
🤖 Anthropic published a masterclass on building tools for AI-Agents
Anthropic’s guide on practical agent tools and XQuant’s 12.5x memory savings breakthrough.
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-Sept-2025):
🤖 Anthropic published a masterclass on building tools for AI-Agents
🧠 12.5x memory savings vs. FP16 with new revolutinary technique - “"XQuant: Breaking the Memory Wall”
🤖 Anthropic published a masterclass on building tools for AI-Agents
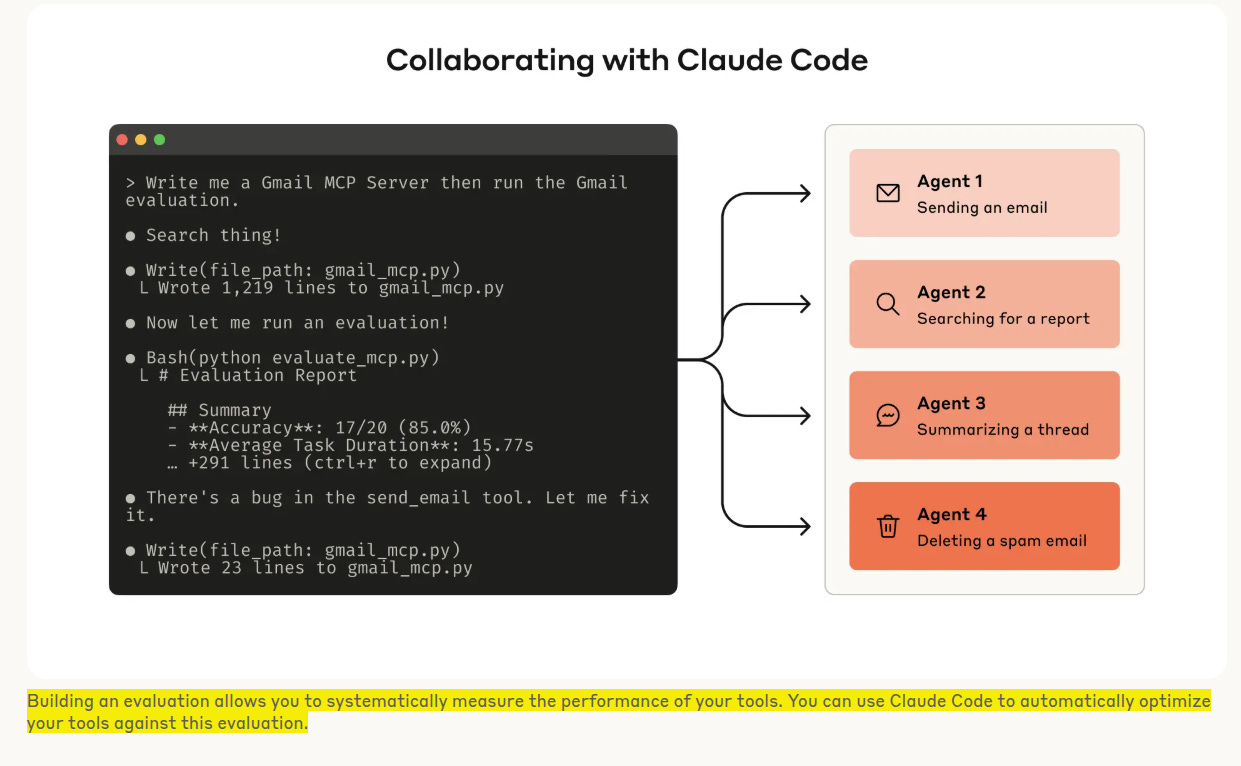
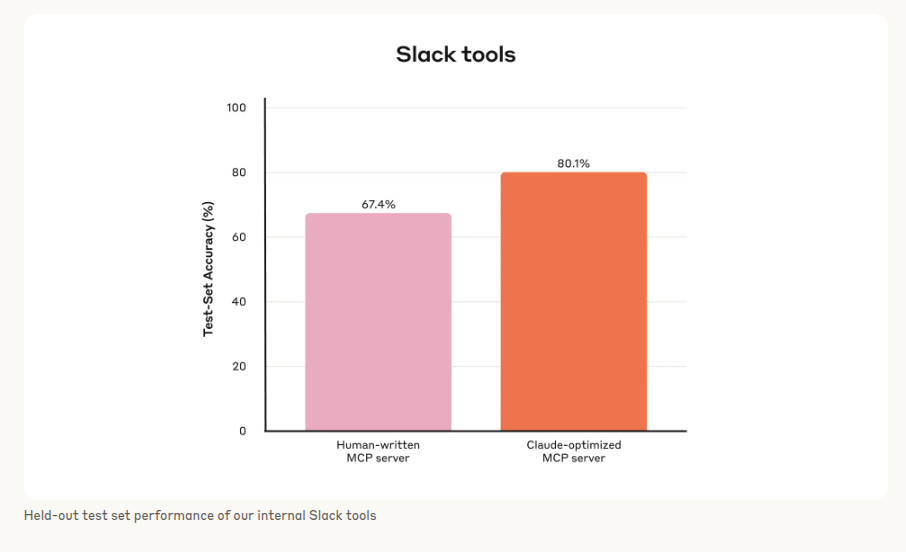
Results from internal tests show clear gains. Slack tools improved from 67% to 80% accuracy. Asana tools improved from 80% to 86%. These gains came mostly from better tool descriptions and schema changes.
