
🗞️ Anthropic Releases Claude Sonnet 4.6, Approaches Opus 4.6 On Many Benchmarks At A Lower Price-point
MiniMax M2.5 becomes first open-weight model above 80% on SWE-Bench Verified, OpenAI adds Lockdown Mode against prompt injection, Peter Steinberger joins OpenAI, and China showcases humanoid robots.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (17-Feb-2026):
🗞️ Anthropic Releases Claude Sonnet 4.6, Approaches Opus 4.6 On Many Benchmarks At A Lower Price-point
🗞️ MiniMax M2.5 launched and its the first open-weight model to score over 80% on SWE-Bench Verified
🗞️ OpenAI added a new ChatGPT security switch called Lockdown Mode to reduce prompt injection risk when models touch the web or connected apps. It acts like a hard security boundary.
🚨 Sam Altmant officially announced that ClawdBot / OpenClaw creator Peter Steinberger has joined OpenAI 🦞
🗞️ China’s humanoid robots take center stage for Lunar New Year showtime
🗞️ Anthropic Releases Claude Sonnet 4.6, Approaches Opus 4.6 On Many Benchmarks At A Lower Price-point

Claude Sonnet 4.6 bring near-flagship capability to the default model most people actually use.
- Ships with a 1M-token context window in beta and becomes the default for Free and Pro users, while Sonnet pricing stays at $3/$15 per 1M tokens.
i.e. Sonnet gives about 67% more tokens per dollar than Opus for both input and output, which matters when most cost comes from long prompts and long answers.
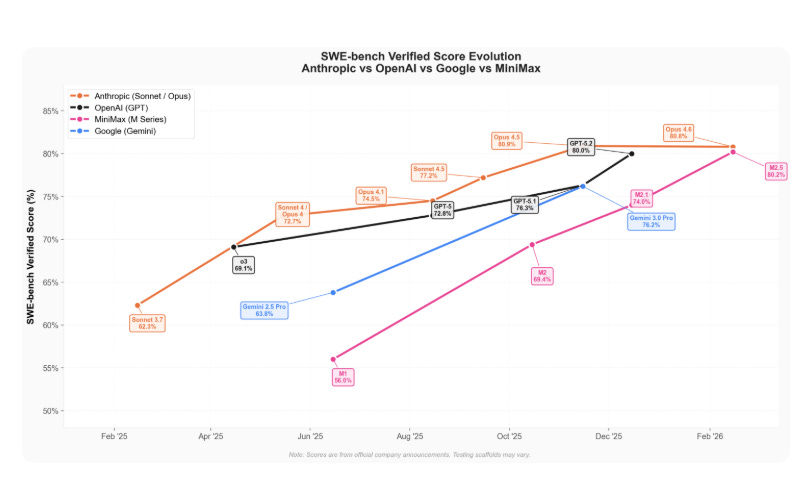
- On coding evaluations, Sonnet 4.6 improves Terminal-Bench2.0 from 51.0% to 59.1% and SWE-bench Verified from 77.2% to 79.6%, where SWE-bench Verified measures how often a model can correctly fix real GitHub issues under tests.
- On the API, Sonnet 4.6 is priced at $3/$15 per 1M input/output tokens, while Opus 4.6 is $5/$25 per 1M input/output tokens.
- Tasks that used to force a jump to the pricier Opus tier are now often workable on Sonnet, especially for coding and office-style document work.
The usual gap in this lineup is that cheaper models lose the thread in long sessions, miss constraints, and compensate by copying code, overengineering, or giving shallow plans.
Sonnet 4.6 targets that with better instruction following and long-context reasoning, plus optional adaptive thinking and extended thinking on the developer platform, and beta context compaction that summarizes older turns to stretch usable context.
- In Claude Code preference tests, early users picked Sonnet 4.6 over Sonnet 4.5 about 70% of the time, and even over Opus 4.5 about 59% of the time, citing fewer hallucinations and less “laziness” and overengineering.
- For computer use, OSWorld-Verified rises from 61.4% on Sonnet 4.5 to 72.5% on Sonnet 4.6, roughly matching Opus 4.6 at 72.7%, and OSWorld is a benchmark of completing real app tasks by clicking and typing without special connectors.
Opus 4.6 still leads for deepest reasoning like large refactors and coordinating multiple agents when correctness matters most.
Sonnet 4.6 is is super strong at financial analysis

On Finance Agent v1.1, which scores how well a model performs multi-step finance tasks in an agent setup, Sonnet 4.6 scores 63.3% while Opus 4.6 scores 60.1%.
The 1M-token context window in beta matters for finance because the hard part is usually stitching together details that are far apart, like a risk factor that explains a margin change, or a footnote that changes how a headline KPI should be interpreted.
It also adds tools aimed at long sessions, like context compaction, which is useful when an analysis runs for hours and the model needs to preserve the evolving thesis, assumptions, and open questions while new documents keep getting added.
Claude Sonnet 4.6 is available now on all Claude plans, Claude Cowork, Claude Code, our API, and all major cloud platforms. They have also upgraded our free tier to Sonnet 4.6 by default—it now includes file creation, connectors, skills, and compaction.
🗞️ MiniMax M2.5 launched and its the first open-weight model to score over 80% on SWE-Bench Verified

