
Alibaba's Qwen 2.5 VL released, the best open Multimodal Vision Model, taking on OpenAI Operator
Alibaba's Qwen 2.5 VL challenges OpenAI, Suno for music generation is released, Unsloth Library fine-tunes DeepSeek-R1, ChatGPT Gov debuts, and Gemini 2.0 dominates in performance-pricing benchmarks.

Read time: 7 min 19 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (28-Jan-2025):
📹 Alibaba's Qwen 2.5 VL released, the best open Multimodal Vision Model, taking on OpenAI Operator
🏆 Qwen2.5-Max, Another Chinese open source model also released and it outperforms DeepSeek V3
🎹 Open-model alternative to Suno for music generation is released, now you can generate full songs with a 7B parameter model
🗞️ Byte-Size Briefs:
📢 OpenAI launches ChatGPT Gov, AI tailored for 3,500+ US agencies.
📊 Gemini 2.0 Flash ranks top in Price-vs-Lmsys Elo, prices fell 27x.
🧑🎓 Deep Dive Tutorial
Fine-tuning DeepSeek-R1 using Unsloth Library
📹 Alibaba's Qwen 2.5 VL released, the best open Multimodal Vision Model, taking on OpenAI Operator

🎯 The Brief
Qwen released Qwen2.5-VL, a vision-language model in 3 sizes (3B, 7B, 72B), with groundbreaking abilities in video comprehension, document parsing, and object recognition. It significantly enhances visual understanding and multimodal integration, supporting agentic tool use and structured outputs. Apache 2.0 licensed (except 72B), it's available on Hugging Face and ModelScope. Outperformed competitors like GPT-4o-mini, especially in document understanding and agent-based tasks.
⚙️ The Details
→ Qwen2.5-VL integrates advanced vision and language capabilities, excelling in identifying objects, charts, layouts, and texts across diverse visual formats.
→ Its agentic capabilities allow reasoning and control of external tools like phones and computers, enabling real-world applications without task-specific fine-tuning. That means Qwen2.5-VL 72B will perform well as a base model for an OpenAI’s Operator-like agent. And its open-sourced.
→ The model supports hour-long video processing, offering second-level temporal event pinpointing via dynamic frame rate training and time encoding.
→ Enhanced OCR handles multilingual and multi-orientation text, while its QwenVL HTML feature extracts structured data from layouts like invoices and papers.
→ Object localization generates precise bounding boxes with JSON outputs, aiding applications in finance, commerce, and document intelligence.
→ A redesigned ViT encoder improves efficiency with Window Attention and dynamic resolution, cutting computational costs while maintaining accuracy.
🏆 Qwen2.5-Max, Another Chinese open source model also released and it outperforms DeepSeek V3
🎯 The Brief
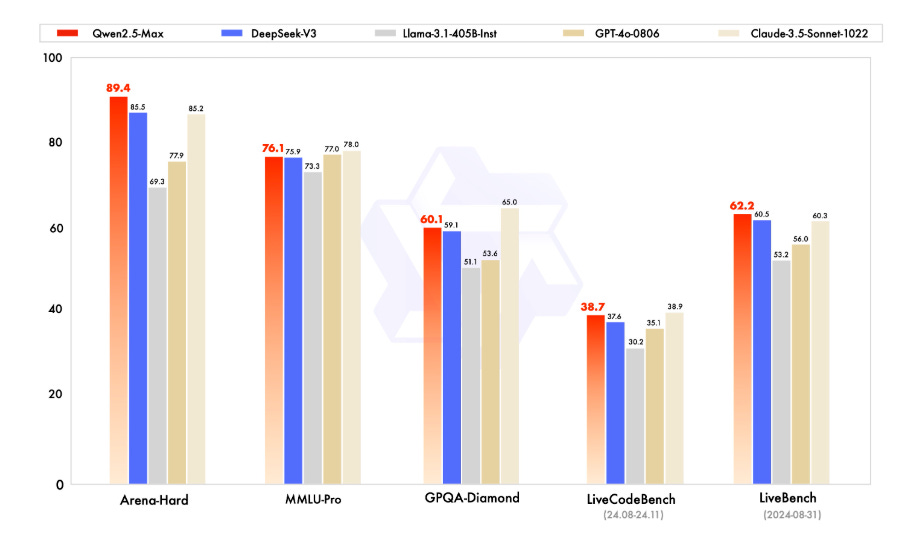
Qwen2.5-Max, a new large-scale Mixture-of-Experts (MoE) LLM, outperforms DeepSeek V3 and other leading models on benchmarks like Arena-Hard, LiveBench, LiveCodeBench, and GPQA-Diamond. Pretrained on 20 trillion tokens, it uses SFT and RLHF for fine-tuning. The model is accessible via Qwen Chat, Alibaba Cloud API, and a Hugging Face demo.
