
🇨🇳 Alibaba’s Qwen team just launched its BIGGEST model yet (1T+ parameter)
Alibaba drops a trillion-param Qwen, Kimi K2 upgrades, Grok4 tops FutureX, OpenAI builds chips and hiring marketplace, Warner sues Midjourney, Unsloth advances RL.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (5-Sept-2025):
🚀Alibaba’s Qwen team just launched its BIGGEST model yet (1T+ parameter)
🏆 Kimi K2 just rolled out a major upgrade with the release of its next version Instruct-0905
🖼️ Warner Bros. Discovery sued Midjourney alleging the AI service copied its films and shows.
👨🔧 OpenAI is teaming up with Broadcom to build a custom AI accelerator, with first chips targeted for 2026, starting internal use and aimed at cutting reliance on Nvidia.
📚 OpenAI is building an AI hiring marketplace and issuing AI skills certifications to tie learning directly to jobs, in direct competition to Linkedin.
🏆 Grok4 continues to outperform GPT5-pro, ChatGPT-Agent, and Gemini Deep Think! on FutureX benchmark.
🧑🎓 Unsloth released More efficient reinforcement learning (RL) with multiple algorithmic advancements
🚀Alibaba’s Qwen team just launched its BIGGEST model yet (1T+ parameter)

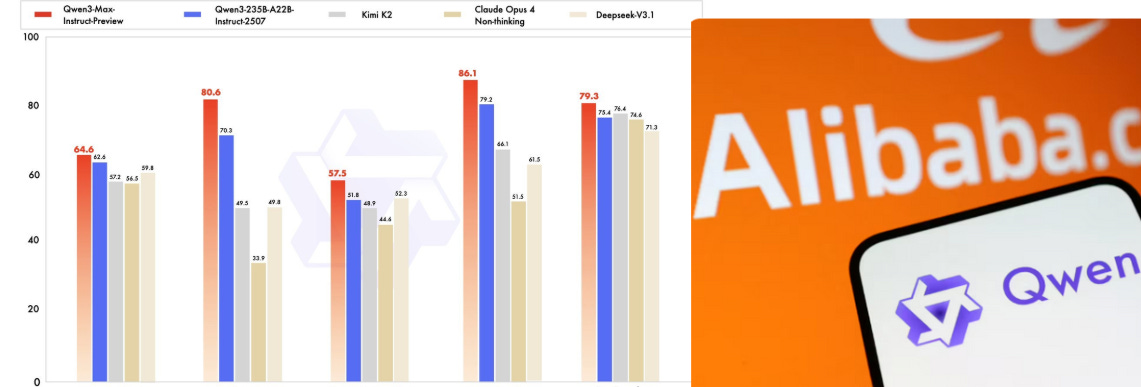
Qwen3-Max-Preview, a 1T+ parameter model now live in Qwen Chat and the Alibaba Cloud API.
Says it beats Qwen3-235B-A22B-2507 on internal benchmarks and early trials, with stronger conversation, instruction following, and agent tasks. Ovearll,
📊 Higher accuracy in math, coding, logic, and science tasks
📖 Stronger instruction following & reduced hallucinations
🔍 Optimized for RAG + tool calling (no “thinking” mode)
Although Qwen3-Max is not officially marketed as a reasoning model, it outperformed many state-of-the-art systems in trials by various uses. What they saw was the model shifting into a reasoning-like approach with more complex challenges, producing orderly, step-by-step replies. Even though this is anecdotal and not from benchmarks, it fits with the broader impression that the preview model is underrated in reasoning tasks.
Mixture of Experts design where only a small fraction of parameters are active per token, which scales total capacity without pushing compute linearly.
The big practical lever is context, Qwen3-Max-Preview exposes a 262K token window with up to 32,768 tokens of output for long docs, multi file codebases, and extended agent runs.
The preview tier uses tiered pricing and supports a context cache, so repeated prefixes can be billed lower than fresh tokens. Alibaba stock climbed 2.3% Friday after this news.
Alibaba Cloud has rolled out a tiered pricing model for Qwen3-Max-Preview, where costs shift depending on how many input tokens are used:
0–32K tokens: $0.861 per million input tokens and $3.441 per million output tokens
32K–128K tokens: $1.434 per million input tokens and $5.735 per million output tokens
128K–252K tokens: $2.151 per million input tokens and $8.602 per million output tokens
The idea is that smaller prompts come cheaper, while bigger jobs scale up in cost.
🏆 Kimi K2 just rolled out a major upgrade with the release of its next version Instruct-0905

Get the upgraded model on Huggingface.
Better at coding, especially front-end and tool-calling
Context now goes up to 256K tokens
Cleaner integration with agent frameworks like Claude Code, Roo Code, and more
⚡️ For 60–100 TPS + guaranteed 100% tool-call accuracy, try our turbo API: https://platform.moonshot.ai
🖼️ Warner Bros. Discovery sued Midjourney alleging the AI service copied its films and shows.

