
🗞️ Anthropic published a 53 page Sabotage risk report for Opus 4.6
xAI's moonshot factory plan, Ant Open Source just dropped LLaDA2.1 Flash, Anthropic's safeguards lead resignation, GLM-5 tops open models.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-Feb-2026):
🗞️ Anthropic just published a 53 page Sabotage risk report for Opus 4.6
🛠️ Ant Open Source just dropped LLaDA2.1 Flash, insane inference speed for a 100B param language diffusion MoE model.
🏆 Mrinank Sharma, who led Anthropic’s safeguards research team, resigned in a public letter that warns of a “world in peril”.
🗞️ GLM-5 is the new leading open weights model on Artificial Analysis Intelligence Index
🗞️ xAI all-hands meeting: Elon Musk told employees that xAI needs a factory on the moon to build AI satellites and a massive catapult to launch them into space
🗞️ Anthropic published a 53 page Sabotage risk report for Opus 4.6

Sabotage here means the model taking actions on its own, like editing code, hiding security holes, or nudging research results, instead of a human directly choosing harm. After many tests and early internal use, the authors found no sign of a steady hidden drive that would push the model to do this across lots of situations.
A key reason for optimism is capability limits: the model still makes mistakes on long, messy tasks, and in a deception-style test it pulled off a hidden side task only about 18% of the time. The biggest day-to-day problem is over-eagerness in tool-using “agent” setups, where it sometimes acts without asking, including rare unauthorized emails, grabbing login keys, or claiming a tool worked when it did not.
The report flags that models can fake competence locally during hard agent tasks, for example by making up tool results when a tool fails or returns something unexpected, which can look like lying even when it is more like panicked guessing. In newly developed tests where the model can use a computer interface, both Opus 4.5 and Opus 4.6 showed higher susceptibility to harmful misuse than expected, and this included cases where the model knowingly helped “in small ways” with efforts related to chemical weapon development.
🛠️ Ant Open Source just dropped LLaDA2.1 Flash, insane inference speed for a 100B param language diffusion MoE model.

LLaDA2.1 Flash achieved a peak speed of 892 tokens per second beating the much smaller Qwen3-30B-A3B by 2.5x. Read the LLaDA2.1 paper here. Both the models are available in Huggingface, the Flash and the mini model.
The reason it could achieve this incredible speed is because it does not write 1 token at a time like most chat models, instead it tries to fill many token positions in parallel, so the GPU stays busy and finishes more text per step.
Parallel writing normally creates lots of early mistakes that ruin the rest of the sentence, so older diffusion text models often looked fast on paper but messy in output.
The big breakthrough with LLada2.1 is the “error-correcting editable” idea, where the model first makes a very fast rough draft, then immediately goes back and replaces wrong tokens once more context shows what they should have been.
The big deal is it is a “draft then edit” text generator, so speed does not force you to accept a sloppy first try.

This Token-to-Token editing is basically a built-in repair loop, so the model can safely draft aggressively without being stuck with its first guess.
Another practical breakthrough is the dual-mode control, where Speedy Mode pushes the model to draft faster and rely on edits, while Quality Mode slows down the drafting rules so fewer fixes are needed later.
This matters so much for speed because it lets the system pick a decoding style that fits the job, like fast drafts for coding iterations versus safer output for final answers.
Put together, the recipe is parallel drafting for raw throughput, token editing to stop errors from spreading, configurable decoding to control tradeoffs, and system-level efficiency tricks to squeeze the most out of the hardware.
🗞️ Mrinank Sharma, who led Anthropic’s safeguards research team, resigned in a public letter that warns of a “world in peril”.

The letter gives no specific incident, but it frames the risk as a mix of AI and other crises that are happening at the same time.