⚙️ The Details
→ Qwen2.5-Max leverages MoE architecture to scale intelligence through massive data and model size. It was trained on 20 trillion tokens and refined using SFT and RLHF techniques.
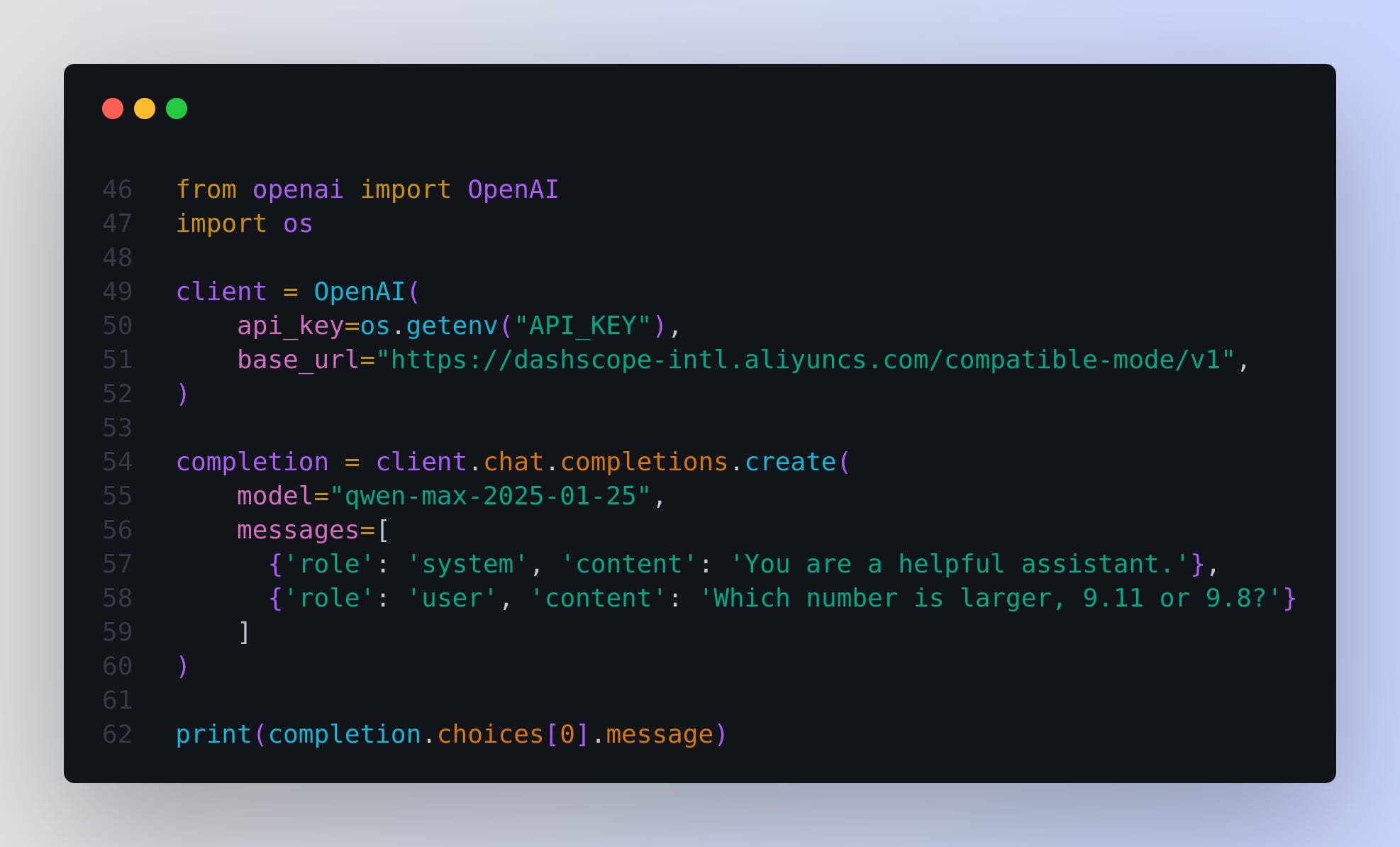
→ The API supports OpenAI-compatible usage and requires an Alibaba Cloud account for setup. A Python code snippet demonstrates integration.
