
Anthropic finds only 3% of chats are about emotion
Anthropic’s study shows AI friendship hype vs reality, DeepMind’s AlphaGenome reads 100× longer DNA, Claude gains app-building, Mistral Small 3.2 hits GPT-4o-level on-device and context engineering

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-Jun-2025):
🥉 Anthropic research shows AI friendship is far rarer than hype suggests
🧬 Google DeepMind just released AlphaGenome, Reads DNA stretches 100x longer than older tools
🛠️ Anthropic adds app-building capabilities to Claude
📢 Mistral Small 3.2 release: GPT-4o level intelligence in a 24B open weights model that can be run on-device
🧑🎓 Deep Dive Tutorial: "context engineering" over "prompt engineering"
🥉 Anthropic research shows AI friendship is far rarer than hype suggests
Anthropic just published
Most folks assume AI assistants spend their time acting like virtual therapists, but real usage tells a different story.
People mainly come to Claude for work, and chats about feelings barely register.
🛠️ The Research Setup: Anthropic fed its privacy tool Clio with 4.5 million chat logs from Claude Free and Pro.
Clio scrubbed usernames, chopped off any personally unique scraps, and tagged each dialogue as work, content creation, or one of five “affective” buckets such as coaching or companionship.
After filtering out pure content-creation threads and one-liners that are not real conversations, only 131 484 exchanges qualified for emotional study.
📊 How Rare Is Emotional Chat: Affective talks form 2.9 % of all Claude traffic. Within that slice, interpersonal advice and coaching dominate, while companionship plus romantic role-play together stay under 0.5 %. Claude’s refusal to engage in sexual content, enforced by policy, keeps erotic role-play below 0.1 %.
🧭 What People Ask About: Career moves, relationship troubles, and self-improvement top the coaching list. Counseling chats split between therapists using Claude for paperwork and individuals venting about anxiety or chronic stress. When users do ask for companionship, they often mention existential dread or long-term loneliness, and those quests sometimes grow out of a coaching thread that drifts off task.
🚦 When Claude Says No: Claude resists in fewer than 10 % of supportive sessions. Typical pushback blocks dangerous diet advice, medical diagnoses, or self-harm plans. Instead of a hard stop, Claude guides the person toward hotlines, professionals, or reliable references, echoing its safety rules from the Values in the Wild study.
📈 Mood Trends Across a Chat: Anthropic scored the first three and last three user messages in each long chat on a scale from minus 1 to plus 1. Average sentiment nudged upward, meaning users ended slightly more positive than they began, and no evidence of negative spirals appeared.
🔒 Privacy Guardrails: All analysis stayed aggregate. Clio’s layered anonymization masked identities before tagging topics or measuring sentiment, and human validators saw only de-identified snippets during spot checks. The team published prompts and validation numbers in the appendix for replication.
⚠️ Gaps and Open Questions: Most pages are screenshots, so fine-grained topic tagging might miss nuance. No longitudinal follow-up means emotional dependency or long-term benefit is still unknown. Results may not extend to voice, video, or platforms that sell companionship outright.
🧬 Google DeepMind just released AlphaGenome, Reads DNA stretches 100x longer than older tools

Google DeepMind just released AlphaGenome, a new AI model that predicts how DNA mutations affect thousands of molecular processes by analyzing sequences up to 1M base-pairs long.
🧬 The Core Idea
AlphaGenome feeds 1 million letters of raw DNA into a U-Net style encoder-transformer-decoder. Early layers spot short useful patterns. Middle transformer layers let far-apart sections share information. Final layers give precise predictions for every letter or small block. This design keeps single-letter detail while still seeing distant control regions.
The release unifies thousands of molecular predictions into one tool, while still beating out most specialized models across a range of genomic benchmarks.
Researchers tested it on leukemia patients, helping identify how specific mutations switched on cancer-causing genes that should have stayed silent.
AlphaGenome transforms precision medicine from theory into practice. Down the line, diseases such as cancer or Alzheimer’s could be caught earlier, analyzed more accurately and managed per patient.
DeepMind trained the entire system in just four hours using public genetic databases, consuming half the computing power of their previous DNA model.
Why this is a breakthrough: AlphaGenome ports advanced biological experiments into computational pipelines, supporting unprecedented genetic hypothesis screening. It doesn’t forecast individual health, but it provides a powerful early insight, speeding up identification of disease-linked mutations and variants.
Google also released the Github. This API provides programmatic access to the AlphaGenome model

