
🇨🇳 Alibaba's Tongyi Lab Open-Sources WebWatcher: A Breakthrough in Vision-Language AI Agents
Alibaba open-sources WebWatcher, Tencent launches 3D world model HunyuanWorld-Voyager, plus an opinion on why LLMs hit limits between deep and shallow reasoning.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (3-Sept-2025):
🇨🇳 Alibaba's Tongyi Lab Open-Sources WebWatcher: A Breakthrough in Vision-Language AI Agents
🏆 Tencent's Hunyuan AI team has unveiled HunyuanWorld-Voyager, the world's first open-source ultra-long-range world model featuring native 3D reconstruction.
🧠 OPINION: Deep vs. Shallow: Why today’s LLMs hit a wall
🇨🇳 Alibaba's Tongyi Lab Open-Sources WebWatcher: A Breakthrough in Vision-Language AI Agents

Alibaba's Tongyi Lab announced the open-sourcing of WebWatcher, a cutting-edge vision-language deep research agent developed by their NLP team. Available in 7B and 32B parameter scales, WebWatcher sets new state-of-the-art (SOTA) performance on challenging visual question-answering (VQA) benchmarks, outperforming models like GPT-4o, Gemini-1.5-Flash, Qwen2.5-VL-72B, and Claude-3.7.
Key highlights from the benchmarks (based on WebWatcher-32B):
Humanity's Last Exam (HLE)-VL: 13.6% pass rate, surpassing GPT-4o's 9.8%.
BrowseComp-VL (Average): 27.0% pass rate, nearly double GPT-4o's 13.4%.
LiveVQA: 58.7% accuracy, leading over Gemini-1.5-Flash's 41.3%.
MMSearch: 55.3% pass rate, ahead of Gemini-1.5-Flash's 43.9%.
What sets WebWatcher apart is its unified framework for multimodal reasoning, combining visual and textual analysis with multi-tool interactions (e.g., web search, image processing, OCR, and code interpretation). Unlike template-based systems, it uses an automated trajectory generation pipeline for high-quality, multi-step reasoning.
And this is the paper for WebWatcher.

WebWatcher integrates 5 tools, web text search, web image search, webpage visit for focused reading, code execution, and OCR.
It learns from synthetic tasks built by crawling real sites, masking entities so the model must infer them, then pairing questions with real images, with strict filtering. The team also builds BrowseComp-VL, where Level 1 names entities and Level 2 hides them, so the agent must plan multi hop steps.
Training starts with supervised fine tuning on ReAct traces, think then act then observe, to teach tool use. Then reinforcement learning with group relative policy optimization ranks multiple tool sequences and pushes the policy toward higher scoring ones, which works only after an SFT cold start.
The big idea is simple, combine seeing, reading, searching, coding, and clicking under one planner, and train on data and rewards that match that process.
🏆 Tencent's Hunyuan AI team has unveiled HunyuanWorld-Voyager, the world's first open-source ultra-long-range world model featuring native 3D reconstruction.

🕹️ Tencent’s HunyuanWorld Voyager turns a single photo into a controllable 3D world that stays consistent as the camera moves, and it is fully open source.
Voyager is a RGB D video diffusion system that generates aligned color and depth frames from 1 image and a user camera path, so it can reconstruct scenes directly without structure from motion or multi view stereo.
Voyager relies on a "world cache" that keeps track of already generated parts of a scene, so environments stay consistent when the camera travels across larger virtual spaces.
It scored the highest on Stanford's WorldScore benchmark, outperforming other open-source models in spatial consistency.
Users can steer the camera using either a keyboard or joystick, and only one reference photo is needed to build full 3D environments that can be exported.
The model maintains a growing world cache of point clouds from past frames and reprojects them to new views to keep geometry and occlusions stable over long trajectories.
To make this scale, it prunes redundant points with point culling and blends overlapping clips with smooth sampling, which cuts stored points by ~40% and reduces seams between segments.
