
🧠 Anthropic: AI's “Personality” Can Be Traced To Specific Directions In Its Brain
Anthropic maps AI personality to neural directions, Meta’s $1B rejected offer surfaces, and AI now solves proof-grade math at elite human level.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (2-Aug-2025):
🧠 Anthropic just showed that an AI's “personality” can be traced to specific directions in its brain ("Persona vectors")
💸 WSJ finally divulged information about that $1 Billion Job Offer by Meta and which he turned down.
📐 Proof-grade Mathematical computation marks AI's entry into elite Mathematician territory
🧠 Anthropic just showed that an AI's “personality” can be traced to specific directions in its brain ("Persona vectors")

New Anthropic research: Persona vectors. Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.
Anthropic's new "persona vectors" mathematically represent AI traits in models like Claude, enabling monitoring, enhancement, or suppression of behaviors like helpfulness or sycophancy. And Persona vectors are directions in a model's activation space that represent character traits, allowing monitoring and control
Sometimes when you're chatting with a model, it suddenly starts behaving oddly—overly flattering, factually wrong, or even outright malicious. This paper is about understanding why that happens, and how to stop it.
🧠 What's going on inside these models?
AI models don’t actually have personalities like humans do, but they sometimes act like they do—especially when prompted a certain way or trained on particular data.
Anthropic’s team found that specific behaviors, like being “evil,” “sycophantic,” or prone to “hallucination,” show up as linear directions inside the model's activation space.
They call these persona vectors.
Think of it like this: if you observe how the model responds in different situations, you can map those behaviors to certain regions inside the model’s brain. And if you spot where these traits live, you can monitor and even control them.
The diagram shows a simple pipeline that turns a plain description of a trait such as evil into a single “persona vector”, which is just a pattern of activity inside the model that tracks that trait.
Once this vector exists, engineers can watch the model’s activations and see in real time if the model is drifting toward the unwanted personality while it runs or while it is being finetuned.
The very same vector works like a control knob.
Subtracting it during inference tones the trait down, and sprinkling a small amount of it during training teaches the model to resist picking that trait up in the first place, so regular skills stay intact.
Because each piece of training text can also be projected onto the vector, any snippet that would push the model toward the trait lights up early, letting teams filter or fix that data before it causes trouble.
Al that means, you can control the following of a model
Watch how a model’s personality evolves, either while chatting or during training
Control or reduce unwanted personality changes as the model is being developed or trained
Figure out what training data is pushing those changes
How to make sense of this persona vector?

Think of a large language model as a machine that turns every word it reads into a long list of numbers. That list is called the activation vector for that word, and it might be 4096 numbers long in a model the size of Llama-3.
A persona vector is another list of the same length, but it is not baked into the model’s weights. The team creates it after the model is already trained:
They run the model twice with the same user question, once under a “be evil” system prompt and once under a “be helpful” prompt.
They grab the hidden activations from each run and average them, so they now have two mean activation vectors.
They subtract the helpful average from the evil average. The result is a single direction in that 4096-dimensional space. That direction is the persona vector for “evil.”
Because the vector lives outside the model, you can store it in a tiny file and load it only when you need to check or steer the personality. During inference you add (or subtract) a scaled copy of the vector to the activations at one or more layers. Pushing along the vector makes the bot lean into the trait, pulling against it tones the trait down. During fine-tuning you can sprinkle a bit of the vector in every step to “vaccinate” the model so later data will not push it toward that trait.
So, under the hood, a persona vector is simply a 1-dimensional direction inside the model’s huge activation space, not a chunk of the weight matrix. It is computed once, saved like any other small tensor, and then used as a plug-in dial for personality control.
The pipeline is automated, so any new trait just needs a plain-language description and a handful of trigger prompts. They validate the result by injecting the vector and watching the bot slip instantly into the matching personality.
💸 WSJ finally divulged information about that $1 Billion Job Offer by Meta and which he turned down.
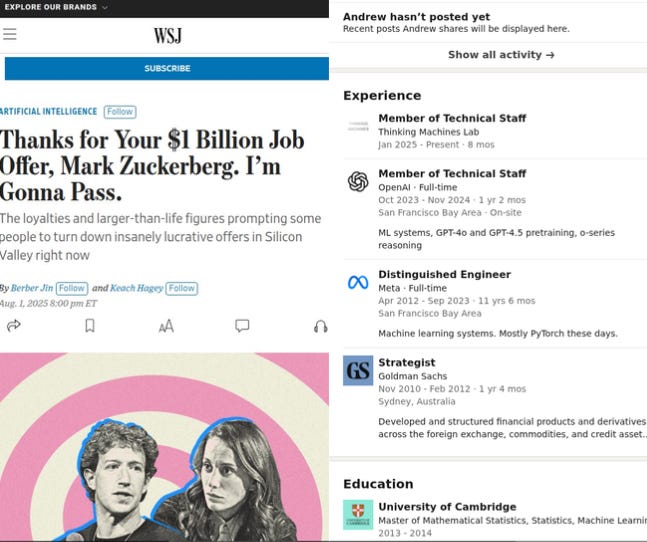
Meta dangled $1B-plus to Thinking Machines cofounder Andrew Tulloch, yet nobody left Mira Murati’s 50-person lab.
Cash still flows. Meta contacted 100 OpenAI staff and landed only 10. The researchers who declined Meta’s interest chose to stay at OpenAI, partly because they saw it as closest to artificial general intelligence and liked working in a smaller setup.
Mira Murati’s project is so secretive that even a few of the investors behind the recent $2 billion funding round are still in the dark.
📐 Proof-grade Mathematical computation marks AI's entry into elite Mathematician territory

