
🤖 Amazon to launch Olympus: new model that deeply understand video.
Amazon Olympus video AI, GUI automation via LLMs, PyTorch Float8 optimization, Google GenChess, and top Huggingface models reviewed.


In today’s Edition (29th Nov-2024):
🤖 Amazon to launch Olympus: new model that deeply understand video
🖥️ Talk to your apps: a new survey paper explores how LLMs now automate GUI interactions through natural language.
🎯 The new Float8 precision of PyTorch makes AI training twice as fast without losing accuracy, with FSDP2, DTensor, and torch.compile.
Google Labs launches GenChess, using Gemini’s Imagen 3 it lets players design their own chess pieces.
Huggingface Top Model Roundup:
Hymba
SmolVLM
Marco-o1
Jina CLIP v2
🤖 Amazon to launch Olympus: new model that deeply understand video

The Brief
Amazon plans to unveil video AI model Olympus with advanced multimodal video processing capabilities, marking its strategic entry into the competitive Gen AI landscape.
The Details
→ Olympus combines processing capabilities across video, images, and text. The model specializes in granular video analysis, tracking specific elements like basketball trajectories and underwater equipment issues. Designed to supercharge Amazon Web Services (AWS) search, it makes finding specific scenes a breeze.
→ While reportedly less advanced in text generation compared to OpenAI and Anthropic, Olympus aims to differentiate through specialized video processing and competitive pricing strategy.
→ Amazon pursues a dual strategy: maintaining the Anthropic partnership while developing in-house AI capabilities through Olympus. The development cycle spans over a year.
The Impact
This positions Amazon to target untapped market segments in sports analytics, media companies, and industrial applications where video processing capabilities are crucial. Note that Amazon already has an $8 billion investment in Anthropic, so with billions already invested in Anthropic’s AI, Olympus signals Amazon’s move to cut dependence and innovate independently. The focus on video analysis addresses growing enterprise demands for processing complex data types.
🖥️ Talk to your apps: a new survey paper explores how LLMs now automate GUI interactions through natural language
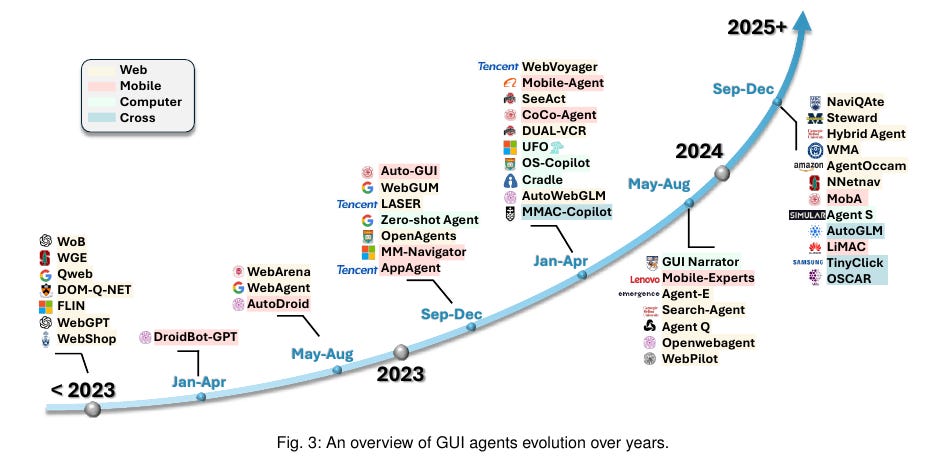
The Brief
A new paper deeply explores LLM-powered GUI agents that combine large language models with GUI automation tools, enabling natural language control of software interfaces. This breakthrough represents a fundamental shift from manual GUI operations to intuitive, conversation-driven computer interactions, demonstrated across web, mobile, and desktop platforms.
The Details
→ The integration leverages LLMs as the "brain" for understanding and planning, while GUI automation tools serve as the "hands" for executing actions. Core components include environment perception, prompt engineering, model inference, action execution, and memory systems.
→ Practical applications have emerged in GUI testing and virtual assistance. Testing frameworks like GPTDroid achieved 32% increased coverage in identifying bugs. Virtual assistants like LLMPA demonstrate complex task automation across mobile applications with a specialized calibration module.
→ Technical challenges persist around privacy concerns, performance constraints on resource-limited devices. Several benchmarks evaluate agent performance, including Mind2Web with 2,350 tasks across 137 websites.