→ Available on Qwen Chat, the model supports interactive tasks like search and coding. Additionally, a Hugging Face demo facilitates exploration.
→ Future development focuses on scaling RL to enhance reasoning, aiming for breakthroughs in model capabilities.
Since the APIs of Qwen are OpenAI-API compatible, we can directly follow the common practice of using OpenAI APIs. Below is an example of using Qwen2.5-Max in Python:
🎹 Open-model alternative to Suno for music generation is released, now you can generate full songs with a 7B parameter model
🎯 The Brief
YuE, an open 7B parameter model, offers full-song generation capabilities rivaling commercial systems like Suno. It supports 5-minute music generation, syncing vocals and accompaniment, and allows customization of genre, lyrics, and background music. Its innovations include techniques to manage complex, long-context music generation effectively.
⚙️ The Details
→ YuE addresses challenges in music generation, such as long-context processing, music complexity, and limited lyrics-audio datasets, using advanced techniques like a dual-token system and lyrics-chain-of-thought generation.
→ The model supports track-synced vocal-instrumental output without altering its LLaMA-based architecture and uses a 3-stage training scheme to enhance scalability and quality.
→ It enables diverse genres (e.g., jazz, rap, rock, metal) and languages (e.g., English, Mandarin, Japanese), with impressive support for code-switching between languages in songs.
→ YuE also demonstrates advanced vocal techniques, such as scatting, death growl, and harmonica improvisation, showcasing its adaptability for professional-level music generation.
→ Available on Hugging Face, it represents a significant step towards democratized music AI.
For GPUs with 24GB memory or less: Run up to 2 sessions concurrently to avoid out-of-memory (OOM) errors.
For full song generation (many sessions, e.g., 4 or more): Use GPUs with at least 80GB memory. This can be achieved by combining multiple GPUs and enabling tensor parallelism.
On an H800 GPU, generating 30s audio takes 150 seconds. On an RTX 4090 GPU, generating 30s audio takes approximately 360 seconds.
🗞️ Byte-Size Briefs
📢 OpenAI has launched ChatGPT Gov, ChatGPT Gov, a secure AI platform on Microsoft Azure, helps U.S. agencies modernize workflows and address challenges like public health and national security. It ensures sensitive information remains protected, providing advanced AI tools tailored for government operations and decision-making. Since 2024, more than 90,000 users across more than 3,500 US federal, state, and local government agencies have sent over 18 million messages on ChatGPT to support their day-to-day work.
A Tweeter post goes viral showing Gemini 2.0 Flash thinking is the best model in Price-vs-Lmsys Elo performance rating. And its overall progress (in both pricing and intelligence) over the last 3-4 months have been the most sharp among all the other models. Also it shows that o1 level model pricing fell 27x in just the last 3 month.
🧑🎓 Tutorial - Fine-tuning DeepSeek-R1 using Unsloth Library
Unsloth is an open-source framework designed to make fine-tuning large language models (LLMs) 2X faster and extremely memory-efficient.
This example uses Unsloth’s FastLanguageModel module to load the distilled Llama-8B model with 4-bit precision for efficiency.
This model is developed by using Unsloth's Dynamic 4-bit Quants which selectively avoids quantizing certain parameters, greatly increase accuracy than standard 4-bit.
And this distilled model is part of DeepSeek’s distillation series. Here they use and innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 series models, into standard LLMs.
And after the finetuning, we will use ollama for runing it locally.