MiniMax just dropped the open M2.5 and M2.5 Lightning, and they’re state-of-the-art, but priced at 1/20th the cost of Claude Opus 4.6.
Tuned for agent work like coding, search, and office deliverables.
Scores 80.2% on SWE-Bench Verified, a test-driven real repo bug-fix benchmark, and 51.3% on Multi-SWE-Bench.
Dropped the cost of the frontier by as much as 95%.
Input price $0.30/M and output is $1.20/M and same performance as Opus 4.6 and GPT 5.2 on benchmarks and 95% discount in price.
Particularly great in agentic tool use for enterprise tasks, including creating Microsoft Word, Excel and PowerPoint files,
At $1 per hour with 100 tps, infinite scaling of long-horizon agents now economically possible
MiniMax M2.5 is the fastest model to reach 80% on SWE-Bench Verified.
How to Get Started with MiniMax M2.5
Sign Up: Go to MiniMax Platform (https://platform.minimax.io/login) and create an account
Get Your API_Key: Navigate to Account → Settings → API Keys
Select Model: Follow the documentation (https://platform.minimax.io/docs/guides/text-generation) and select model: MiniMax-M2.5
Quick Test: Use the Anthropic API format endpoint for easy testing
Base URL: https://api.minimax.io/anthropic
Model Name: MiniMax-M2.5
🗞️ OpenAI added a new ChatGPT security switch called Lockdown Mode to reduce prompt injection risk when models touch the web or connected apps. It acts like a hard security boundary.

The change is aimed at people who are high-value targets, like executives and security teams, where a single tricked session can leak sensitive context into an attacker-controlled channel.
Prompt injection works by hiding instructions in external content so the model treats attacker text as higher priority than the user’s intent, which can lead to data exfiltration from chats or connected tools.
Lockdown Mode creates a hard boundary by deterministically disabling some tools and by limiting browsing to cached content so no live outbound network requests leave OpenAI’s controlled network.
Admins can turn it on in workspace settings by creating a dedicated role, and they can whitelist specific apps and even specific actions inside those apps, with audit visibility via enterprise logging and the Compliance API Logs Platform.
OpenAI also added “Elevated Risk” labels in ChatGPT, ChatGPT Atlas, and Codex to flag capabilities like internet access, and to explain what enabling them changes and why the risk rises.
No benchmark numbers are published here, but the practical result is clearer: fewer network paths exist for an attacker to steer the model, and admins get a tighter control surface for the users who need it most.
This looks most useful for regulated teams that already rely on role-based access controls and audit logs, and it should reduce surprise behavior when agents are allowed to reach outside a sandbox.
It also pressures the broader ecosystem to treat networked agent features as a distinct security domain, not as a default convenience toggle.
🗞️ China’s humanoid robots take center stage for Lunar New Year showtime

Four fast-rising humanoid robot startups, Unitree Robotics, Galbot, Noetix, and MagicLab, showed off their machines at the gala, a huge televised event in China that plays a similar cultural role to the Super Bowl in the United States.
The first 3 skits put humanoid robots front and center, including a long martial-arts segment where more than a dozen Unitree humanoids pulled off complex fight routines with swords, poles, and nunchucks, all while moving very close to child performers.
One sequence was especially technically bold: it copied the shaky steps and backward tumbles of China’s “drunken boxing” style, highlighting progress in multi-robot coordination and fault recovery, meaning a robot can stand back up after it falls. The opening skit also gave major screen time to ByteDance’s AI chatbot Doubao, while 4 Noetix humanoids joined human actors in a comedy sketch and MagicLab robots did a synchronized dance with human performers during the song “We Are Made in China.”
All this buzz around China’s humanoid robot scene comes as big names like AgiBot and Unitree get ready for initial public offerings this year, and as local AI startups drop a wave of frontier models during the profitable 9-day Lunar New Year holiday.
China accounted for 90% of the roughly 13,000 humanoid robots shipped globally last year, far ahead of U.S. rivals including Tesla’s Optimus, according to research firm Omdia.
Morgan Stanley projects that China’s humanoid sales will more than double to 28,000 units this year.
Elon Musk has said he expects his biggest competitor to be Chinese companies as he pivots Tesla toward a focus on embodied AI and its flagship humanoid Optimus.
🚨 Sam Altmant officially announced that ClawdBot / OpenClaw creator Peter Steinberger has joined OpenAI 🦞

Peter Steinberger, who created the AI personal assistant now known as OpenClaw, has joined OpenAI.
As per various news report
They’d work on personal agents at OpenAI
They’re discussing setting up a foundation to keep the open source project alive
Meta also tried to recruit Steinberger.
Peter Steinberger said on Lex Fridman’s podcast that he’s been spending $10-20k/month out of pocket to fund OpenClaw
So he said partnering with a big AI lab might be the fastest way to develop the project
OpenClaw went viral because it enables multi-model agents with full computer control. But because setup still takes some technical know-how, adoption has stayed limited so far.
That’s a wrap for today, see you all tomorrow.