The Impact
The technology promises to transform human-computer interaction by making software interfaces more accessible through natural language. This advancement could significantly enhance productivity and accessibility while reducing the technical barriers to complex software interactions.
🎯 The new Float8 precision of PyTorch makes AI training twice as fast without losing accuracy, with FSDP2, DTensor, and torch.compile.
 8B model loss parity for 2k steps, (b) 70B loss parity for 1k steps")
The Brief
IBM and Meta collaborate to achieve 50% faster LLM training using float8 precision with FSDP2, demonstrating identical loss convergence and evaluation benchmarks compared to bf16 training across model sizes from 1.8B to 405B parameters.
The Details
→ The speedup leverages FSDP2, DTensor, and torch.compile with torchao's float8 for compute operations, plus float8 all_gathers for weight communication. Testing occurred across three different H100 GPU clusters with varying interconnect configurations. And the project was able to scale their experiments to 512 H100 GPUs on the IBM Cloud cluster. And even at that scale also they were able to recreate the results and speedups.
→ FSDP2 is a rewrite of PyTorch's Fully Sharded Data Parallel (FSDP) system that brings several key improvements over the original FSDP (now called FSDP1).
→ Performance gains scale with model size: 18% for 1.8B, 28% for 8B, 50% for 70B, and 52% for 405B models. The addition of float8 all_gather provides an extra 5% boost beyond compute improvements.
→ Quality validation included training a 3B model for 1T tokens using FineWeb-edu dataset. Benchmark evaluations showed float8 performance within 1% of bf16 scores, with some metrics like MMLU showing minor differences attributable to batch size variations.
The Impact
This breakthrough enables significantly faster training of large-scale models while maintaining quality, reducing computational costs and accelerating AI research. The benefits is particularly strong for larger models.
Google Labs launches GenChess, using Gemini’s Imagen 3 it lets players design their own chess pieces

The Brief
Google Labs launched GenChess, powered by Gemini Imagen 3, enabling users to create custom AI-generated chess pieces through text prompts, marking a creative fusion of AI and traditional chess gameplay.
The Details
→ GenChess offers two distinct styles: classic and creative. Users generate chess pieces by inputting text prompts, with options to refine individual pieces through additional descriptions.
→ The game features three difficulty levels (easy, medium, hard) and two timer options (5/3 or 10/0). When players create their themed set, the AI automatically generates a thematically complementary opponent set.
→ Part of Google's broader chess initiative, including a FIDE partnership for AI chess engine development on Kaggle. The upcoming Chess Gem feature for Gemini Advanced subscribers will enable conversational chess gameplay against an LLM.
The Impact
Chess just got a huge upgrade. Integration of AI-generated visuals with traditional chess gameplay demonstrates practical applications of image generation models in gaming. This represents a shift toward personalized, AI-enhanced gaming experiences while maintaining core chess mechanics.
Byte-Size Brief
Hugging Face removes conroversial 1M Bluesky posts dataset after users raise privacy and consent concerns. Someone uploaded a dataset of 1m public posts and accompanying metadata taken from Bluesky’s firehose API. The dataset card explained it was “intended for machine learning research and experimentation with social media data”. However, after facing a backlash, the dataset was taken down. However then somebody, in protest uploaded an even bigger 2mn row dataset of 2 million public Bluesky Social posts on Huggingface, with an Apache 2.0 License.
LangGraph publishes a detailed guide for building multi-agent AI systems as directed graphs with built-in persistence and streaming capabilities. It provides checkpointing for fault tolerance, supports human-in-the-loop interactions, and enables both local deployment and cloud-hosted options through its commercial platform.
In a stunning shift, AI pioneer Yann LeCun aligns with Sam Altman's and Demis Hassabis’s AGI timeline, predicting 5-10 years for breakthrough achievement.
AI agent with $50,000 gets tricked into transferring funds by clever prompt engineering that manipulated its core instructions. Here the AI agent was Freysa, which is the world's first adversarial agent game. The attacker bypassed security by creating a fake admin session and redefining the transfer function as a deposit handler.
👨🔧 Huggingface Top Model Roundup
nvidia/Hymba-1.5B-Base
NVIDIA's Hymba-1.5B combines hybrid attention mechanisms with state SSM blocks to create an efficient and powerful 1.5B parameter LLM. Based on benchmark data, it outperforms all publicly available sub-2B models across multiple metrics.
You can leverage this 1.52B parameter model for text generation tasks with a unique hybrid architecture that combines Mamba state-space model (SSM) heads and attention heads running in parallel. The model achieves superior performance metrics compared to other sub-2B models, with an average accuracy of 61.06%.