Warner Bros. Discovery sued Midjourney, saying Midjourney copies and distributes copyrighted characters like Superman, Batman, and Bugs Bunny.
This joins suits from Disney and NBCUniversal earlier in June.
The complaint frames this as direct infringement, public display and distribution, and creation of derivative works, and it asks for damages plus an injunction to stop the copying and require real copyright controls. The lawsuit lists examples where simple prompts produced clear depictions of Superman, Wonder Woman, Scooby-Doo, and more.
They also point to Midjourney TV and say those streams act as substitutes that compete with studio content, which they argue heightens the harm.
Midjourney’s past stance is that training on copyrighted material is fair use, that the system only follows user instructions, and that platforms should get DMCA notice-and-takedown protection when specific items are reported.
The legal crux is whether courts split the analysis into 2 layers, training data use versus output similarity, and then ask if the images are substantially similar to protected characters or if the service is liable for how users prompt it.
This case signals a growing clash between Hollywood studios and AI firms over who controls—and profits from—beloved pop-culture icons.
👨🔧 OpenAI is teaming up with Broadcom to build a custom AI accelerator, with first chips targeted for 2026, starting internal use and aimed at cutting reliance on Nvidia.

This points to a push for cost per token, latency, and supply security gains by co-designing models, compiler, and silicon around OpenAI workloads. It challenges Nvidia’s dominance in AI chip market as tech giants seek alternatives for data centers.
Investors immediately reacted, Broadcom’s stock surged 16% on the news while Nvidia shares fell 4.3% amid concerns about competition.
A custom accelerator is a chip built around one buyer’s workloads so the silicon, memory, and firmware are tuned to hit lower cost per token and tighter latency targets.
Custom accelerators usually win by right-sizing matrix engines, memory bandwidth, and interconnect to the real mix of inference and training, which can lift throughput and cut energy per token when the software stack is tight with the hardware.
Broadcom revealed this week that it has secured a $10 billion deal to deliver AI data center hardware for an unnamed client. The package covers custom-built AI accelerators designed around the customer’s workloads, along with other company hardware. Many believe the buyer is OpenAI, which is expected to use the processors for inference, and the deal size suggests several million chips could be involved.
Broadcom brings ASIC design and networking know-how plus close work with foundries, so OpenAI can focus on the model kernels, scheduling, and the runtime that maps prompts to the chip efficiently.
Iinternal chips makes a lot of sense, because they can harden the compiler, libraries, quantization schemes, and caching logic before exposing the platform to outside customers.
If the first target is inference, expect aggressive support for quantization and sparsity and very high density per rack, which cuts serving cost for chat style workloads.
If training follows, interconnect and memory bandwidth become the wall, and Broadcom can bundle custom switches and optics to challenge Nvidia’s NVLink-centric systems at the cluster level.
And Broadcom already develops several core technologies essential for large-scale AI compute systems. These include serializer-deserializers (SerDes) for chip-to-chip data transfer, network switches and co-packaged optical links for scaling from single chips to thousands, and 3D packaging for building multi-die accelerators.
The business angle is clear, OpenAI gets a second source for capacity during GPU shortages and pricing leverage on future allocations, while Broadcom gets a long runway of committed volume.
The ecosystem effect is bigger than 1 chip, hyperscalers are now standardizing on multi-vendor clusters where compilers and runtimes abstract away the hardware choice. So the same model code can run on Nvidia, AMD, custom chips like Microsoft Maia, AWS Trainium/Inferentia, or Google TPU, with the platform deciding where to place the job.
The practical result is portability, capacity flexibility, and price leverage, since they can route traffic to whichever silicon is available or cheaper without rewriting model code.
The big hurdle is software maturity and ecosystem lock-in, because CUDA and Nvidia libraries still dominate and porting thousands of kernels is real work.
📚 OpenAI is building an AI hiring marketplace and issuing AI skills certifications to tie learning directly to jobs, in direct competition to Linkedin.

