
Anthropic released Claude Opus 4.6, with major gains across coding, knowledge, and reasoning benchmarks.
Claude 4.6 drops, GPT-5.2 hits milestone for long-horizon task completions, SpaceX acquires xAI, Perplexity Deep Research upgrades, Google Q4 insights, and AI infra costs cross $3T.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (3-Feb-2026):
🥇 Anthropic released Claude Opus 4.6, with major gains across coding, knowledge, and reasoning benchmarks.
🚨 SpaceX Acquired xAI Valuing SpaceX At $1 Tn, xAI At $250 B. $1.25T combined valuation.
📡“More than $3 trillion. That’s the staggering price tag to build the data centers needed to prepare for the artificial intelligence boom.”
🛠️ Massive achivement for GPT 5.2 for long-horizon task completions.
👨🔧 The AI’s progress is happening at insane rate.
🧠 Some takeaways from Google’s Q4 earnings.
🧑🎓 Perplexity released its an Advanced version of Perplexity Deep Research.
🥇 Anthropic released Claude Opus 4.6, with major gains across coding, knowledge, and reasoning benchmarks.
Claude Opus 4.6 builds on its predecessor’s coding skills and is better at planning, code review and debugging and operating reliably within large codebases.
The model is also better at pulling relevant information from large sets of documents, doing research and running financial analyses, with 1M token context in beta.
Opus 4.6 is thier first Opus-class model with 1M token context.