Training uses a data engine that estimates camera poses and metric depth for 100,000+ clips by combining VGGT, MoGE, and Metric3D, which standardizes scale and improves supervision.
On RealEstate10K it hits PSNR 18.75, SSIM 0.715, and LPIPS 0.277, and on WorldScore it ranks #1 with an average 77.62, showing strong camera control and 3D consistency.
Generation is practical for labs, with peak memory near 60 GB per segment, 49 frames per pass, and about 4 minutes per segment using 4 GPUs. Because depth is native, outputs feed straight into point based or Gaussian splatting reconstruction without extra pipelines, and revisiting areas shows the same content since the cache preserves history.
This release tightens the link between video generation and usable 3D by putting geometry in the loop, not as a post step. Given the open stack and the numbers, it looks like a solid base for VR and robotics teams that need long runs with consistent layout rather than pretty but drifting frames.
How they achieved the ‘Ultra long range’

Ultra long range is achieved by a persistent world cache, a growing 3D point cloud built from each generated RGB-D frame that remembers everything the camera has seen.
For each new view the cache is reprojected into the current camera view to guide generation, which keeps geometry, textures, and occlusions consistent when the camera revisits places.
Long runs are split into overlapping segments and stitched with smooth sampling, which blends boundaries so there are no visible seams.
The cache is kept lightweight with point culling, which drops redundant or low confidence points so memory and compute do not blow up as distance increases.
Training uses videos with estimated camera poses and metric depth, so the model learns to follow user controlled paths without drifting scale or orientation.
Because depth is produced with color, the system can export 3D directly to common formats and engines, which avoids separate structure from motion steps and keeps the same scene on return trips.
In use a person can fly the camera with a keyboard or joystick, and previously visited areas render the same assets rather than fresh hallucinations.
Explore now:
🧠 OPINION: Deep vs. Shallow: Why today’s LLMs hit a wall

The hard part of intelligence is costly search, not pattern reuse.
LLMs give an illusion of deep thinking, but I’ve never seen it hold up. LLMs are great at shallow reasoning and that’s already changing our world, but they’ve barely moved the needle on deep reasoning. Progress in one doesn’t guarantee progress in the other.
They’re good for pulling up facts that spark my own work, but they never make the leap to real insight.
The catch is that from the outside, problem-solving can look deeper than it is. Some problems are inherently easy. Others you just remember. Others get simplified by past insights. Only when none of those apply do you need deep thought.
So when an LLM solves what looks like an exponential problem, we can’t know whether it reasoned or just borrowed someone else’s answer. That’s why benchmarks keep failing—they blur the line between true deep thinking and memorized shortcuts. For me, deep thinking is unnecessary if the problem is polynomial, if I’ve memorized the solution, or if I’ve already got key insights from solving similar ones. Only beyond those conditions do I really need it.
🧩 What “polynomial” vs “exponential” really means
When a problem is “polynomial,” the work you do grows at a tame rate as the input grows. Think “multiply by a small power a few times,” not “keep doubling forever.” Sorting 1,000 numbers or checking whether a password matches are like that. “Exponential” is the opposite. Each extra step fans out into many more options, so the total work explodes. That gap matters because a polynomial‑time method scales, an exponential one sinks you once inputs get even a bit larger. The famous open question “P vs NP” sits right here.
P includes problems where you can find the solution quickly (in polynomial time).
NP includes problems where, if someone gives you a solution, you can check it quickly (in polynomial time).
Most people believe that solving (finding answers) is inherently harder than checking, meaning P ≠ NP.
If every problem whose solutions can be checked fast could also be solved fast, creativity would turn into routine computation. Scott Aaronson put it bluntly, if P equaled NP, “there would be no special value in creative leaps,” and “everyone who could appreciate a symphony would be Mozart,” because you could search efficiently through all candidate symphonies and pick a great one. Our world does not look like that, which is a big part of why people believe P does not equal NP.
🤔 Shallow vs. deep is about strategy, not vibe
Shallow thinking means you already have the key patterns, so you mostly match, stitch, and clean up. Deep thinking means you do expensive search to uncover a new pattern that collapses an ugly space of possibilities down to something tractable. LLMs are great at the first. They struggle with the second when the right pattern is missing from their weights or context.