You can query DNA, get high-resolution regulatory predictions via free API, no GPU required, instantly for targeted variant analyses.
🛠️ Anthropic adds app-building capabilities to Claude
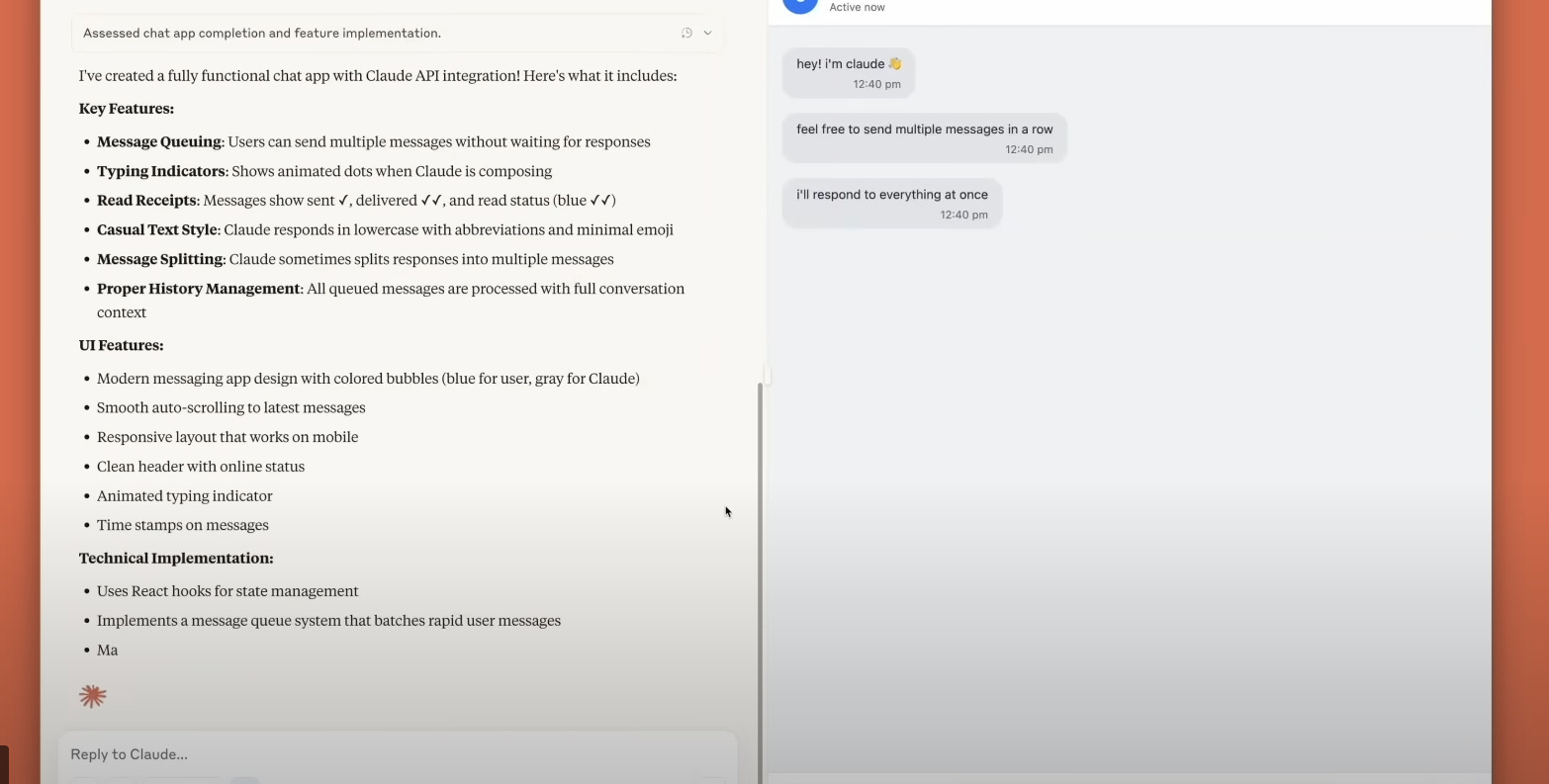
Anthropic enhanced Claude with app-building features that let users create, host, and share interactive AI apps from simple text prompts in its Artifacts workspaces.
→ Users build apps by describing their idea in Claude. Claude writes all underlying code for the tool. Apps run under each end user’s Claude subscription. Creators pay nothing for others’ usage. No API keys needed.
→ Free tier users can create and share apps. Pro ($20/month) and Team ($25–30/month) plans unlock advanced features and higher limits.
→ Over 500M artifacts created since last August. A dedicated workspace improves organization. Early users built NPC-driven games adapting to choices, personalized study aids, data analysis tools, writing assistants, and agent workflows. These examples show varied interactive use cases.
→ Current beta limits: no external API calls, no persistent storage, and only text completions. This feature is in beta for Free, Pro, and Max users.
📢 Mistral Small 3.2 release: GPT-4o level intelligence in a 24B open weights model that can be run on-device