The API adds adaptive thinking, where the model decides when deeper reasoning is needed, 4 effort levels (set via /effort), and context compaction that summarizes older context near a threshold.
Supports 128k output tokens, and prompts past 200k tokens use $10/$37.50 (input/output) pricing instead of $5/$25.
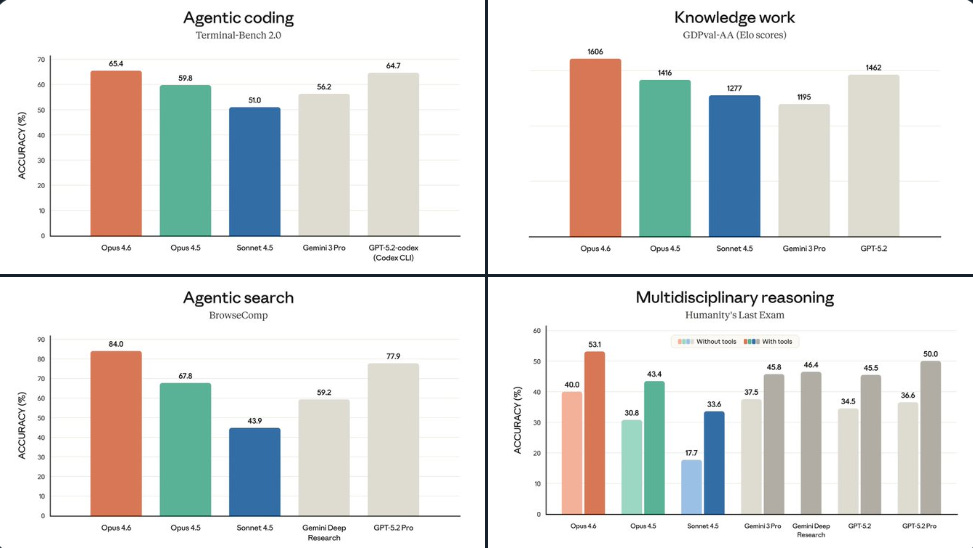
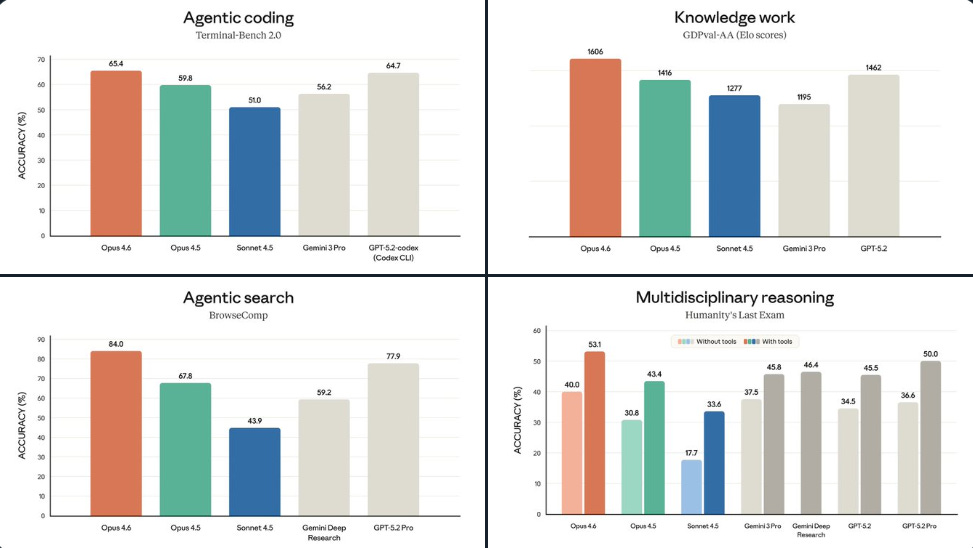
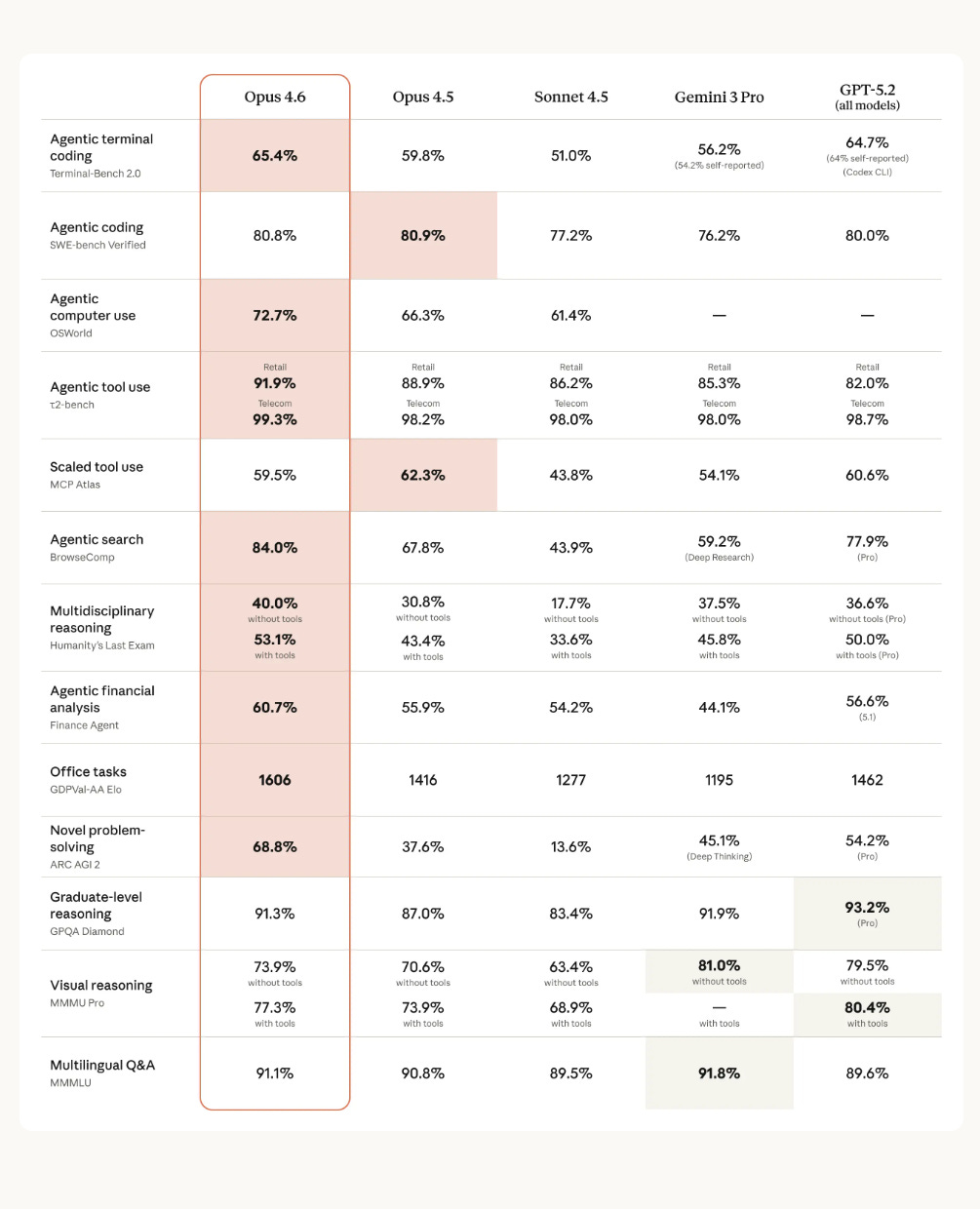
Versus Opus 4.5, the biggest gain in the % scored rows is on ARC AGI 2 (novel problem-solving), where Opus 4.6 goes from 37.6% to 68.8%, a +31.2 point jump.
Huge jump in BrowseComp (agentic search) score as well, where Opus 4.6 at 84.0% is much ahead of GPT-5.2, which is at 77.9%.
On Terminal-Bench 2.0, an agentic terminal coding test, it scores 65.4% versus 59.8% for Opus 4.5 and 64.7% for GPT-5.2.
On BrowseComp, a hard-to-find web info search test, it hits 84.0% versus 67.8% for Opus 4.5 and 77.9% for GPT-5.2.
On an 8-needle 1M-token needle-in-a-haystack retrieval benchmark, it scores 76% versus 18.5% for Sonnet 4.5.
Not everything improves, since Software Engineering Benchmark (SWE-bench) Verified is 80.8% versus 80.9% for Opus 4.5, and “Scaled tool use” is 59.5% versus 62.3% for Opus 4.5.
Claude Opus 4.6 is available today on claude.ai, our API, and all major cloud platforms. If you’re a developer, use claude-opus-4-6 via the Claude API. Pricing remains the same at $5/$25 per million tokens; for full details, see their pricing page.
Opus 4.6 now takes the crown as the best long-context model. 🫡

