
📢 Anthropic research finds AI Could Double U.S. Labor Productivity Growth, Anthropic Study Finds
Anthropic claims AI could 2x US labor productivity, while Google bets on cheap compute over speed and rolls out visual learning in Gemini; NVIDIA defends GPU dominance.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-Nov-2025):
📢 Anthropic research finds AI Could Double U.S. Labor Productivity Growth, Anthropic Study Finds
🥊 NVIDIA pushed back on talk that Google’s TPUs might surpass its AI platform, saying its tech still delivers “better performance and flexibility” compared to any ASIC.
🏆 Google is trying to win AI by making compute cheap, not by beating Nvidia on raw speed.
🛠️ Google ships interactive images in Gemini for deeper, visual academic learning
👨🔧 The OpenAI and Google battle is starting to look messy.
📢 Anthropic research finds AI Could Double U.S. Labor Productivity Growth, Anthropic Study Finds
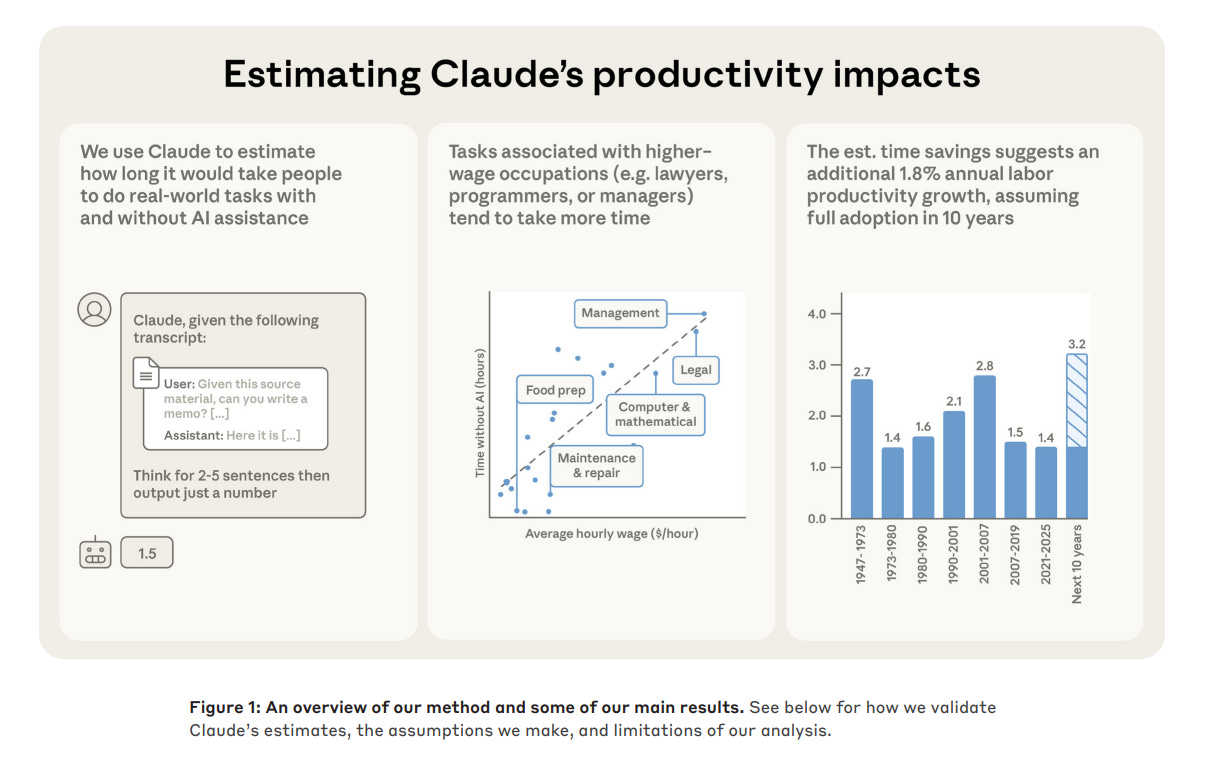
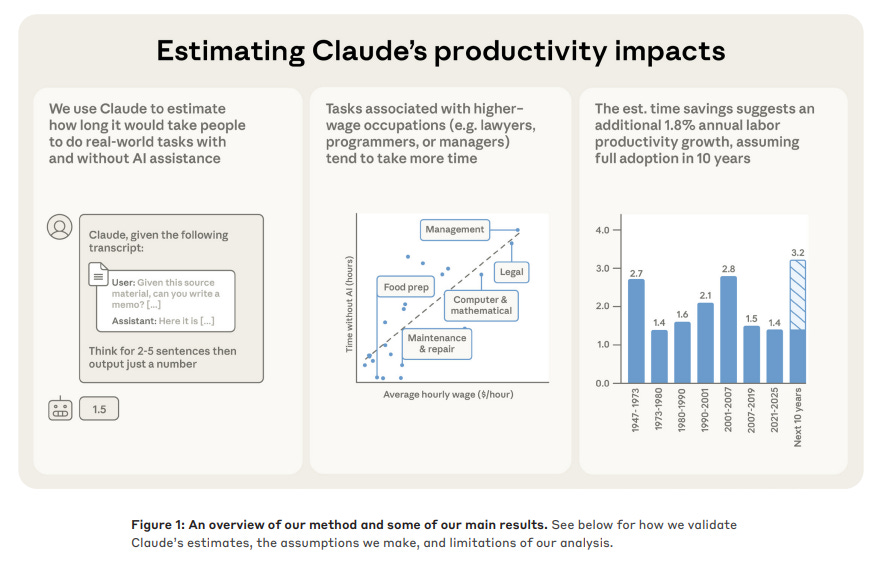
Anthropic analyzed 100,000 conversation logs to estimate that current AI models could increase US labor productivity growth to 1.8% annually. In the context of a national economy, 1.8% is an enormous number because it represents an additional boost on top of what we already have, effectively doubling the speed at which the economy improves.
It Doubles Our Speed Since 2019, US labor productivity has grown at a sluggish rate of about 1.8% per year. The report suggests AI could add another 1.8% on top of that.
To get this number, researchers didn’t rely on theoretical lab tests but instead used a privacy-preserving method to study actual user interactions with Claude. They had the model look at anonymized transcripts to estimate how long a task would take a human professional versus how long the session actually took.
The data suggests that the median task sees a massive 80% reduction in completion time when using AI assistance. It turns out that highly paid professionals like software developers and lawyers are getting the biggest raw time savings per task.
For example, complex management or legal tasks that usually take around 2 hours saw the most significant compression in duration. In contrast, lower-wage tasks like food preparation or transportation showed much smaller opportunities for acceleration.