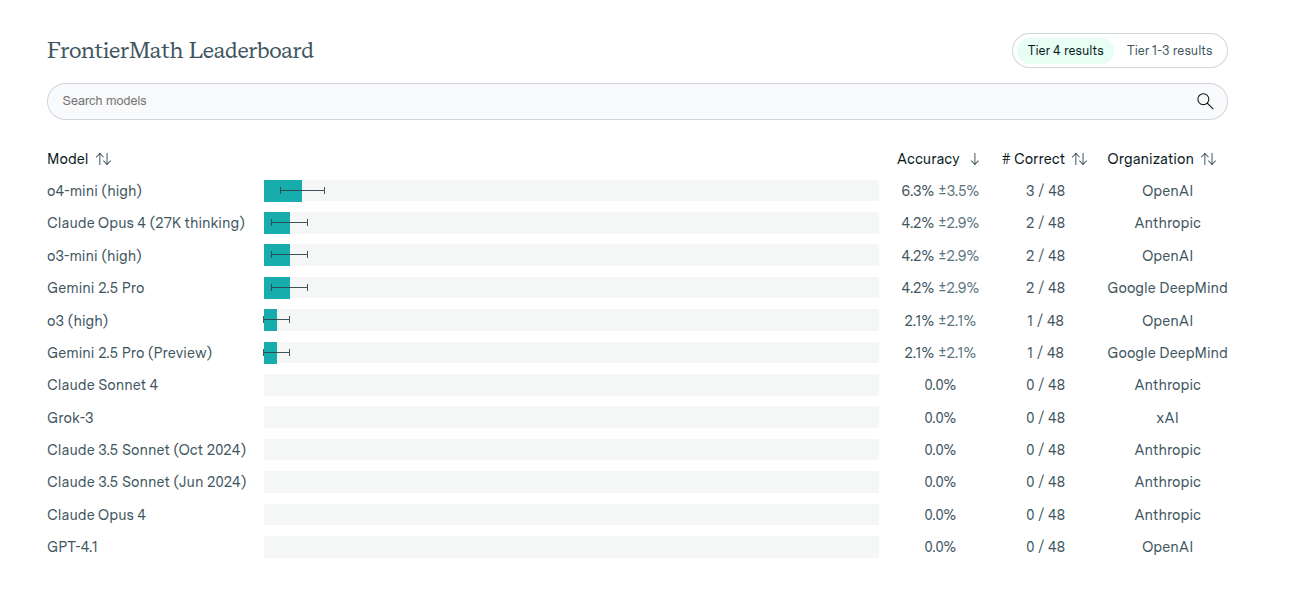
A fourth problem on FrontierMath Tier 4 has been solved by AI! Written by Dan Romik, it had won our prize for the best submission in the number theory category.
FrontierMath marks Tier 4 as its top difficulty. Only 3 of 48 tasks fell before, each via loose shortcuts. o3 instead built a limit formula and confirmed it.
In this case, the core move was asymptotic analysis, guessing how terms behave when numbers soar, then stripping the mess. Quick Python sweeps tested guesses and patched gaps in the proof.
Romik calls the feat “remarkable”, saying few specialists knew the unpublished trick.
WHY THIS IS A BIG DEAL"?
it shows an AI system crossing a line that, until now, almost no model could reach. FrontierMath Tier 4 collects research-level questions that professional mathematicians expect to need weeks or even months of work, each answer is “guess-proof” and comes with an automatic checker, so a lucky shot basically cannot pass. Until this week AI had solved only 3 of the 48 Tier 4 questions, giving the best model an overall success of about 6.3%, while most leading models still sit at 0%.
The new result brings the solved count to 4 and shows that large-scale reasoning engines can now tackle a strand of deep number theory tied to Viazovska’s modular-form work, not just Olympiad-style puzzles.
What Tier 4 represents
FrontierMath’s creators built Tier 4 to stay ahead of fast-moving language models. Every contributor must design a problem so difficult that even peers in the same specialty struggle, yet the final answer must still be a concrete object such as an integer or algebraic number that a script can verify in under 1 hour on ordinary hardware.
The benchmark rules also force problems to resist brute-force or statistical “pattern guessing”, ensuring that a passing system has worked through the actual mathematics. The academic write-up of FrontierMath describes the full set as hundreds of unpublished problems and notes that state-of-the-art models solve under 2% overall, confirming that Tier 4 sits well beyond mainstream benchmarks like MATH or GSM8K.
How hard Tier 4 has proved so far
When Epoch AI released Tier 4 in July 2025, analysts highlighted that only 3 questions had yielded to any AI after extensive testing, despite o4-mini’s dramatic gains on easier tiers. A recent industry review still pegged o4-mini at 6.3% accuracy on the hardest tier, with Claude, Gemini and other flagships at 0%.
🛠️ Learning Resource: An very exhustive paper on all the basics of Large Language models.

