on the critic, temperature decay keeps exploration early and precision late, and token caps teach concise depth.
🏆 Benchmark scoreboard: Without chain-of-thought the model scores 65.8% on SWE-bench Verified single attempt, 53.7% on LiveCodeBench v6, 66.1% on Tau2, and 89.5% on MMLU, while hallucination rate is just 1.1% on HHEM v2.1.
⚡ Hardware and parallel tricks: Training runs on H800 GPUs in flexible 32-node blocks, mixing 16-way expert parallel, virtual pipeline stages, and ZeRO-1 data parallel. Activations offload to CPU, cheap layers recompute, FP8 stores big blobs, so each GPU holds about 30 GB of states, and a two-stage checkpoint engine moves the trillion-parameter shard set in under 30 s.
🛠️ OpenAI and Oracle will add a huge 4.5 gigawatts of Stargate data-center capacity

OpenAI charging ahead, all guns blazing. They announced, OpenAI and Oracle will add 4.5 gigawatts of Stargate data-center capacity. This lifts total planned muscle past 5 gigawatts and lines up over 100,000 new U.S. jobs. That means that 5GW of the original 10GW Stargate commitment is now under development.
Stargate is a joint venture between OpenAI, Oracle and Softbank that aims to invest up to $500 billion in AI infrastructure in the U.S. The update from OpenAI comes one day after the Wall Street Journal reported that the Stargate project has struggled to get off the ground.
The fresh build will pack 2 million Nvidia Grace Blackwell 200 accelerators on racks Oracle already trucks to Abilene, Texas. Early racks are live, handling trial runs for the next frontier model while electricians keep stringing high-voltage lines.
Oracle will own and run most of the floor space, renting idle slices, while SoftBank finances other Stargate hubs and Microsoft Azure stays a fallback Investors.
The White House frames domestic compute as infrastructure on par with highways, so this concrete, steel, and silicon push fits the policy playbook.
"Stargate is an ambitious undertaking designed to meet the historic opportunity in front of us," OpenAI said in a statement. "That opportunity is now coming to life through strong support from partners, governments and investors worldwide."
🗞️ Byte-Size Briefs
Elon Musk just said 50M NVIDIA H100 grade accelerators to come online for xAI within 5 years. 💰 And WSJ reports xAI wants another $12B in private credit to buy Nvidia chips, build a bigger data center, and keep Grok training fast.
Valor Equity Partners is talking to direct‑lending funds so xAI can lease the chips instead of paying up‑front.
🆚 Competitive pressure
OpenAI has Microsoft capital, Anthropic leans on Amazon, and Google funds DeepMind internally, so each rival off‑loads hardware cost to a bigger balance sheet. So each of the top labs must reach similar compute at similar timelines.
To put the numbers in context, current public quotes put a single Nvidia H100 between roughly $25,000 and $31,000.So multiplying that unit‐price band by 50mn yields a cost range of about $1.25 trillion to up to $1.55 trillion.
That doesn’t mean xAI will drop that full amount. Falling costs and better efficiency could bring the real number way down.
That’s a wrap for today, see you all tomorrow.