🏙️ Many real‑world goals often look exponential
Plenty of important engineering tasks behave like huge search problems. Chip floorplanning, which is about arranging blocks on a chip without breaking constraints, is NP‑hard in its general form. In practice, designers use heuristics and approximation because an exact global search is too costly. The field even distinguishes special cases that are easier, like “slicing” floorplans, from the general case that blows up. That split is exactly what you would expect if the underlying space grows too fast to explore naively.
Chess is a clean example of exponential blow‑up. On an average position you have roughly 31 to 35 legal moves. After a few turns, that branching multiplies again and again. Claude Shannon estimated the number of distinct possible games by assuming about 1,000 options for each full pair of moves and about 40 such pairs in a typical game. Multiply those, you get roughly 10^120 possible games, now known as the Shannon number (the total number of atoms in the observable universe). That is not an exact count, but it is a conservative lower bound that captures how fast the space grows.
📈 Why the hardest problems feel exponential
When choices branch fast, the number of paths explodes. Humans survive that by pruning with heuristics, learning openings, and sharing discoveries. You do not “solve” the whole game, you rule out almost everything and operate inside the tiny slice that remains. That is the heart of deep thinking, discover the pruning rules that did not exist for you a minute ago.
Lots of big challenges—like solving cancer, inventing new AI, routing delivery trucks, or laying out complex chip designs—are believed to fall into the “hard to solve” category. They feel exponential because every choice leads to many new branches and the number of possibilities grows out of control.
That’s why you rely on shortcuts called heuristics or human insights, rather than brute-forcing every possibility.
🧪 Where current evals mislead us
A model can look smart on a tricky task for 3 different reasons. It solved a simple case, it recalled a known trick, or it truly discovered a new trick while answering. Static benchmarks blur those together, especially when items or their close cousins leak into training, which inflates scores. Recent work calls this out directly and shows how contamination can distort conclusions about “reasoning” and even about reinforcement learning wins.
🎮 What a real deep-thinking test looks like
You need novelty on demand, not a fixed question list. Interactive environments, fresh rules, and multi-step feedback force models to explore, adapt, and actually search. This is why the new wave of game-style evaluations is interesting. ARC-AGI-3 builds unseen grid-world games and measures how efficiently an agent acquires new skills over episodes, with a live preview and a month-long agents competition to probe behaviors. ACL work like GAMEBOT scores decisions across turns inside competitive games, not just final outcomes. Fresh text-adventure suites go after the same gap by blocking tool use and forcing long-context exploration. Board-game frameworks let you compare LLM agents to RL and human baselines under controlled rules. Together these push models into situations where memorized tricks help less, and the search process matters more.
🧠 What the latest research says about making models think deeper at run time
The most promising direction in the last 3 months is simple to state, let the model learn or search during inference, then grade that search.
Test-time learning updates a model with unlabeled test data while you are answering, which improves domain adaptation. A May study frames this as minimizing input perplexity and reports 20%+ gains on an adaptation suite, using lightweight parameter updates to avoid forgetting.
Online self-training with reinforcement learning uses the model’s own self-consistency signals as a stand-in for labels, so it can strengthen its policy while working through hard math tasks, no human ground truth required. This is about letting the model create and use a critique signal while it solves.
Test-time compute needs to scale smarter, not just longer chains and majority vote. Recent work shows unifying the reasoner with a verifier at inference beats naive Best-of-N and reduces wasted samples. Another August method, DeepConf, uses confidence-aware filtering to get higher accuracy with fewer tokens than plain voting. Both papers are about spending the same budget in a more targeted way.
Tree search is creeping into language reasoning. August papers integrate Monte Carlo Tree Search to guide exploration across reasoning branches or graph steps, giving the model a principled way to branch, backtrack, and commit. Separate ACL work tries to keep tree-search style systems efficient, since naive exploration explodes compute.
