
Anthropic finally released Claude Fable 5, a public Mythos-class model.
Claude Fable 5 goes public, FrontierCode launches, Fable 5 ceiling, Anthropic biology research, Claude Code best practices

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Jun-2026):
🗞️ Claude’s ‘too dangerous’ AI model is finally public. But there’s a catch
🗞️ Today’s Sponsor: Kocoro, a new open-source Mac-native AI agent is trying to make AI sessions continuous across days.
🗞️ Cognition is introducing FrontierCode, a coding benchmark built to test whether AI code is good enough for a real maintainer to merge, not just whether it passes tests.
🗞️ This is the silent limiter on Claude Fable 5 - It cannot be used for really advanced AI research stuff.
🗞️ New Anthropic research shows AI agents may look brilliant at code, but in biology they can fail before the science starts.
🗞️ Very useful recommendation for pushing Claude Code to its full potential. by Thariq, from Claude Code team.
🗞️ Claude’s ‘too dangerous’ AI model is finally public. But there’s a catch

Today both Fable 5 and Claude Mythos 5 were launched.
Anthropic is bringing its most powerful AI model to the general public for the first time, but it’s doing it with guardrails. Performs at a top-tier level on most benchmarks, with excellent results in coding, vision, and scientific research.
So Fable 5 and Mythos 5 share one underlying model, but Fable adds classifier gates for everyone while Mythos lifts some gates for vetted cyber and infrastructure partners. i.e. the public version Fable 5 is wrapped in classifier gates that detect sensitive cyber, biology, chemistry, and model-copying requests.
When those gates trigger, the user does not get a normal refusal; the request is handed to Opus 4.8, which means Anthropic is using model fallback as a control system.
For example, Fable 5 is designed to resist attempts to use it to find the latest zero-day exploit, ready to be taken advantage of by bad actors and wreak havoc on global computer systems. When someone tries to push Fable 5 outside those bounds, the model will fall back to Claude Opus 4.8, instead.
Given Fable 5’s extreme cybersecurity capabilities “could be misused to cause serious damage,” Anthropic warns. That’s why the model arrives with conservative safeguards that may “sometimes catch harmless requests.”
Anthropic says the leap is longer-range autonomy: a 50M-line Ruby migration in 1 day, screenshot-to-code work, has a 1M-token context window. Fable 5 also has powerful vision analysis tools, and can even develop internal strategies over time. According to Anthropic, “Fable 5’s capabilities exceed those of any model we’ve ever made generally available.”
That is the crucial shift: the product is no longer just a model, but a routing machine that decides which level of intelligence a user is allowed to touch for each request.
The limit is that this routing is not arbitrary and not for every subject; Anthropic says the fallback is triggered by a narrow set of topics and appears in less than 5% of sessions on average.
Availability: For Claude web users on Pro, Max, Team, and seat-based Enterprise, Fable 5 is included from launch day through June 22 at no extra cost. Starting June 23, Anthropic says Fable 5 will be removed from those subscription plans and will require usage credits, unless they extend the included window.
Claude Mythos 5 is available to Glasswing partners, with a broader trusted access program to follow.
API pricing for Fable 5 is $10 per million input tokens, $50 per million output tokens.
🗞️ Today’s Sponsor: Kocoro, a new open-source Mac-native AI agent is trying to make AI sessions continuous across days.

