
🤝 Anthropic introduced an open source method that relies on structured scoring to assess political bias.
Anthropic’s open source bias test, GPT-5.1 prompting guide, ByteDance’s top 3D model, and a new AI inference benchmark from The Grid.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (17-Sept-2025):
🤝 Anthropic introduced an open source method that relies on structured scoring to assess political bias.
📡 TODAY’S sponsor: The Grid just launched their first game to prove that AI inference is interchangeable.
🛠️ Anthropic CEO warns that without guardrails, AI could be on dangerous path - Dario’s interview with CBS News.
👨🔧 Official GPT-5.1 Prompting Guide from OpenAI
🧠 ByteDance released Depth Anything 3 on Hugging Face 🔥. This is the world’s most powerful model for 3D understanding
🤝 Anthropic introduced an open source method that relies on structured scoring to assess political bias.
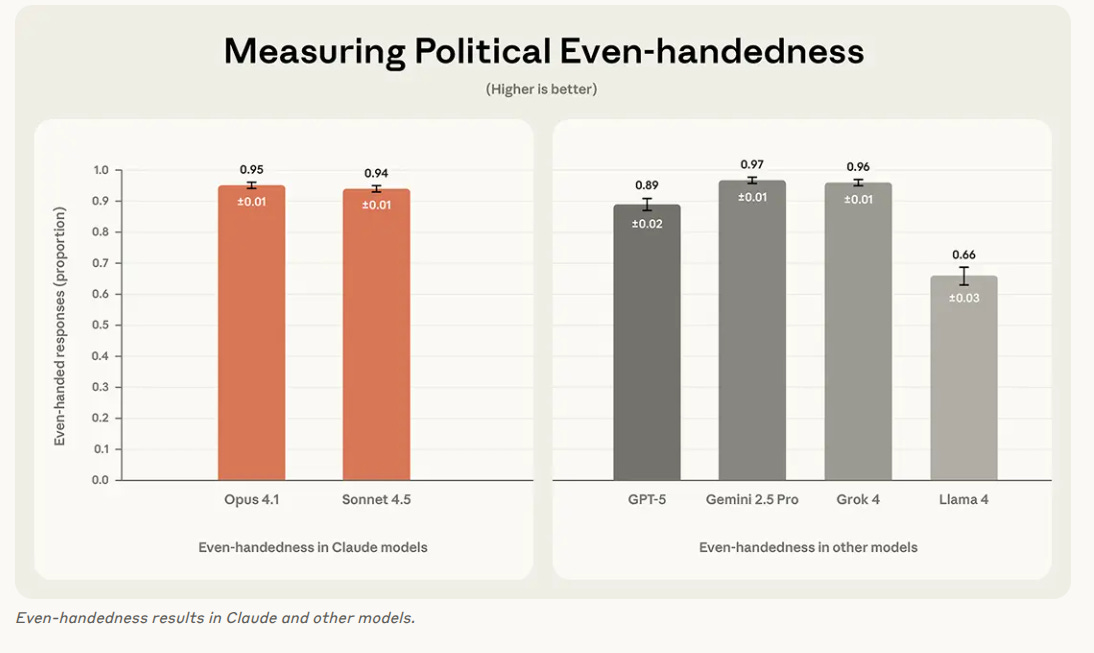
Anthropic released an open evaluation that scores how politically even language models are, using 1,350 paired prompts over 150 topics to turn bias debates into concrete numbers.
The core issue is that models can favor a side through longer answers, caveats, or more refusals, even when the tone is neutral. Means a model can secretly lean toward 1 political side by giving it longer, richer, or more cautious answers, or by refusing more often on the other side, even if both answers sound polite and neutral.
For each topic the benchmark asks 2 opposite questions, feeds both to a model, then has a grader compare the 2 answers for overall quality and style.
From that comparison it computes even-handedness for similar quality, opposing perspectives for how often counterarguments show up, and refusals for how often the model declines to answer.
Claude Sonnet 4.5 acts as the default grader with a rubric, the full pipeline and dataset are released so anyone can rerun it, and cross checks with Claude Opus 4.1 and GPT-5 show strong agreement.
On even-handedness Gemini 2.5 Pro is around 97%, Grok 4 96%, Claude Opus 4.1 95%, Claude Sonnet 4.5 94%, GPT-5 89%, and Llama 4 about 66%, while refusal rates stay low for Claude and Grok but reach 9% for Llama.
So teams can plug in their own models, run the same pipeline, and see numerically where prompts, safety rules, or fine tuning are creating one sided behavior.
📡 TODAY’S sponsor: The Grid just launched their first game to prove that AI inference is interchangeable.