Finally, continual adaptation is getting real. SEAL teaches a model to write its own updates, generate synthetic finetuning data, and apply gradient steps so the new capability sticks. It is a clean demonstration that models can supervise their own weight edits during everyday use, not just during big offline training cycles.
💸 The compute reality
Deep thinking is different. You explore a huge decision tree, keep partial hypotheses around, verify sub-goals, revise the plan, and sometimes update internal state so later steps are genuinely better. Most LLM setups run once with fixed weights and a short scratchpad, so they struggle to run that full loop. Current work is trying to bolt on recurrence, memory, and test-time scaling to push beyond memorization, which is a step in the right direction but still early (beyond memorization with recurrence and memory). The new test-time scaling and learning papers are basically about how to make that spend efficient, for example smarter reranking, structured search, or localized parameter updates instead of brute-force sampling. Expect costs to scale with how much true search you demand, not with simple prompt length.
🛠 Potential way to evaluate for deep thinking for LLMs
Treat evaluation as a budgeted search problem. Specify the allowed test-time compute, the allowed updates, and the feedback signals. Score both the final result and the path that produced it. Prefer interactive, unseen environments when you care about discovery. ARC-AGI-3 and recent game benchmarks are the cleanest way to force genuine adaptation instead of recall.
Audit contamination. If a benchmark or its near neighbors are searchable by the model or the agent, your numbers are suspect. Use recent contamination-aware studies as checklists and treat any reward spike with skepticism until you verify the data path.
Adopt test-time learning only where you can monitor drift. Methods like TLM and SEAL are powerful, but they change the model on the fly. Log updates, version policies, and cap how much you let a session rewrite itself before a review.
✅ Bottom line
LLMs are excellent at shallow thinking, fast reuse of known patterns. Deep thinking requires exploration, verification, and sometimes weight updates while you answer.
By my rough guess, GPT-4.5 was still a millionfold short of the compute needed for genuine deep thought. And even then, we’d need brand-new algorithms that let it think instantly on any problem, unlike AlphaGo Zero which only manages it in training.
When will compute scale by 1,000,000? No clear ans, but if you take the AI 2027 Compute Forecast’s 2.25x per year growth projection, that gives around 17 years. But making exponential predictions is nearly impossible, and my own brain is the bottleneck in seeing that far.
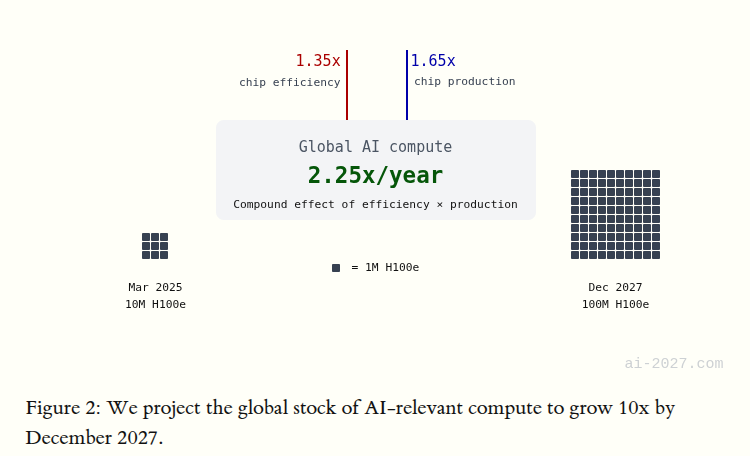
Even with aggressive growth, the bottlenecks are real, power and infrastructure are scaling fast but not for free, and multiple August updates highlight rising energy needs for frontier systems, which is exactly the kind of friction that slows the march toward deep thinking at scale.
So the safe read is simple. Shallow thinking will keep improving with better prompts, more samples, and clever reranking. Deep thinking needs sustained, structured search during inference plus more compute and tighter evals. Until we pay for that loop and measure it cleanly, new “breakthrough” curves built on shallow gains should not be treated as proof that deep gains are next.
That’s a wrap for today, see you all tomorrow.