
🧠 Anthropic released a guide on building effective LLM agents
Anthropic's agent guide, NVIDIA's GPU dominance, FineMath dataset, and major releases from OpenCoconut, Meta, and OpenAI reshape LLM landscape.
Read time: 5 min 38 seconds
⚡In today’s Edition (23-Dec-2024):
🧠 Anthropic released a guide on building effective LLM agents.
🏆 Benchmarks show NVIDIA maintaining 14% lead over AMD despite MI300X's superior specs.
📡 FineMath: the best open-source math pre-training dataset with 50B+ tokens dropped on Huggingface.
🗞️ Byte-Size Brief:
ML Research Authors release 144-page RL paper covering value, policy, model methods
OpenCoconut launches open-source latent reasoning framework for step-by-step neural computation
Anthropic founders reveal AI scaling insights, linking early safety research to predictions
AbacusAI integrates multi-LLM code editor with unlimited quota for developers
Meta releases Video Seal: open-source neural watermarking with training code
OpenAI offers 1M daily GPT-4o/o1 tokens free for a select group of data-sharing users
🧑🎓 Deep Dive Tutorial
🧠 Fine-tune open LLMs in 2025 with HuggingFace
🧠 Anthropic released a guide on building effective LLM agents
🎯 The Brief
Anthropic released a comprehensive guide on building LLM agents, emphasizing a minimalist approach over complex implementations. The guide advocates for simple, composable patterns rather than sophisticated frameworks, introducing key workflows like prompt chaining, routing, and orchestrator-worker patterns.
⚙️ The Details
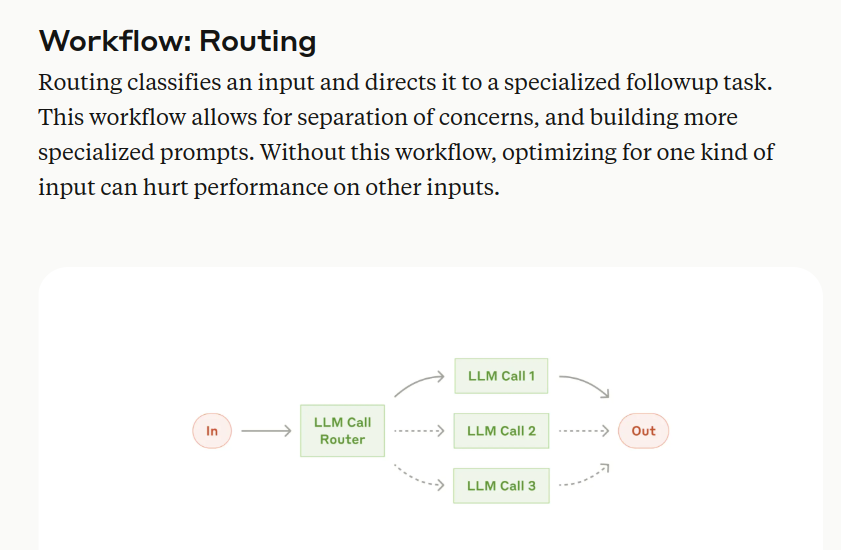
→ The guide distinguishes between two primary system types: workflows (following predefined paths) and agents (dynamically controlling processes). Implementation starts with an augmented LLM as the core building block, enhanced with retrieval, tools, and memory capabilities.
→ Key architectural patterns include prompt chaining for sequential tasks, routing for specialized handling, parallelization for simultaneous processing, and orchestrator-workers for dynamic task delegation. The evaluator-optimizer workflow enables iterative refinement through feedback loops.
→ Tool interface design emerges as crucial, requiring thorough documentation and testing. The guide recommends formats matching internet-native patterns while avoiding computational overhead. Agent implementation should prioritize simplicity, transparency, and measurable outcomes over architectural complexity.
→ Practical applications highlight customer support and coding agents as promising use cases, where success criteria are clear and feedback loops enable continuous improvement.
🏆 Benchmarks show NVIDIA maintaining 14% lead over AMD despite MI300X's superior specs
🎯 The Brief
SemiAnalysis conducted comprehensive benchmarking comparing AMD MI300X against NVIDIA H100/H200, revealing significant performance gaps and software ecosystem challenges in AMD's platform, despite competitive hardware specifications.