Steps:
Install Dependencies:
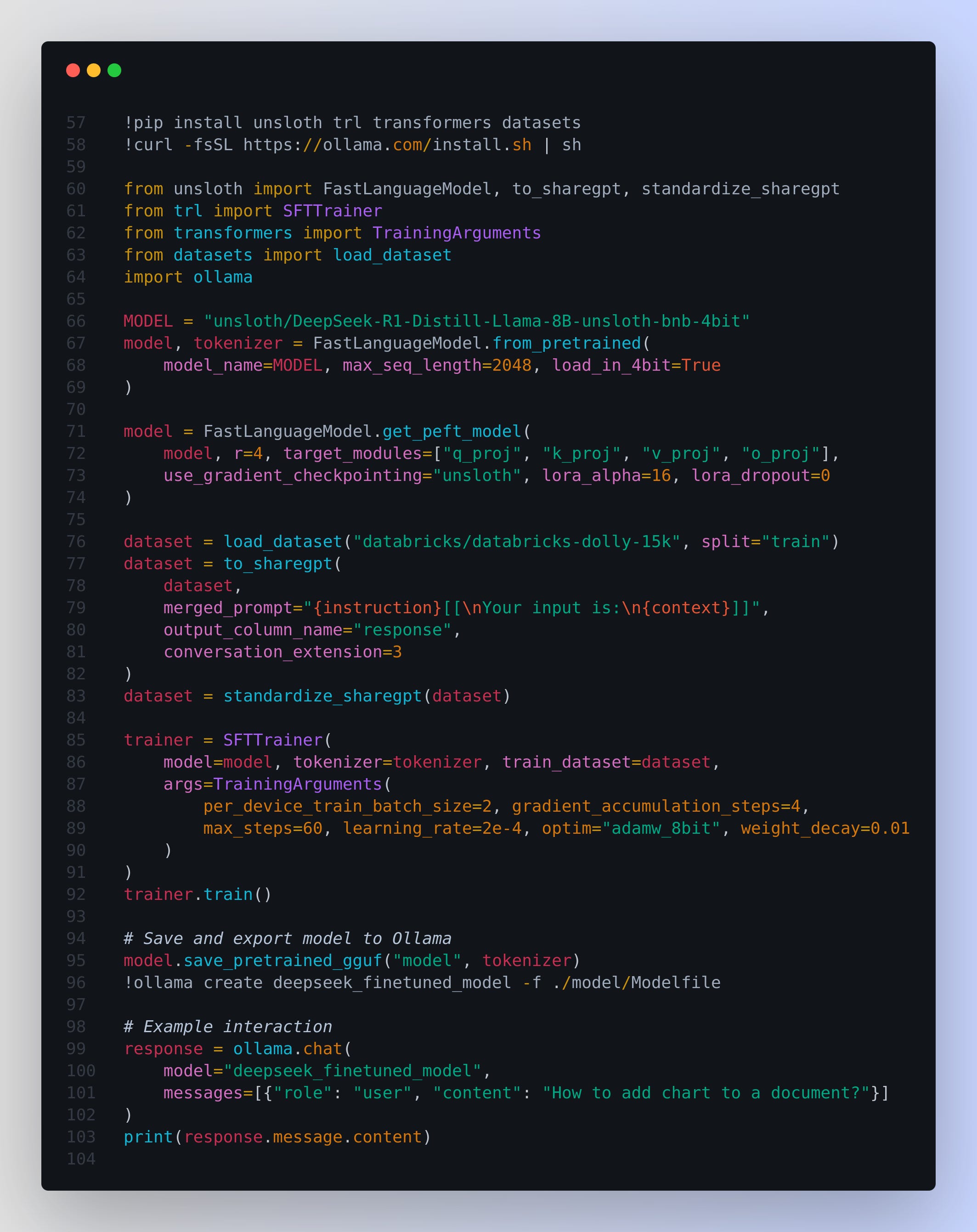
Begin by installing essential Python libraries such asunsloth,trl,transformers, anddatasets. Additionally, install Ollama to facilitate local model deployment.Load Model and Tokenizer:
Utilize Unsloth’sFastLanguageModelto load the DeepSeek-R1 (distilled Llama-8B) model with optimized settings for efficient fine-tuning, including 4-bit precision.Configure LoRA (Low-Rank Adaptation):
Apply Parameter-Efficient Fine-Tuning (PEFT) using LoRA. Specify target modules (q_proj,k_proj,v_proj,o_proj) and set hyperparameters like rank, alpha, and dropout to enhance training efficiency.Prepare the Dolly-15k Dataset:
Load the "databricks/databricks-dolly-15k" dataset, which includes columns such asinstruction,context,response, andcategory. Format the dataset to match the model’s input requirements by merginginstructionandcontextinto a unified prompt and standardizing the conversation structure.Set Up and Train the Model:
Initialize theSFTTrainerwith appropriate training arguments (e.g., batch size, learning rate). Execute the training process to fine-tune the model on the prepared Dolly-15k dataset, monitoring the loss to ensure effective learning.Export and Deploy with Ollama:
Save the fine-tuned model in the GGUF format. Use Ollama to create and register the new model locally, enabling seamless interaction and deployment.Interact with the Fine-tuned Model:
Test the deployed model using Ollama’s interface by sending prompts and receiving customized responses tailored to your specific tasks.