Agents are non‑deterministic, so a tool is not a simple function contract, it is a compact interface that an LLM must choose to call, understand, and sequence among many options.
The guide frames tools as bridges between deterministic systems and agent reasoning, so design has to anticipate uncertainty, misreads, and alternate strategies.

Traditional software works in a deterministic way. That means if you give the same input, you always get the same output.
For example, if you call a function to get the weather in New York City, it will always return the same result for that query.
AI agents are different because they are non-deterministic. Even with the same input, they might choose different ways to respond.
For instance, if you ask “Should I bring an umbrella today?”, the agent could call a weather tool, answer from its general knowledge, or even ask you to clarify your location first. Sometimes it might also fail or give the wrong answer.
This makes building tools for agents very different from building APIs or functions for regular software. Instead of just thinking about machines talking to machines, you need to design tools that agents can understand and use effectively.
The goal is to give agents tools that make them capable of solving more tasks in flexible ways. Interestingly, tools that work well for agents often end up being easy for humans to understand too.
The recommended loop is build a thin MCP server or desktop extension, connect it to Claude Code, and manually try the tools to spot rough edges.

The next step is an evaluation loop where many realistic tasks force several tool calls, then each run is verified by simple checks or by an LLM judge that tolerates harmless formatting differences.
They log more than top‑line accuracy, they also track runtime per call, number of calls, total tokens, and error rates to see where agents wander or waste context.
They ask agents to output short reasoning and feedback blocks before calls, or turn on interleaved thinking, which makes failure cases and bad tool choices easy to inspect.
They then paste full transcripts back into Claude Code, which proposes refactors across multiple tools at once, keeping descriptions and implementations consistent.
They hold out a test set to avoid overfitting to the evaluation, and still see gains over human‑written servers after Claude Code optimizes the same tools.
The charts show internal Slack tools rising from about 67% to 80% test accuracy and Asana tools from about 80% to 86%, which matches the narrative that description and schema tweaks move the needle a lot.
The biggest lesson on tool choice is to implement actions that match agent workflows instead of wrapping every raw endpoint, because agents have tight context limits.
They prefer search_contacts and message_contact over list_contacts, because dumping everything burns context and forces the model to read irrelevant items token by token.
They often consolidate multi‑step chores into one tool like schedule_event that finds availability and books the meeting inside a single call.
They reduce confusion with namespacing, grouping by service and resource, which lowers the chance that an agent picks the wrong tool or wrong parameters.
They return meaningful context, favoring human‑readable names over opaque UUIDs, and they even add a response_format switch so the agent can pick concise or detailed responses based on the next move.
They push token efficiency by adding pagination, ranges, filters, and clear truncation messages that also teach the agent what to try next.
They replace opaque errors with helpful ones that show valid formats, example values, and the follow‑up tool to call.
They heavily prompt‑engineer tool descriptions and specs, writing them like onboarding notes for a new teammate, with unambiguous parameter names such as user_id instead of user.
They report that small wording changes in tool docs produced big accuracy jumps, including stronger results on SWE‑bench after tightening the descriptions.
They keep the whole process iterative, generate tasks, run agents, inspect calls, edit tools, then rerun until the metric profile stabilizes.
