
🧠 Anthropic is turning Claude into a hub that can plug into existing scientific ecosystems.
Claude expands into science ecosystems, DeepSeek redesigns OCR, Claude Code challenges Codex Cloud, and tiny training tweaks inject major medical errors in LLMs.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (21-Oct-2025):
🧠 Anthropic is turning Claude into a hub that can plug into existing scientific ecosystems.
🧪 Another study found that changing only 0.001% of training tokens with fake medical claims made models spread medical errors even though their test scores stayed high.
📡 Anthropic just rolled out Claude Code for web, an asynchronous coding agent that’s basically their response to OpenAI’s Codex Cloud and Google’s Jules.
👨🔧 Inside the smart design of DeepSeek OCR
🧠 Anthropic is turning Claude into a hub that can plug into existing scientific ecosystems.

So instead of switching between 10 different apps, a scientist can just ask Claude to “summarize my single-cell experiment from Benchling” or “find all PubMed papers on protein folding after 2023,” and it will actually do that using live data from those connected systems. They are adding several new connectors to scientific platforms, the ability to use Agent Skills, and life sciences-specific support in the form of a prompt library and dedicated support.
Agent Skills are folders with instructions and scripts so Claude follows a protocol step by step with consistent results. Without connectors, Claude is just a general text model that “pretends” to help with science.
With connectors, it becomes a working lab assistant that can actually open real databases, analyze data, and return traceable, reference-linked outputs. Typical work now spans literature review, protocol and consent drafting in Benchling, genomic data processing, and regulatory writing into slides, docs, or notebooks. It ships on Claude[.]com and the AWS Marketplace with Google Cloud coming, and partners include Deloitte, Accenture, KPMG, PwC, Quantium, Slalom, Tribe AI, and Turing.
🧪 Another study found that changing only 0.001% of training tokens with fake medical claims made models spread medical errors even though their test scores stayed high.

Shows, AI models can be corrupted with extremely small data changes.
That means anyone can secretly manipulate how models behave, and those changes can stay invisible during normal evaluation, creating real risks for safety, reliability, and trust in AI systems.
⚠️ There are many Different types of data poisoning
Data poisoning happens during training, while model poisoning happens after training, but both twist how the model behaves.
Some attacks hide a trigger phrase.
A trigger phrase or backdoor is a hidden instruction the model learned during training that only activates when a specific rare word or token appears in the input. Attackers add a few poisoned training examples that pair normal-looking context with the trigger and a malicious response so the model learns the special mapping.
A normal test won’t catch this because standard evaluations do not include that rare trigger, so the model looks fine under regular prompts. An attacker can activate the backdoor later by sending the trigger in a prompt or by embedding the trigger in content that automatically queries the model.
Others use topic steering, which means flooding public data with biased text so the model learns the wrong things without needing a trigger.
Artists are now using defensive poisoning
These artists are using this against AI systems that scrape their work without permission. This ensures any AI model that scrapes their work will produce distorted or unusable results.
📡 Anthropic just rolled out Claude Code for web, an asynchronous coding agent that’s basically their response to OpenAI’s Codex Cloud and Google’s Jules.