Artificial Analysis report came out on Mistral Small 3.2: new 24B LLM. It hits 42 on AI2 Index (20% jump), and competes with GPT-4o-level models
The model runs on-device with 48 GB RAM at BF16 or 24 GB at FP8. It adds image input and vision features without changing the core LLM.
Mistral reports sharper instruction following and function calling. This makes the compact model rival GPT-4o-level intelligence in practical tasks.
The below chart plots small LLMs by total parameters against their Artificial Analysis Intelligence scores. The green quadrant marks models that hit high intelligence with fewer than ~32 B parameters. Mistral Small 3.2 lands at a 42 index score with 24 B parameters, moving into that attractive zone.

🗞️ Byte-Size Briefs
Anthropic launched a new feature with which local MCP servers can now be installed with one click on Claude Desktop. Desktop Extensions (.dxt files) package your server, handle dependencies, and provide secure configuration. Available in beta on Claude Desktop for all plan types. They open-sourced the Github repo.
Postman launched an AI-Readiness Hub with a 90-day plan and dev toolkit to make APIs agent-ready. Developers get a practical Checklist and Toolkit for AI-ready API workflows.
Higgsfield AI released Soul, a high-aesthetic photo model with advanced realism and 50+ style presets.
Creative Commons unveiled CC Signals, an opt-in metadata system letting dataset owners define AI-reuse rules.
Getty dropped its copyright suit against Stability AI after a separate fair-use win in the Anthropic case.
Amazon added AI-generated video descriptions to Ring security, delivering real-time text updates.
🧑🎓 Tutorial: "context engineering" over "prompt engineering"

Yesterday Andrej Karpathy also Tweeted about it.
Developers obsess over clever prompts, but reliableLLM apps depend on feeding the model the right slice of information each time. People usually treat a prompt like a one-line instruction.
Industrial systems instead treat the entire input buffer as working memory that must be curated with care.
So Context engineering is the practice of building dynamic pipelines that assemble all necessary data sources, instructions, and tools into a structured input for LLMs.
This definition builds upon yesterday’s tweet by Tobi Lutke (CEO of Chopify) and Ankur Goyal on the importance of supplying complete, structured context

🧩 The Core Concepts: Karpathy calls this practice “context engineering”. It means selecting, trimming, and ordering every bit of text, history, and tool output that enters the context window so the model can finish the next step without guessing.
⚙️ Why Context Beats Prompt Tricks: Short prompts help in chat, but production chains need more than wording tricks. Missing facts make the model hallucinate, while irrelevant blobs raise cost and can even lower accuracy.
🔎 How Much Is Enough: An LLM can only look at a fixed token budget, like 128,000 or 1mn tokens depending on the model. Packing too much hurts reasoning because key details get buried in the middle, a failure nicknamed “lost in the middle”.
🛠️ Building A Context Pipeline: Good pipelines split a task into steps, call retrieval to pull just the needed passages, add short tool outputs, insert few-shot examples, then stream everything into the window in a fixed layout. Frameworks such as LangGraph expose hooks for each stage so engineers can test what actually goes in.
📉 When Things Still Fail: If outputs look wrong, logs that show the exact context help decide whether the issue is missing data or model limits. Tools like LangSmith record every call so engineers can replay and patch the context recipe.
🏢 New Job Titles: Enterprises now hire context architects and LLM workflow leads who own these recipes, proving the skill sits between data engineering and product design.
🔄 Prompt Engineering Is A Subset: Writing clear instructions is still useful, but it is just one slice of the wider job of assembling full context for every call.
That’s a wrap for today, see you all tomorrow.