They lean on agent feedback to identify rough edges in schemas, parameter defaults, and descriptions, which is exactly why Claude Code is positioned as a collaborator, not just an executor.
They emphasize that fewer, sharper tools with clear boundaries beat large overlapping menus, because fewer descriptions load into context and fewer branches mean fewer mistakes.
They close by arguing that good tools feel natural to humans too, because both humans and agents benefit from high signal responses, predictable names, and compact outputs.
How to evaluate your tools once you’ve built them

The idea is to run tests in a structured way using direct API calls. You set up a simple loop where the agent gets a task, tries to solve it with the tools, and the outputs are checked. Each loop corresponds to one evaluation task.
When designing these evaluations, it helps to ask the agent not only for the final answer but also for its reasoning and feedback before it calls tools. This extra step often makes the model behave more logically and gives you clues about why it chose or avoided certain tools.
If you use Claude for evaluation, you can enable a feature called interleaved thinking. This shows the agent’s thought process while it is solving tasks. It helps you spot issues like unclear tool descriptions or confusing parameters.
Accuracy is important, but you should also measure other things. Track how long tool calls take, how many calls are made, how many tokens get used, and how often errors occur. These details reveal where agents are wasting effort and whether some tools should be merged or simplified.
The main point is that evaluation is not just about pass or fail. It is about collecting useful data that shows where tools can be improved and how agents actually use them.
Overall the Principles for writing effective tools

Pick the right tools, not too many.
Giving an agent a smaller set of well-designed tools works better than giving it every possible function, because agents have limited memory and can get confused if there is too much to process.Design tools for specific workflows.
Instead of building tools that return huge amounts of raw data, make tools that solve real tasks directly, like searching contacts or scheduling an event, so the agent doesn’t waste space reading irrelevant information.Combine steps into one tool when useful.
If a task usually takes multiple actions, put those into a single tool call, like scheduling a meeting that both finds a time and creates the event, so the agent’s job is simpler.Use namespacing to keep tools organized.
Give tools clear, grouped names (like “asana_search” or “jira_search”) so the agent knows which service or data source to use, reducing the chance of choosing the wrong tool.Return only useful information.
When tools send results back, they should give meaningful, human-readable details like names or file types instead of long technical codes, because agents understand and act better on clear context.Use natural language identifiers.
Replace confusing codes or random IDs with labels or names that make sense, since agents handle natural words more accurately and this avoids mistakes like hallucinations.Offer flexible output formats.
Allow tools to return different styles of answers, such as a short “concise” version when the agent only needs the main point or a “detailed” version when more context is needed, which saves memory and tokens.
🧠 12.5x memory savings vs. FP16 with new revolutinary technique - “"XQuant: Breaking the Memory Wall”

🧠 For many AI workflows, the Memory is becoming the main bottlenech rather than compute.
The slow, expensive part in modern AI is moving, storing, and reusing bytes, not raw FLOPs. Large language model decode is dominated by shuttling weights and the growing KV cache, so throughput is tied to memory bandwidth and capacity.
XQuant, developed by researchers from UC Berkeley, FuriosaAI, ICSI, and LBNL, reduces memory use for LLMs by accepting extra computation. The team says it effectively breaks the “Memory Wall.”
Their idea is: GPUs are built for heavy math, but they can’t move data in quickly enough. That’s why reducing memory operations, even at the cost of more compute, makes sense.
So, Instead of keeping the full KV cache, XQuant stores only the quantized layer inputs, known as X. During inference, it rebuilds Keys and Values from X as needed. This way, not everything stays in memory—some data is discarded and recomputed later. Let’s unpack how this works.
The XQuant method claims
10–12.5x memory savings vs. FP16
Near-zero accuracy loss
Beats state-of-the-art KV quantization🔥
The slow, expensive part in modern AI is moving, storing, and reusing bytes, not raw FLOPs. Large language model decode is dominated by shuttling weights and the growing KV cache, so throughput is tied to memory bandwidth and capacity.
The steady rise of long‑chain reasoning and test‑time scaling multiplies these memory costs. As models reason for longer and context grows, the KV cache scales with sequence length, so memory traffic, not FLOPs, sets both latency and cost.