As measured on MRCR v2 8-needle at 256k and 1M, and it beats GPT-5.2 on the 256k range.
MRCR v2 (8-needle) is a long-context retrieval benchmark that checks whether a model can find and reproduce 8 specific facts hidden across a very long prompt, scored as mean match ratio (%).
Opus 4.6 scores about 92% to 93% at 256k tokens, while GPT-5.2 (xhigh) is 63.9% and Gemini 3 Pro (thinking) is 45.4%.
At 1M tokens, Opus 4.6 is specially incredible.
Opus 4.6 is 76.0% (max) or 78.3% (64k setting), while Gemini 3 Pro (thinking) is 24.5%, so it is far ahead of Gemini 3 Pro here too. However, to note, that GPT-5.2 is not shown in the 1M panel.
🚨 SpaceX Acquired xAI Valuing SpaceX At $1 Tn, xAI At $250 B. $1.25T combined valuation.

The largest M&A deal on record. Several outlets say the merged company is prepping an IPO and has floated internal share pricing around $527.
The tie-up folds xAI’s assets, including Grok, and control of X, into SpaceX’s orbit alongside launch, Starship and Starlink. On the numbers side, SpaceX’s financial base looks strong, with Reuters reporting about $8B profit on $15B to $16B revenue in 2025, which can help fund capital-heavy AI infrastructure.
Strategically, Musk says the point is space-based compute. SpaceX has already filed at the Federal Communications Commission to deploy “up to 1mn” orbital data-center satellites, arguing that solar-powered compute in orbit will beat Earth-based costs within 2 to 3 years.
The acquisition of xAI marks a new record for the world’s largest M&A deal, breaking a 25-year streak held since Vodafone’s $203 billion hostile takeover of Germany’s Mannesmann in 2000, according to LSEG data. There are material regulatory and governance angles that matter for valuation.
The U.S. Federal Communications Commission is reviewing SpaceX’s request for up to 1mn “orbital data center” satellites, which would shape capex needs and timing. The U.S. Department of Defense announced Grok’s use on Pentagon networks, which adds revenue opportunity but also scrutiny.
Cash generation to fund this combination looks strong. In 2025 SpaceX produced about $8B EBITDA. Many news reports estimate Starlink contributed about 50% to 80% of revenue of SpaceX, with roughly 9,500 satellites launched and about 9mn users.
📡“More than $3 trillion. That’s the staggering price tag to build the data centers needed to prepare for the artificial intelligence boom.”