We could also use vLLM to run the same Fine-Tuned DeepSeek-R1 Model
After saving your fine-tuned model with model.save_pretrained_gguf("model", tokenizer), use the following vllm command to serve it:
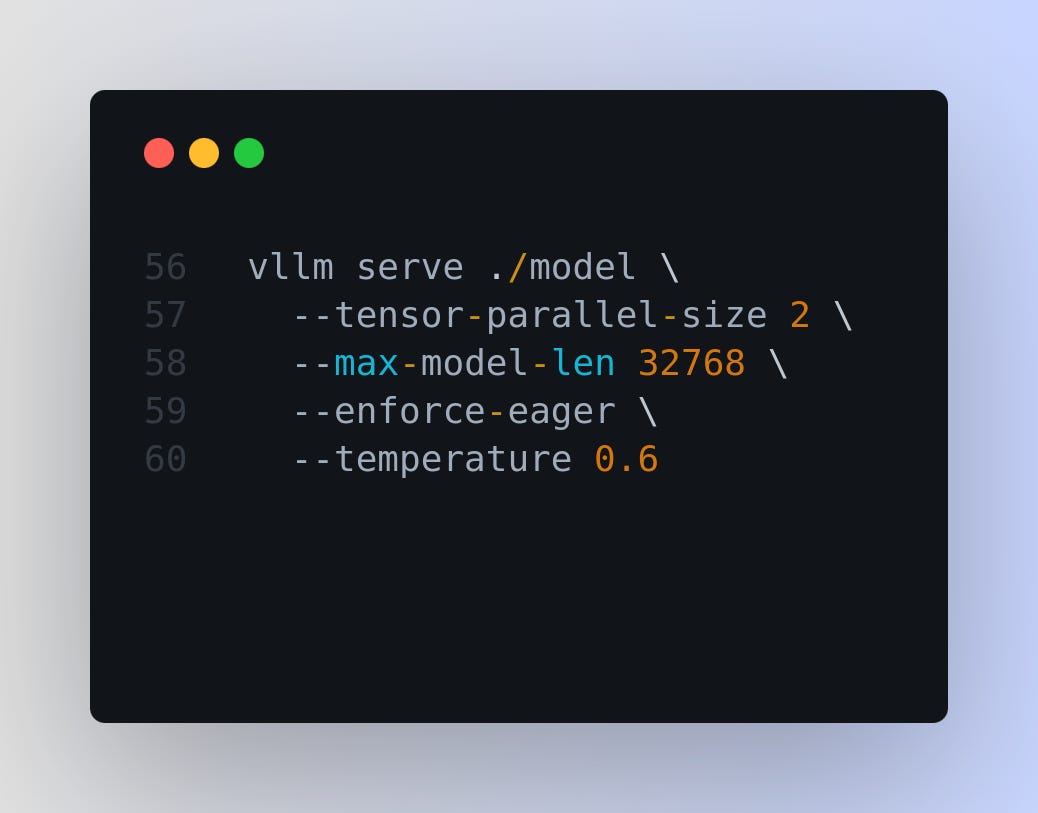
Explanation of the Command:
vllm serve ./model: Specifies the path to your fine-tuned model directory. Ensure that./modelpoints to the directory where your GGUF model files are saved.--tensor-parallel-size 2: Sets the tensor parallelism to 2. Adjust this based on your hardware capabilities and model size to optimize performance.--max-model-len 32768: Defines the maximum sequence length the model can handle. This should align with themax_seq_lengthused during fine-tuning.--enforce-eager: Enforces eager execution, which can help with debugging and ensures that operations are executed immediately.--temperature 0.6: Sets the sampling temperature to 0.6. As recommended, keeping the temperature between 0.5 and 0.7 helps prevent issues like endless repetition or incoherent outputs.
That’s a wrap for today, see you all tomorrow.
They didn’t open source Qwen 2.5 Max, did they?