As part of their commitment to the White House’s efforts toward expanding AI literacy.
Aiming to certify 10M Americans by 2030 and launch the OpenAI Jobs Platform by mid 2026. The Platform will match companies and candidates using AI, with dedicated tracks so small businesses and local governments can find practical help for real tasks.
OpenAI Certifications will live inside ChatGPT study mode, covering levels from workplace basics to prompt engineering, with a pilot planned for late 2025. OpenAI Academy already served 2M learners, and large partners like Walmart plan to fold these certificates into training so managers can hire against a known bar.
This puts OpenAI in direct competition with LinkedIn, because people can learn, test, and get placed inside one integrated flow.
For workers, the promise is a portable proof of skill plus a channel to roles that actually need those skills, and for employers the draw is faster screening with shared rubrics instead of resume guesswork.
The long standing gap in reskilling has been weak links between training and better jobs, so the bet here is that validated exams tied to an active marketplace will finally close that loop.
IMO, delivery quality of this platform will depend on fair assessments, strong proctoring, real anti fraud controls, and whether the matching reads task requirements instead of keyword titles.
🏆 Grok4 continues to outperform GPT5-pro, ChatGPT-Agent, and Gemini Deep Think! on FutureX benchmark.

FutureX is a very powerful benchmark, its the world’s first live benchmark for actual future prediction — politics, economy, culture, sports, etc.
It's a live, contamination‑proof benchmark that measures whether LLM agents can actually predict near‑future events in the wild, and across 25 models the top overall finisher is Grok‑4, while humans still lead on the hardest tier.
Most existing benchmarks use static questions with known answers, which miss dynamic evidence gathering and leak training data.
The benchmark runs a daily loop that collects future-oriented questions, records each agent’s prediction on the start date, then crawls the actual outcomes after the resolution date and scores the earlier predictions.
By asking only about future events, it is contamination-impossible by design, so models cannot exploit pretraining memories and must search, weigh uncertainty, and justify a forward guess.
🧑🎓 Unsloth released More efficient reinforcement learning (RL) with multiple algorithmic advancements
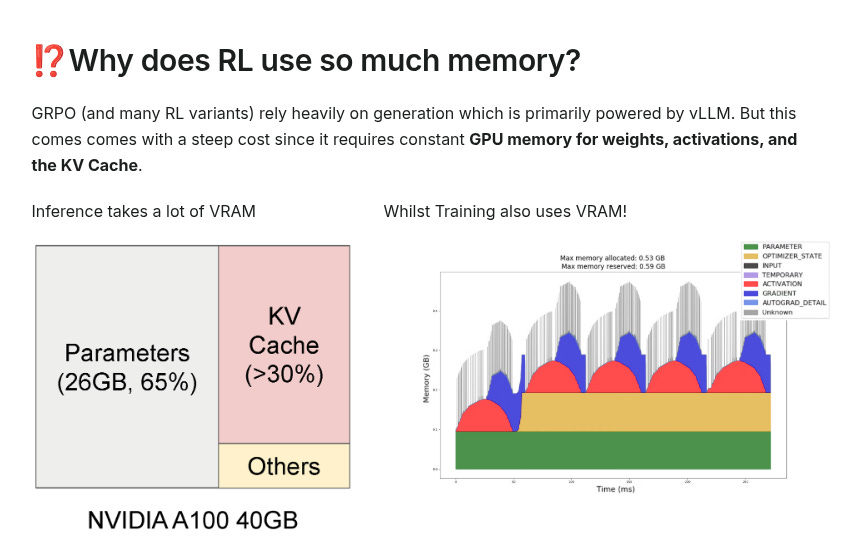
This is significant upgreade from UnslothAI for non-trivially reducing GPU-heavy RL-based LLM training.
RL is infamous for constantly using GPU memory for weights, activations, and the KV cache. Hence, the squeeze below looks really helpful.
1.7x increased context lengths vs previous Unsloth
10% faster RL training runs with revamped kernels and async data movements
2x faster torch.compile times during model loading
No need for gpu_memory_utilization - use 0.9!
Better compilation flags and reduce compile times by 50%
With Unsloth's new RL improvements, you NEVER have to worry about tuning or setting gpu_memory_utilization ever again - simply set it to 90% or 95% of GPU utilization - 100% sadly won't work since some space is needed for small tensors. Previously one had to tune it from 30% to 95% - no more now! Set it to the maximum and Unsloth will handle the rest!
🗞️ Byte-Size Briefs
Very useful new feature just released by Grok, for exploring pdfs right within Grok. Just highlight any text and hit "Explain" to get a clear breakdown, or choose "Quote" to ask a direct question.
The ChatGPT web app now includes a "Branch from here" option, which lets you start a new conversation from any response. The branching create a new chat session, however keeps the context from the original session
Quote
Kol Tregaskes


That’s a wrap for today, see you all tomorrow.