~ Bloomberg published a very nice piece.
The big twist is that they are borrowing at such a huge scale that almost every kind of lending is getting pulled in, regular safe bonds, risky junk loans, private lenders, off-balance-sheet project vehicles , and packaged “bundles” of loans sold to investors. Hyperscalers and their partners are trying to finance land, buildings, grid hookups, and long-term power, at a scale that makes equity checks and subsidies a side note.
AI-related borrowers tapped at least $200B in 2025, and banks expect hundreds of billions more of issuance in 2026 that can lift borrowing costs across other companies. Instead of putting all the debt on the parent balance sheet, many deals use special purpose vehicles (SPVs) that borrow against long leases, so repayment depends on contracted rent rather than the developer’s survival.
Meta’s Louisiana “Beignet” financing is the template, a roughly $30B package where an SPV borrows and a long lease plus a residual value guarantee helps investors treat it as lower risk. Pricing splits by risk, with investment-grade bonds around 4%-4.5% coupons, meaning the bond’s stated interest rate, while some high-yield data center deals priced around 7%-9% and xAI debt carried a 12.5% fixed coupon.
A newer layer is GPU finance, where graphics processing units (GPUs), the chips that run AI math, are bought in a vehicle and rented out over about 5 years, matching expected depreciation. The main risks are refinancing cliffs, overbuilding and weaker lease renewals, fast chip obsolescence, construction delays, and power constraints that can turn “data center risk” into “power plant risk.”
🛠️ Massive achivement for GPT 5.2 for long horizon task completion.

That benchmark turns endurance into a single number by asking how long a task can be, in human-hours, before the model’s success rate drops to 50%, and GPT-5.2’s number is the highest METR has reported so far. The “hours” refer to human time to do the task, which is used as a proxy for how many steps, decisions, and opportunities for mistakes the task contains.
Also the same METR report show that the AI’s progress is happening at insane rate.

Then suddenly from 2025 bends the curve hard upward. Same benchmark, same yardstick, and most of the movement happens in 2025. This is at 80% success number, meaning it asks how long a software task can be, in human-hours, while the model still succeeds 80% of the time.
🧠 Key takeaways from Google’s Q4 earnings.

Gemini serving unit costs were reduced 78% during 2025 through model optimizations, efficiency gains, and better utilization.
Gemini Enterprise has already sold more than 8M paid seats after launching about 4 months ago.
More than 120,000 enterprises use Gemini, including 95% of the top 20 SaaS companies and over 80% of the top 100 SaaS companies. Gemini Enterprise handled over 5B customer interactions in Q4 and grew 65% YoY, showing scaled deployment rather than small pilots.
Gemini 3 Pro is described as the fastest-adopted model in Google’s history, and it processes about 3x as many daily tokens as Gemini 2.5 Pro.
Google’s 1st-party models now process over 10B tokens per minute via direct customer API use, up from 7B last quarter.
Google Antigravity, powered by Gemini, reached over 1.5M weekly active users a little over 2 months after launch.
Google’s 2026 CapEx is planned at $175B to $185B
In the US, daily AI Mode queries per user doubled since launch, indicating higher repeat usage once users adopt the AI experience.
AI Mode queries are about 3x longer than traditional searches, as a meaningful share now lead to follow-up questions
Search is shifting beyond text, with nearly 1 in 6 AI Mode queries using voice or images, and “Circle to Search” available on over 580M Android devices.
“Circle to Search” is a Google feature on Android that lets you start a search directly from whatever is on your screen. You press and hold on the navigation bar, then you circle, tap, scribble, or highlight an object, text, or image, and Google returns results about what you selected, without needing to switch apps. It increases multimodal search behavior, people can search using images and on screen content more naturally
- In December, nearly 350 Cloud customers each processed more than 100B tokens, and Q4 revenue from products built on Google’s generative AI models grew nearly 400% YoY.
🧑🎓 Perplexity released its an Advanced version of Perplexity Deep Research.

Outperformed other deep research tools on accuracy and reliability. Now available to max, rolling out to Pro in coming days. Perplexity says Advanced Deep Research runs every query on Opus 4.5
They also released DRACO– a cross-domain benchmark for Deep Research Accuracy, Completeness, and Objectivity. The DRACO benchmark comprises 100 carefully curated tasks spanning Academic, Finance, Law, Medicine, Technology, and other field.
Availability
The Advanced Deep Research upgrade is available to all Max users with higher usage limits, and it will be gradually rolled out to Pro users as well.
The open-sourced DRACO Benchmark, a benchmark grounded in how people actually use deep research, motivated by millions of production tasks across ten domains.

That’s a wrap for today, see you all tomorrow.
FYI Claude is from Anthropic, found guilty of pirating books, including mne. Educational/textbook and university press/academic authors represent almost half of the close to 500,000 works infringed in Bartz v. Anthropic (including mine!). Think twice before using tools based on stolen material!
https://www.taaonline.net/anthropic-settlement