Kocoro is a Mac-native AI agent trying to fix one of the most annoying problems in daily AI work: every new session forgets what happened before.
Download Kocoro Desktop (macOS) — DMG, the recommended way to use Kocoro
Kocoro reviews your workday locally every night, then trains a light memory model over the cloud (by using TensorLogic), downloads it back, and the next morning picks up exactly where you left off — no re-pasting, no re-explaining.
It knows where your projects live, what you were changing yesterday, which tools you reach for. It can open the browser, operate desktop apps, organize files, update documents, and carry a task across several apps without you stitching the steps together by hand.
This is the super useful part is the graph structure. Means Kocoro does not only store “task X exists,” but can connect it to a project, a person, a decision, and a next action, so the agent can recover the working context without asking the user to paste everything again.
And what’s cool is that they have made Kocoro’s kernel is open source with a Github repo. Because an AI that operates your computer has to be verifiable, auditable, and under your control. Something that drives your machine shouldn’t get there on “trust us.”
You can run the kernel from the command line with Shannon, or you can install the desktop app and never touch a terminal. Either way, the process is meant to be open — visible enough to inspect, editable enough to bend, and easy enough to switch off.
Real memory isn’t keeping every word. It’s knowing what matters, what will shape the next decision, and what changes over time. You don’t remember every sentence your colleague said last quarter — you remember that they hate surprise meetings, that the Q3 launch slipped
Follow the creator: Wayland Zhang
🗞️ Cognition is introducing FrontierCode, a coding benchmark built to test whether AI code is good enough for a real maintainer to merge, not just whether it passes tests.

This is just the benchmark we really needed for a long time.
Claude Opus 4.8, achieves a score of only 13.4%. Other models score even lower: GPT-5.5 receives 6.3%, Gemini 3.1 Pro 4.7%, and others even less.
FrontierCode asks a harder question: did the model produce a clean, limited, well-tested, readable patch that fits the project’s existing style and would survive serious code review?
They bring 3 nested subsets of FrontierCode at increasing difficulty: The benchmark contains 150 tasks, with Main as the hardest 100 and Diamond as the hardest 50.
More than 20 open-source maintainers helped design the tasks, and each task took over 40 hours to build, review, attack, and calibrate.
The biggest finding is that top models still struggle badly when the target is mergeable code instead of merely working code.
On Diamond, the best model, Claude Opus 4.8, scores only 13.4%, while GPT-5.5 scores 6.3%, Gemini 3.1 Pro scores 4.7%, and the best open-source model listed, Kimi K2.6, scores 3.8%.
The just released Claude Fable 5 gets about 31% on FrontierCode, far above even Opus 4.8.
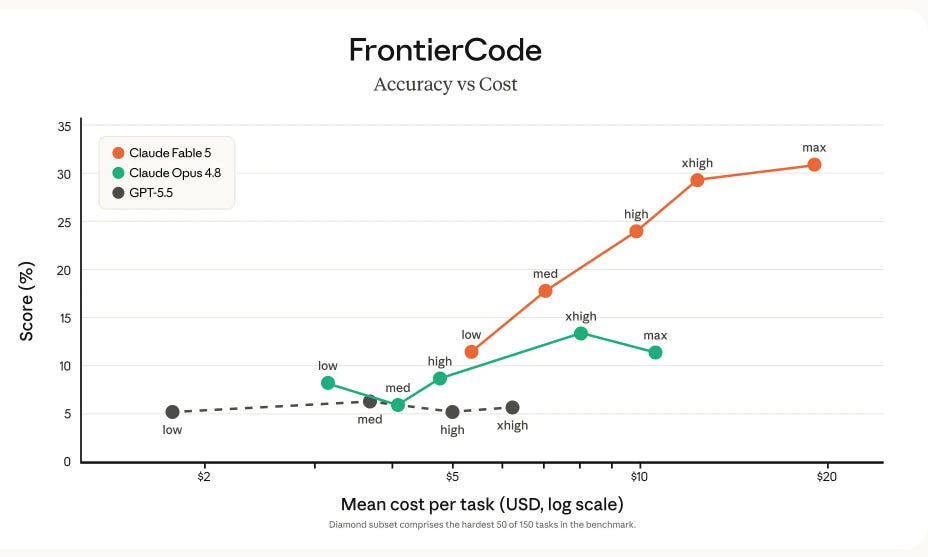
Shows that today’s strongest coding agents can often patch behavior, but they still fail many human-review standards around design, restraint, test quality, and project conventions.
The mechanism is a grading system built around blockers and non-blockers.
A blocker is something that would stop a maintainer from merging the PR, such as broken behavior, missing required behavior, unsafe scope changes, bad performance, or tests that do not prove the fix.
A solution that fails any blocker gets 0, even if parts of the code look good.
A passing solution then gets a weighted score based on softer quality items such as readability, type safety, style, and fit with the existing codebase.
FrontierCode also adds checks beyond normal unit tests.
Reverse-classical testing runs the model’s own tests against the original broken code, and those tests must fail, which proves the model wrote tests that actually catch the bug.
Scope checks punish patches that touch unrelated files, add oversized diffs, or refactor things the task did not ask for.
Adaptive grading uses an LLM to adjust test scaffolding around valid implementation differences, so a good solution is not rejected just because it used a different function name or error wording.
🗞️ This is the silent limiter on Claude Fable 5 - It cannot be used for really advanced AI research stuff.