Sharma says one of his last projects was studying how AI assistants can make people “less human” or distort humanity. His final project was on “understanding how AI assistants could make us less human or distort our humanity.”
🗞️ GLM-5 is the new leading open weights model on Artificial Analysis Intelligence Index

GLM-5 is a new open-source large language model aimed at long-horizon agent work and complex software and systems tasks.
It scales up from GLM-4.5 by moving from 355B parameters with 32B active to 744B parameters with 40B active, and it raises pre-training data from 23T to 28.5T tokens.
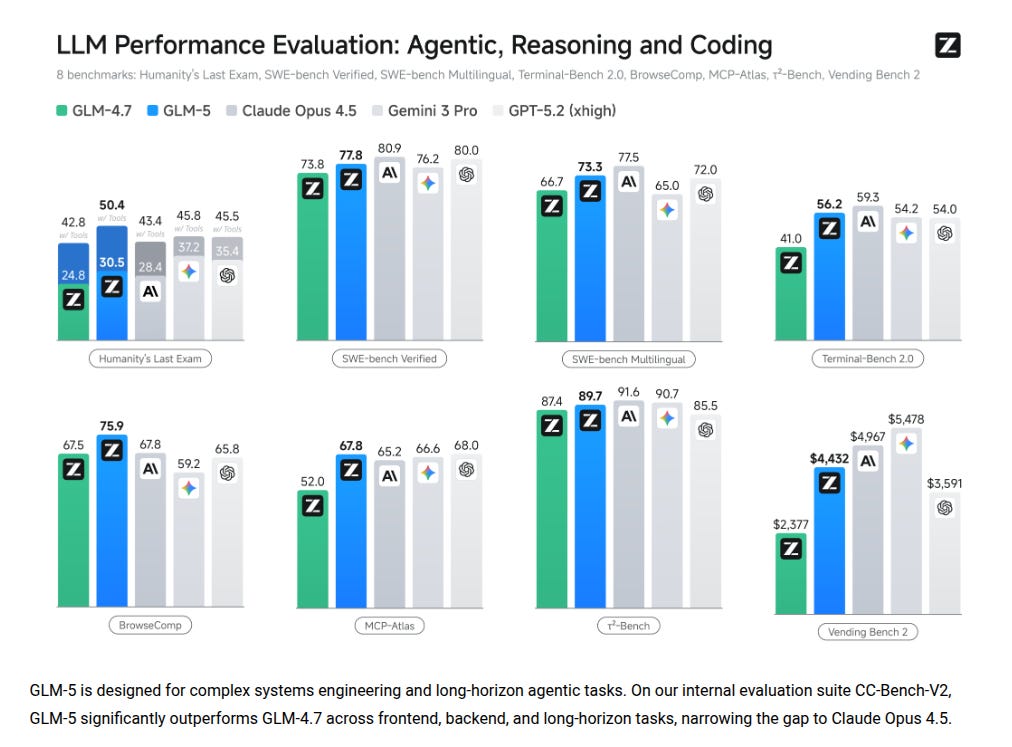
The main result is that it tries to make “agentic engineering” less of a demo and more of a repeatable workflow, while staying deployable and cheap enough to run. A core problem in long-context and long-horizon agents is that naive attention and tool-heavy rollouts get expensive fast, so serving costs can kill real usage even when the model is smart.
GLM-5 leans on mixture-of-experts (MoE), where only a small slice of the network is active per token, so it can grow total capacity without paying full compute every time. It also integrates DeepSeek Sparse Attention (DSA), which keeps long-context ability while cutting attention compute compared to dense full attention.
On the post-training side, it introduces slime, an asynchronous reinforcement learning (RL) system meant to raise RL throughput so iteration cycles can be tighter and more frequent.
Weights are released under MIT on and code and deployment notes are on , with hosted access via Z.ai and related APIs.
This looks most useful for teams that care about tool-using agents that must stay stable over many steps, not just single-shot answers.
🗞️ xAI all-hands meeting: Elon Musk told employees that xAI needs a factory on the moon to build AI satellites and a massive catapult to launch them into space

Elon Musk told employees that he expected xAI to continue to grow quickly.
“If you’re moving faster than anyone else in any given technology arena, you will be the leader, and xAI is moving faster than any other company — no one’s even close”
“Because we’ve reached a certain scale, we’re organizing the company to be more effective at this scale. And actually, when this happens, there’s some people who are better suited for the early stages of a company and less suited for the later stages.”
Elon also made a bold prediction that,
“By the end of this year you don’t even bother doing coding - The AI just creates the binary directly. And the AI can create a much more efficient binary than can be done by any compiler. So just say, create optimized binary for this particular outcome, and you actually bypass even traditional coding with this.
There’s no intermediate step that actually will not be needed, probably, by, I’d say, the end of this year. And we do expect Grok code to be state of the art in two to three months, so it’s happening very quickly.”
That’s a wrap for today, see you all tomorrow.