⚙️ The Details
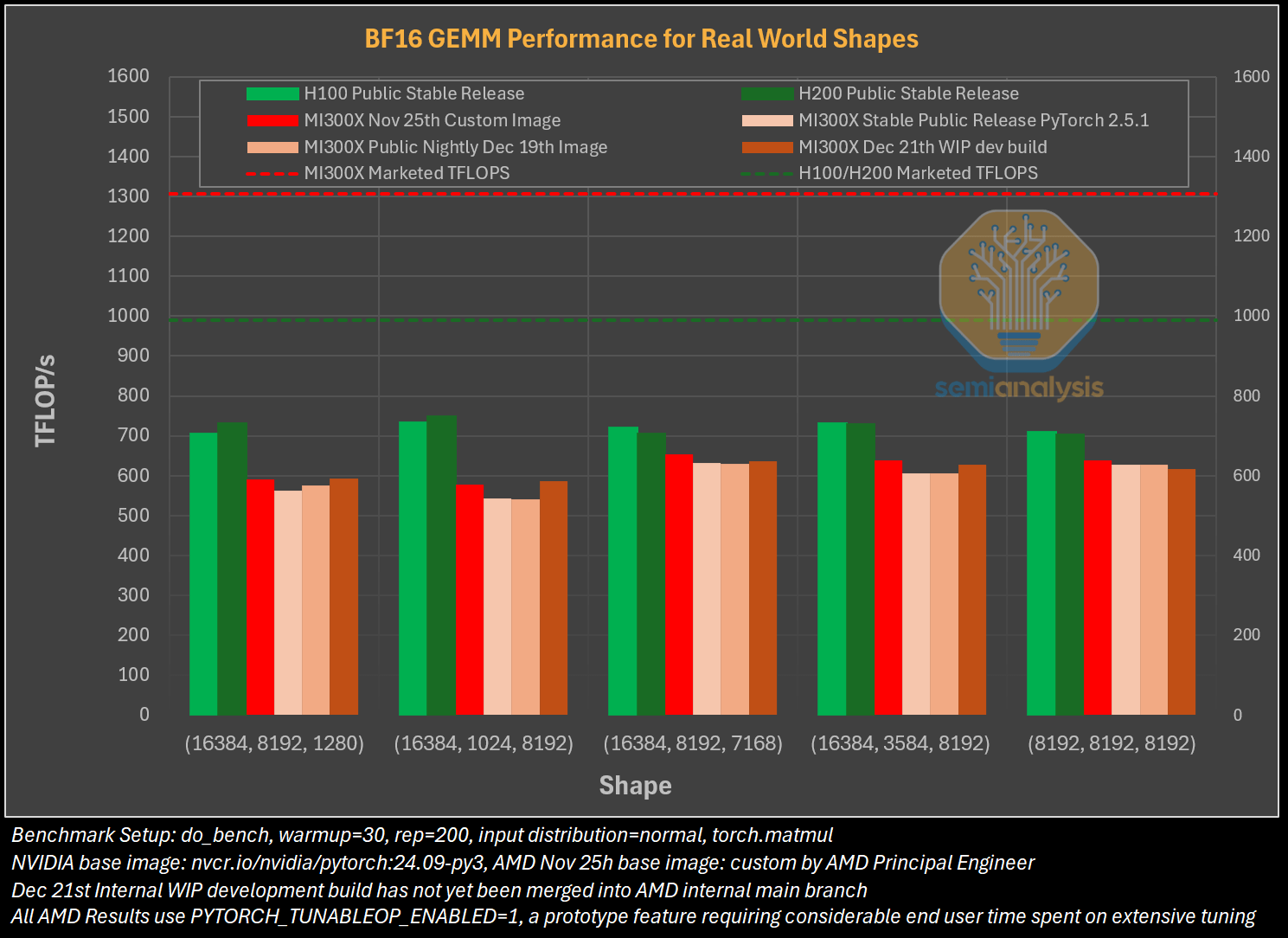
→ For BF16, MI300X's real-world performance, delivers only 620 TFLOP/s. In contrast, H100/H200 achieves 720 TFLOP/s.
→ The numbers are worse for FP8. The H100/H200 achieves ~1,280 TFLOP/s out of the marketed 1979 TFLOP/s. The MI300X, in comparison, only reaches ~990 TFLOP/s. Thus, for FP8, the MI300X is 22% slower than H100. This is for both inputs being of the e4m3 FP8 (i.e. 4 exponent bits and 3 mantissa bits) datatype
→ Networking performance heavily favors NVIDIA, with AMD's RoCEv2 running at half speed compared to NVIDIA's NVLink/InfiniBand for real-world message sizes. The MI300X particularly struggles with non-causal attention layers, performing 2.5x slower than H100/H200.
→ Total Cost of Ownership (TCO) advantages of MI300X are undermined by lower training performance per TCO on public stable releases, though this improves with custom development builds.
📡 FineMath: the best open-source math pre-training dataset with 50B+ tokens dropped on Huggingface.

🎯 The Brief
HuggingFace introduced FineMath, a 50B+ token mathematics dataset, featuring enhanced content extraction and quality filtering. Math remains challenging for LLMs and by training on FineMath considerable gains over other math datasets, especially on GSM8K and MATH are observed. This will make high-quality mathematical educational content more accessible for LLM training.
⚙️ The Details
→ The dataset comprises two main versions: FineMath-3+ with 34B tokens and 21.4M documents, and FineMath-4+ with 9.6B tokens and 6.7M documents. Content quality was ensured through a sophisticated pipeline using LLama-3.1-70B-Instruct for annotations and multilingual-e5-small classifier for filtering.
→ Technical improvements include switching from Trafilatura to Resiliparse for better math notation preservation, implementing OpenWebMath's pipeline, and restoring previously filtered LaTeX content. The dataset also incorporates filtered portions of InfiMM-WebMath-40B, adding 20.5B tokens for the 3+ version and 8.5B tokens for the 4+ version.