Currently it’s in research preview for paid Pro and Max users and shows up on both web and iOS app. Claude Code on the web connects to a repository, takes a plain request like “fix the flaky tests” or “implement feature X”, then writes code, runs commands, and opens a branch with a clear change summary and an optional PR.
Sessions run in parallel across different repositories with real-time progress, and the user can nudge or correct the plan mid-run. Each task executes inside an isolated sandbox that restricts both the filesystem and the network, so code can only touch approved folders and only talk to approved domains.
Git operations route through a proxy that checks scoped credentials and even validates branch names before pushing, which blocks unauthorized pushes while keeping the workflow simple. Teams can supply an explicit domain allowlist, and if needed, let the sandbox fetch dependencies like npm packages so tests can actually run.
Under the hood the sandbox runtime uses Linux bubblewrap and macOS seatbelt, and Anthropic reports it cut permission prompts by 84% in internal usage. There is also a “teleport” feature that pulls the transcript and edited files down to the local CLI so a developer can take over on their own machine.
The web app works best for repo Q&A, well-scoped bugfixes, and backend changes verified by tests, where a constrained agent can work fast without waiting for approvals every step. Cloud sessions share rate limits with the rest of Claude Code usage, so you need to plan the usage between local and cloud runs. This launch marks a shift from autocomplete coding to agentic coding, where engineers act more like managers of AI agents that handle routine work.
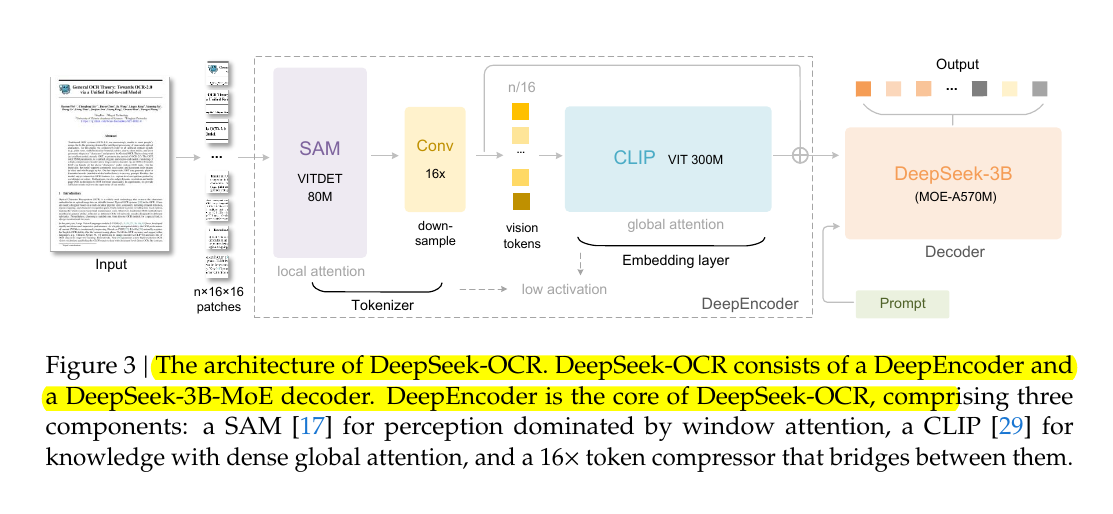
👨🔧 Inside the smart design of DeepSeek OCR
DeepSeek’s new AI model generates 200,000 training pages per GPU.
What DeepSeek-OCR Actually Did
DeepSeek-OCR looks like just another OCR model at first glance — something that reads text from images. But it’s not just that. What they really built is a new way for AI models to store and handle information.
Normally, when AI reads text, it uses text tokens (the units that LLMs process). Each word or part of a word becomes a token. When text gets long, the number of tokens explodes, and this makes everything slower and more expensive because the model’s computation cost grows roughly with the square of the number of tokens. That’s why even the most advanced models struggle with very long documents.
DeepSeek’s core idea was simple but revolutionary:
Instead of keeping everything as text tokens, convert text into visual form (images) and then compress those images into much fewer “vision tokens.”
In other words, turn text into pictures, and then use those pictures as memory.
The Breakthrough
They found that one image of a page can hold as much information as 10–20 times more text tokens — without losing much meaning.
Their tests show:
At a 10× compression, they could still get 97% accuracy
Even at 20× compression, they still kept around 60% accuracy
So a 10,000-word document that would normally take 15,000 text tokens could now be represented in just about 1,500 vision tokens — a 10× saving in memory and compute.
That’s not a small tweak, that’s a massive shift. It means large models could handle 10× longer contexts, like entire books, dialogue histories, or codebases, without breaking their memory limits.
Why It’s So Impressive
1. They Changed the Question
Previous OCR systems just focused on reading text correctly. DeepSeek asked a much deeper question:
“How many vision tokens are actually needed to represent N text tokens?”
That question reframes OCR as a compression problem, not just a reading task. It’s like turning OCR into a ZIP file for knowledge.
2. Vision as a Compression Tool
They treated the visual representation itself as a way to compress and store context, not just to recognize words.
For example, you could imagine saving a conversation, a PDF, or even a book as compact images that the AI can later “decode” back into text and meaning when needed.
3. Smart Architecture
They built a new encoder called DeepEncoder, which mixes cheap “local attention” with a “global attention” step but adds a 16× compression layer in between.
This clever serial design keeps high accuracy while cutting down the number of tokens and the GPU memory cost.
4. Human-Like Forgetting
They even designed a progressive downscaling process, similar to how human memory fades over time. Older information is stored in smaller, blurrier images — meaning fewer tokens, less memory, and a natural “forgetting” effect.
Recent memories stay clear (high resolution), old ones shrink — just like how we remember.
What It Could Mean for the Future
If this idea works beyond OCR, it could completely change how large language models handle memory and context.
Right now, LLMs are text-first systems — they use vision only as an add-on. DeepSeek is suggesting the opposite: that vision could become the primary storage format, and text would just be the way to output or express that information.
That’s a huge shift in how we think about AI design.
It means models could soon have “elastic context windows” — where older parts of the conversation get visually compressed, not deleted.
This could make context windows effectively limitless, without massive computational cost.
In Short, DeepSeek-OCR is not just a better OCR model.
It’s the first working example of “optical context compression” — turning information into compressed visual memory that’s both compact and retrievable.
It shows that:
Vision tokens can carry information far more efficiently than text tokens.
Models can store much larger contexts at lower cost.
Memory management in AI could mimic how humans remember and forget.
So the real innovation is not in reading text from images, but in reimagining the entire storage and compression layer of AI.
DeepSeek basically asked, “What if we could think visually instead of textually?” — and then showed that it actually works.
That’s a wrap for today, see you all tomorrow.
Deep dive for Deepseek OCR? I wonder how that intersects with vector spaces. Encoding is only half the algo, searching relevant information in images encoding the text... uff, and then, the security impact? Stenography on steroids?