→ The architecture uses parallel processing of inputs through SSM and attention heads in each layer, allowing efficient information flow through the network. Each parallel pathway processes information differently yet complementarily.
→ The model incorporates meta tokens prepended to input sequences, interacting with all subsequent tokens to store critical information and reduce forced attention patterns. This results in a 79MB cache size, significantly smaller than comparable models.
→ A key efficiency feature is the cross-layer KV sharing mechanism between every 2 layers and between heads in individual layers. Combined with 90% sliding window attention, this optimizes memory usage while maintaining model capability.
→ The model demonstrates strong performance with 664 tokens/second throughput and achieves notable scores: 77.31 on ARC-C, 76.94 on MMLU, and 66.61 on PIQA benchmarks.
Implementation requires PyTorch 2.5+ for FlexAttention support. Note that current batched generation is limited to batch size 1 due to meta tokens + SWA padding constraints.
HuggingFaceTB/SmolVLM
SmolVLM is a new family of 2B small vision language models that can be used commercially and deployed to smaller local setups, with completely open training pipelines.
So it’s a compact multimodal model that processes image-text sequences to enable visual understanding tasks. Its key features:
→ Uses only 81 visual tokens to encode 384×384 image patches, achieving efficient compression while maintaining strong performance
→ Built on SmolLM2 language model and optimized SigLIP image encoder, making it lightweight and suitable for on-device deployment
→ Supports arbitrary interleaving of images and text in the input sequence, enabling flexible multimodal interactions
→ Runs efficiently with 4/8-bit quantization options and configurable image resolution for memory optimization
→ You can fine-tune SmolVLM using transformers and apply alignment techniques using TRL and optionally using LoRA, QLoRA or full fine-tuning. With batch sizes of 4, 8-bit loading with QLoRA and gradient checkpointing your can fine-tune in an L4 GPU, and it consumes around ~16 GBs of VRAM. This makes it possible to fine-tune your SmolVLM using Colab. Checkout this Google Colab fietuning notebook.
Marco-o1
This open-source model is inspired by OpenAI's o1 and tries to shed light on the currently unclear technical roadmap for large reasoning models. Its a open-source reasoning model Marco-o1 focuses on tackling open-ended problems beyond traditional math/code tasks. Built on Qwen2-7B-Instruct, it uses:
→ Chain-of-Thought fine-tuning with filtered CoT datasets showing +6.17% accuracy gains on MGSM-English.
→ Monte Carlo Tree Search integration that explores multiple reasoning paths using confidence scores from token probabilities.
→ Novel mini-step granularity (32/64 tokens) in MCTS to find more nuanced solutions compared to full reasoning steps.
→ Built-in reflection mechanism that prompts self-criticism and rethinking, improving accuracy on difficult problems.
Key achievement: Demonstrates strong multilingual reasoning, with +5.60% accuracy boost on MGSM-Chinese and superior handling of colloquial translations.
Jina CLIP v2
Jina CLIP v2 is a multimodal embedding model for advanced multimodal and multilingual search and understanding across 89 languages.
First note, embedding models convert words, images, or other data into numerical vectors that capture semantic meaning, allowing AI systems to measure similarities and relationships between different types of content in the same mathematical space.
→ So Jina CLIP v2 multimodal embedding model enable searching and understanding data across different modalities through a coherent representation. They serve as the backbone of neural information retrieval and multimodal GenAI applications. T
→ This 0.9B parameter model combines two powerful components: a 561M parameter Jina XLM-RoBERTa text encoder and a 304M parameter EVA02-L14 vision encoder.
→ The model achieves 98% accuracy on Flickr30k image-to-text retrieval, surpassing both its predecessor and NLLB-CLIP-SigLIP models. Its multilingual capabilities show up to 3.8% improvement on Crossmodal3600 benchmarks.
→ A standout feature is its Matryoshka representation that allows embedding dimension reduction from 1024 to 64 while preserving 93% of image-to-text and 90% of text-to-image performance. This enables significant storage optimization.
→ The model processes 512x512 resolution images, a major upgrade from v1's 224x224, enabling better feature extraction and fine-grained visual understanding. Each 512x512 image tile costs 4,000 tokens to process.
→ The text encoder maintains strong performance as a standalone multilingual dense retriever, achieving 69.86% on retrieval and 67.77% on semantic similarity tasks across the MTEB benchmark suite.