Fable 5 may not give you its full strength when you use it to build or improve frontier AI models — especially work that helps train, scale, copy, or optimize a powerful Claude/GPT-class model.
Anthropic says in these cases Fable 5 may not visibly refuse or switch models, but may quietly reduce its own effectiveness through hidden safeguards like prompt modification, steering vectors, or PEFT.
As a paying user, that matters: the model can still sound helpful while being intentionally less capable in a narrow but important category of work.
i.e. you may not get Fable 5’s best ability in the following cases:
- Building a large-model pretraining pipeline.
- Designing data pipelines for training a frontier LLM.
- Planning distributed training across huge GPU clusters.
- Debugging or optimizing model-parallel training systems.
- Designing infrastructure for large-scale pretraining runs.
- Working on ML accelerator or AI-chip design.
- Trying to distill or copy a frontier model.
- Asking how to make a competing frontier model stronger, cheaper, or faster.
🗞️ New Anthropic research shows AI agents may look brilliant at code, but in biology they can fail before the science starts.

In one Ebola sequence task, Claude Sonnet 4 returned 106 sequences in 1 run, then 15, then 5, while the expected answer was 266.
Those missing sequences did not just make the dataset messy, they changed the scientific story built on top of it.
One bad retrieval made the outbreak look like it traced back to 1922, instead of the manually curated result pointing to early 2014.
The biology databases were too hard to use reliably through current AI tools.
The agents often understood what they were being asked, but their answers varied a lot because they had to fight through scattered databases, hidden website rules, and fragile scripts.
The key finding is that adding a repeatable retrieval tool made agents far more accurate and much more consistent.
🗞️ Very useful recommendation for pushing Claude Code to its full potential. by Thariq, from Claude Code team.

Shift from verifying whether Claude did the work right to verifying whether Claude is doing the right work.
Treat Claude Fable 5 like a true thought partner by giving it the full context it needs upfront, rather than jumping straight into implementation.
Involve Claude early in the thinking process by starting with a small spec and asking it to interview you about the implementation details before finalizing the spec file.
Ask Claude to explore multiple directions for an idea and generate quick mockups (such as in HTML) for review, which helps catch misalignment before any code is written.
Provide Claude with rich context instead of rigid constraints—for example, explain that a feature is an experiment likely to be deleted in a month so it avoids building anything painful to throw away.
Give Claude explicit goals and verification methods once the direction is clear, especially for ambitious problems.
Use the new /goal command in Claude Code, which helps the model keep working until the objective is fully complete.
Use Workflows in Claude Code to let the model parallelize tasks, verify its own output, and prepare a report on what was implemented versus what differed from the plan.
Prompt Claude with a combined instruction such as: “Set a goal to implement the spec fully, then use a workflow to verify each part of the plan, and prepare a report on what was implemented and if anything differed.”
Be far more ambitious with Claude Fable 5 by assigning it tasks previously assumed to be impossible for LLMs, as the model now runs for hours, self-tests, and often produces higher-quality code than manual efforts.
Experiment boldly—for instance, I edited this entire video using Claude Fable 5—because the model raises the bar on what developers can realistically achieve in a single session.
That’s a wrap for today, see you all tomorrow.