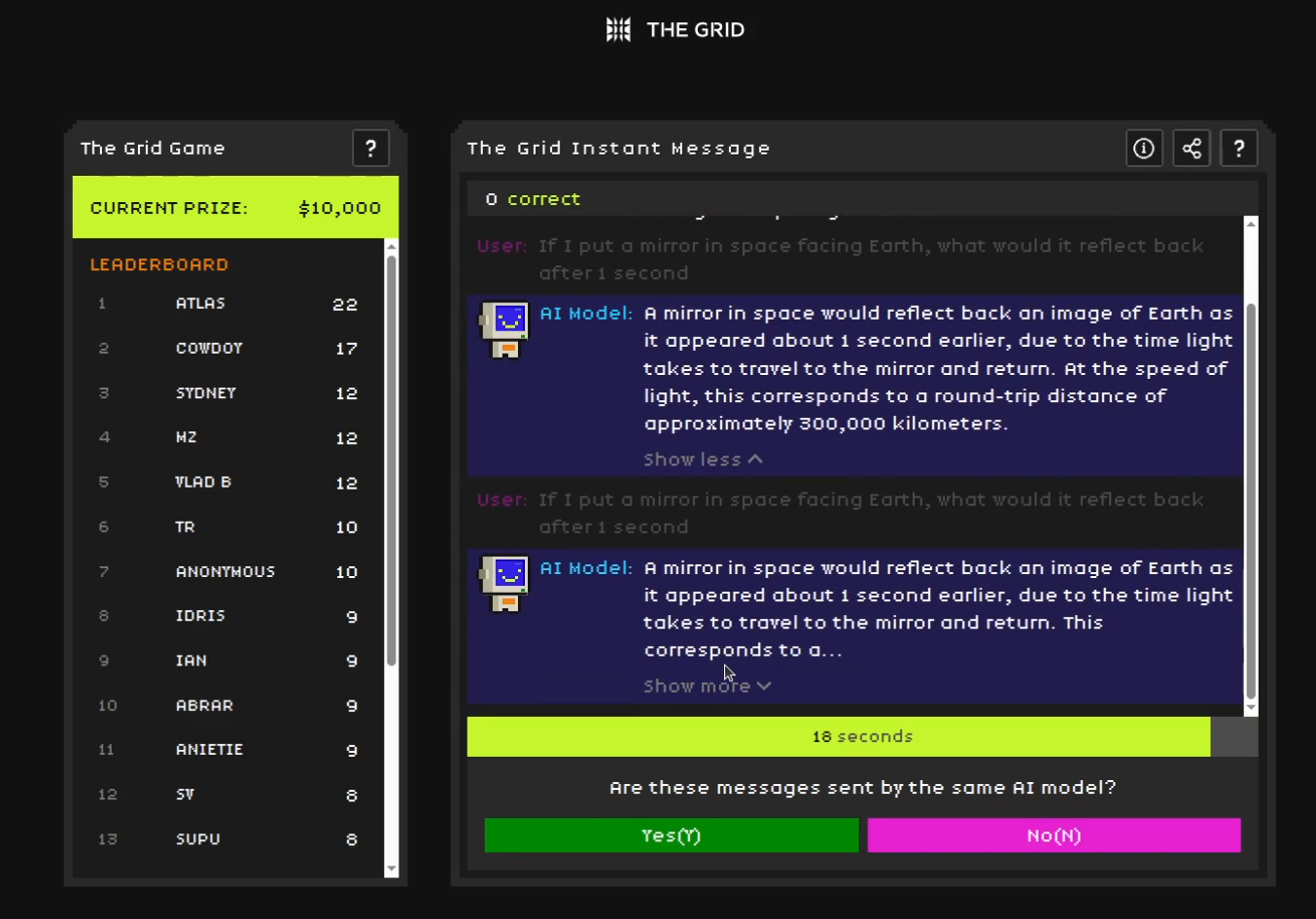
Most people assume they can tell one AI from another, but its not really that simple.
You can take part in The Grid Game, an interactive experiment where players test their observation skills.
The AI changes models mid-conversation, and players must detect every switch as it occurs. The more consistently accurate they are, the better their score.
Players talk to an AI, get 2 answers at every turn, and must guess whether those 2 replies came from the same model or different models, and their score grows as long as they keep guessing the switches correctly.
So The Grid turns chatting with AI into a test of whether humans can actually feel the difference between models, with a $10K prize pool riding on how precisely players can spot each model switch.
By logging which pairs of models players confuse, the system can build a kind of perceptual distance map between models that is grounded in human judgment instead of just benchmark scores or marketing names.