→ Released under ODC-By v1.0 license, which mandate attribution for data reuse while allowing commercial use and modifications. Key requirements include acknowledging original sources and maintaining transparency about changes. Free redistribution permitted with proper credits.
🗞️ Byte-Size Brief
A nice long paper is released, providing a comprehensive overview of Reinforcement Learning methods with lots of math. The paper presents value-based methods, policy optimization techniques, and model-based approaches. It covers both theoretical foundations and practical implementations with detailed mathematical proofs across 144 pages.
The github repo for OpenCoconut is released that implements a latent reasoning paradigm where we generate thoughts before decoding. AI systems can now think step-by-step internally before giving answers, just like humans do. OpenCoconut achieves this by manipulating neural networks' hidden states during computation, demonstrating improved performance on mathematical reasoning tasks through its continuous latent thought process.
The co-founders of Anthropic including Daniela Amodei, discuss the past, present, and future of Anthropic. They talk about, AI scaling breakthroughs, policies, and future goals. How the early AI researchers faced ridicule for taking safety seriously - until their predictions started coming true. Furthre discussion on language models, scaling laws, RLHF, and constitutional AI. Early work at Google Brain, OpenAI led to fundamental advances in model capabilities.
Abacusai introduced CodeLLM for Enhanced Coding. Its AI code editor integrating multiple LLMs like o1, Sonnet 3.5, and Gemini, offering unlimited introductory quota for developers. The new CodeLLM is available in a VS code-based client by the same name.
AIatMeta introduced Meta Video Seal, a neural video watermarking framework, detailing its application in protecting video content. They also made the Video Seal model available under a permissive license, alongside a research paper, training code and inference code.
OpenAI offering 1 million GPT-4o and o1 tokens a day for free, only for a selected user-group, if you share API usage with them.
🧑🎓 Deep Dive Tutorial
🧠 Fine-tune open LLMs in 2025 with HuggingFace
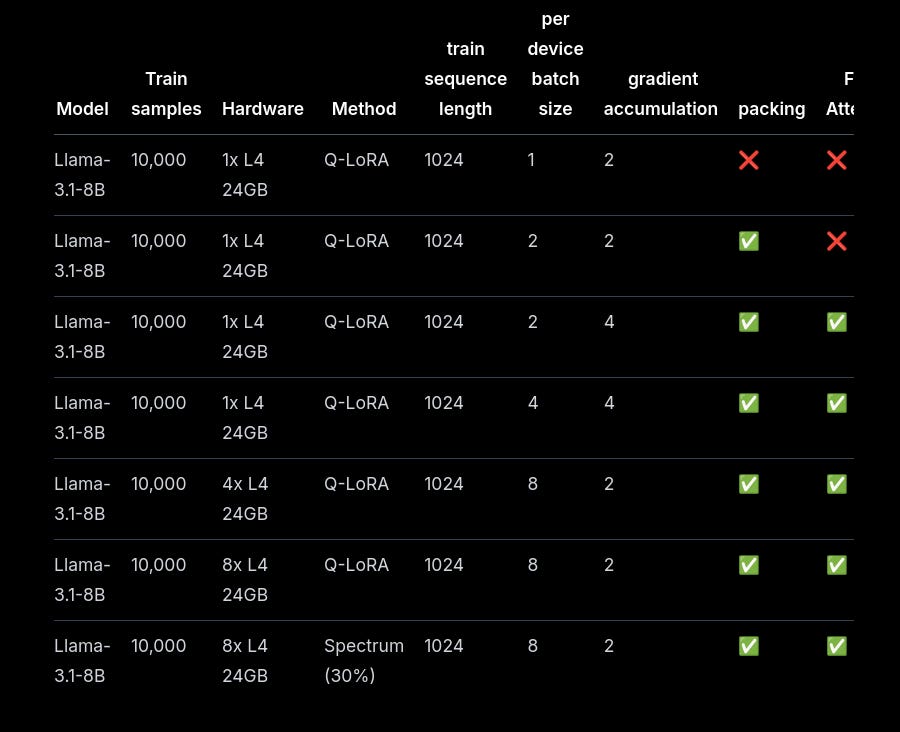
A comprehensive guide that demonstrates optimizing LLM fine-tuning using QLoRA and Spectrum methods on consumer GPUs.
📚 What you will learn:
Master efficient LLM fine-tuning optimization:
Flash Attention integration
Liger Kernels implementation
DeepSpeed ZeRO-3 configuration
Tensor Parallelism setup
Implement advanced training methods:
QLoRA with 4-bit quantization
Spectrum layer selection
Distributed training across GPUs
Dataset packing optimization
Performance optimization techniques:
Reduce training time from 6 hours to 18 minutes
Achieve 58% accuracy on GSM8K benchmark
Scale from single GPU to multi-node setups
Configure TGI for efficient model deployment
Practical implementation details:
Hugging Face trl library setup
OpenAI message format conversion
System prompt engineering
Model evaluation using lm-eval framework