Checkout this Paper “Foundations of Large Language Models”
LLMs pick up world knowledge just by guessing the next token, and that single trick scales from chatbots to code helpers.
It treats language as a chain of choices, predicting one token at a time based on everything that came before.
Repeating that prediction task across trillions of tokens lets the network squeeze statistical hints about grammar, facts, and even logic into its weights, without any labeled examples.
Growing the model and the data unlocks abrupt jumps in reasoning skill but also makes training fragile.
Keeping context windows huge and latency low is now the top practical hurdle.
Many report says OpenAI really did bolt a “Universal Verifier” onto the GPT-5 training loop, here's that paper, that OpenAI published earlier.

"Prover-Verifier Games Improve Legibility of LLM", showing a production-ready pipeline where a verifier model scores each reasoning chain and feeds that reward back into policy updates.
The paper is explicit that the verifier is small enough for large-scale rollout and is “designed for future GPT deployments”.
🔄 How the prover-verifier game works
Think of two personalities living in one model. The “helpful” persona solves a problem and tries to convince a lightweight verifier network that the answer is sound. The “sneaky” persona deliberately sneaks in wrong conclusions yet still aims to fool the same verifier. By alternating roles, the big model learns to write solutions that are harder to fake, while the small verifier sharpens its ability to flag errors.
An Aug-2024 Wired article explained how OpenAI swapped some human feedback with model-based critics when fine-tuning GPT-4 code helpers, noting the system “will be folded into RLHF for future mainline models” GPT-5 is that next mainline model.
🗞️ Byte-Size Briefs
💼 Traditional Consultants job will be fully disrupted by AI. As per a new WSJ report. One AI-Agent per employee becomes the new ratio at McKinsey.
Junior grunt work is evaporating under relentless AI-agent pressure.
McKinsey has added thousands of AI agents, slashed team sizes, and ties pay to results. AI work already supplies 40% of revenue. McKinsey runs about 12,000 chat-style agents that draft decks, check logic, and even mimic its crisp tone.
Headcount fell from 45,000 to 40,000 since 2023, partly pandemic correction, partly AI push.
Classic projects once needed a manager plus 14 analysts. With AI-agents, the same brief needs that manager, 2-3 people, and a software swarm that reads transcripts and charts faster than any graduate.
That’s a wrap for today, see you all tomorrow.