What is KV cache and why its such a problem

Managing memory is a big challenge. For short inputs, model weights are the bulk of the memory load. For long inputs, the KV cache becomes the larger problem. This cache keeps the sequence representations for self-attention, which scale with sequence length and lead to memory limits.
Compression, especially quantization, is one of the popular fixes, but not the most optimal. Before that, it helps to understand the KV cache itself.
Every token in a transformer model is represented by 3 vectors: Key, Value, and Query. Keys represent token identity, Values carry content, and Queries are used to compare against Keys. The model checks each Query against stored Keys, then weights the Values to create the contextual output.
Without caching, autoregressive generation recalculates Keys and Values for all past tokens each step, which is inefficient. The KV cache instead stores them once so they can be reused.
With KV caching, inference becomes cheaper: the model only computes the new token’s Key, Value, and Query, while reusing the stored cache for everything else.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Key Proposals:
KV cache overhead rises linearly with context length and batch, making it the choke point.
FLOPs on GPUs are much faster than their memory throughput.
So instead of keeping KV in memory, just recompute.
In long sequences, the KV cache, the stored Keys and Values from past tokens, dominates memory and must move every step, which throttles bandwidth. XQUANT stores each layer’s input activations X in low bits, then recomputes Keys and Values using the usual projections during decoding.
That single change cuts memory by 2x versus caching both K and V, with small accuracy loss. This works because X quantizes well, and GPUs outpace memory bandwidth, so extra multiplies are a fair trade.
XQUANT-CL goes further by storing only small per layer deltas in X, leveraging the residual stream that keeps nearby layers similar. With this, the paper reports up to 10x memory savings with about 0.01 perplexity drop, and 12.5x with about 0.1.
With grouped query attention, they apply singular value decomposition to the weight matrices, cache X in a lower dimension, then rebuild K and V.
Despite using plain uniform quantization, results land near FP16 accuracy and beat more complex KV quantizers at the same footprint. Net effect, fewer memory reads per token, modest extra compute, and smoother long context serving.
This figure shows XQuant-CL during decoding.
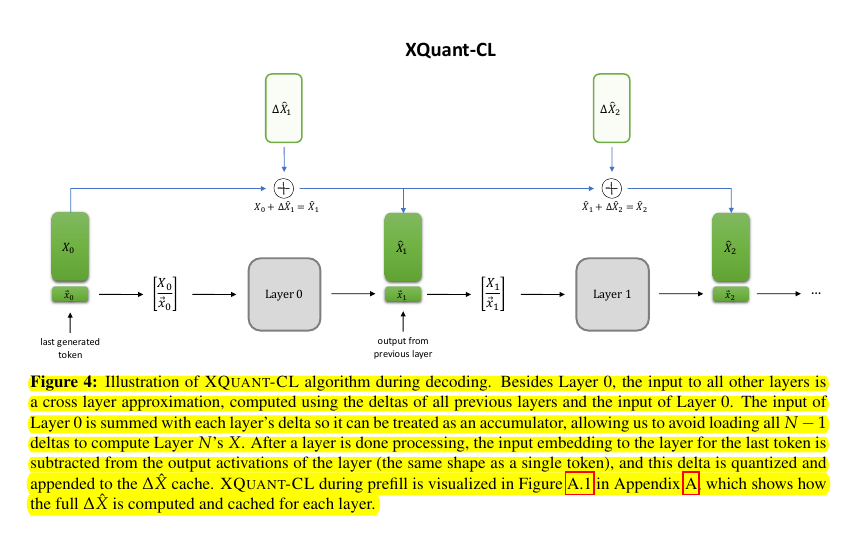
Layer 0 keeps a low-bit copy of the last token’s input activation as an accumulator. For each higher layer, the needed input is reconstructed by adding a small cross-layer difference to that accumulator, instead of storing a full input for every layer.
After a layer runs, it computes the difference between that layer’s output and its input for the last token, quantizes that small difference, and appends it to the delta cache. On the next step, the accumulator plus these stored deltas recreate each layer’s input, then K and V are rematerialized from that input.
Significance, residual layers change the signal only a little from layer to layer, so these deltas are tiny and quantize cleanly. Caching only tiny deltas cuts memory traffic during decode by a large factor with minimal quality loss, which helps because decode is memory-bound and extra multiplies are cheap on modern GPUs.
That’s a wrap for today, see you all tomorrow.