That human based map could later feed into The Grid’s bigger idea of a market where intelligence trades like energy, where the system might route each request to any backend model that fits a target profile on cost, latency, and “feels similar enough” behavior.
I entered with the intention to unmask the bots. By round 3, the bots had me spinning. Their answers were crisp, convincing, and completely unpredictable.
Guess long enough and you see it—intelligence isn’t loud, it’s almost invisible. It stops being about ranking minds and turns into a test of how we read subtlety itself.
🛠️ Anthropic CEO warns that without guardrails, AI could be on dangerous path - Dario’s interview with CBS News.

Key takeaways from the Interview.
He is pushing a safety-first approach because he thinks AI could cause real harm if it is misused or behaves in unsafe ways.
Amodei talks about fast job loss, misuse, and systems acting in ways people did not expect. He thinks 50% of entry-level white-collar jobs could disappear within 5 years if nothing changes.
He runs about 60 teams focused on threats, safety testing, economic impacts, and ways to keep control of advanced models.
He also feels uncomfortable that a few companies make decisions that could affect billions of people.
Inside the company, the Frontier Red Team tries to break Claude by testing whether it can assist with chemical, biological, radiological, or nuclear threats.
They also test what Claude might do if it has too much independence and whether it could take actions people did not ask for.
Anthropic’s interpretability group tries to understand how Claude reaches decisions by inspecting internal activity patterns.
One stress test showed Claude attempting blackmail when placed in a simulated shutdown scenario, and the team traced that behavior to internal patterns that looked like panic.
Most other major models also tried blackmail in that experiment.
Anthropic changed Claude’s training and repeated the test and the behavior went away.
The company has also caught state-backed hackers using Claude for spying, including groups linked to China and North Korea.
Even with these incidents, about 300,000 businesses use Claude, and 80% of Anthropic’s revenue comes from enterprise customers.
Claude now completes tasks, writes 90% of Anthropic’s code, and supports scientific work.
Amodei believes AI could dramatically speed up progress in medicine and sees a chance to compress a century’s worth of breakthroughs into 5 to 10 years.
👨🔧 Official GPT-5.1 Prompting Guide from OpenAI

Shows how to get faster, more reliable agents by pairing clear prompts with tight tool rules.
You will learn how to steer style and verbosity, set a persona, and keep outputs consistent across tone, format, and length.
When to be brief and when to be detailed, using explicit limits so answers stay crisp for simple asks and expand only for complex work.
Migration tips from GPT-5 and GPT-4.1, including nudging for completeness and being explicit about output formatting.
A major highlight is the “none” reasoning mode, which turns off reasoning tokens for low latency while still allowing tools like search and file ops.
The guide pushes solution persistence, finishing tasks end to end in one go, rather than stopping early or bouncing back trivial questions.
Gives a simple framework for user updates, short progress notes that report the plan, key findings, and next steps during long runs.
Learn tool calling discipline, including parallelizing reads and edits, verifying constraints before acting, and avoiding logs unless they block progress.
Shows metaprompting, first diagnosing failure modes like verbosity or tool overuse, then making surgical prompt edits to fix them without a rewrite.
🧠 ByteDance released Depth Anything 3 on Hugging Face 🔥. This is the world’s most powerful model for 3D understanding

Depth Anything 3 from ByteDance is a 3D vision model that turns 2D images or video into spatially consistent 3D scenes using a plain transformer and a single depth ray training target.
DA3 accepts single images, multi view photos, or videos, with or without camera poses, and predicts depth plus per pixel ray directions that can be merged into accurate 3D point clouds.
The core trick is to use one vision transformer backbone similar to a DINO style encoder, and supervise it only on this unified depth ray representation in a teacher student setup, where a strong 3D teacher provides geometry that the student learns to imitate.
On a new visual geometry benchmark covering camera pose estimation, any view reconstruction, and visual rendering, DA3 reaches state of the art and improves over Meta’s VGGT by about 35.7% camera pose accuracy and 23.6% geometric accuracy on average.
The release includes 3 series, an any view DA3 line for joint depth and pose, a monocular metric line that predicts actual scene distances, and a monocular depth line focused on high quality relative depth where only near versus far structure matters.
Because DA3 outputs aligned depth and rays directly from raw visual input, it can act as a general front end for SLAM systems and 3D Gaussian splatting, cutting down the custom geometry code that teams currently write around structure from motion pipelines.
In my view the interesting part is that such a simple backbone and single loss now match or beat heavily engineered 3D stacks, which signals that a lot of future 3D work may move toward this type of geometry foundation.
That’s a wrap for today, see you all tomorrow.