To ensure the AI wasn’t just hallucinating these time estimates, the team validated the model against real-world software development tickets from JIRA. The model’s ability to predict task duration achieved a correlation of 0.44, which is surprisingly close to the 0.50 correlation seen in human developer estimates.
If you apply these efficiency gains across the entire economy, the model suggests a potential 1.8% annual boost to productivity over the next decade. However, there is a significant catch to these optimistic numbers.
The study only measures the time spent inside the chat interface and cannot account for the time humans spend validating or fixing the AI’s work. This means the actual productivity boost is likely lower once you factor in the “integration tax” of checking the output and moving it into production.
Also, the paper doesn’t address unemployment, despite Anthropic CEO Dario Amodei warning that AI could eliminate half of entry-level white-collar jobs and push unemployment to 20% within five years.
🥊 NVIDIA pushed back on talk that Google’s TPUs might surpass its AI platform, saying its tech still delivers “better performance and flexibility” compared to any ASIC.

The context is that reports say Meta and Anthropic may spend billions of dollars on Google TPUs, and some analysts think this could eventually pull around 10% of revenue away from NVIDIA’s AI business, so NVIDIA is clearly defending the idea that GPUs remain the default choice. NVIDIA is saying that Google’s TPUs are custom ASIC chips that are very efficient for specific AI workloads like large scale inference on a narrow set of models, especially when Google controls the whole stack from model design to data center layout.
NVIDIA says this strength is also a weakness, because ASICs are tuned to particular frameworks or functions, so once workloads, model types, or software stacks change, those chips cannot easily adapt to new use cases. By contrast, NVIDIA GPUs plus CUDA, libraries, and tooling form a general platform that can run almost any AI model, in training or inference, across many clouds and on premises, which is what they mean by performance plus versatility plus fungibility. NVIDIA also reminds everyone that Google is itself a major NVIDIA customer, so TPUs are a strong in house option but still sit inside a market where NVIDIA hardware is everywhere.
🏆 Google is trying to win AI by making compute cheap, not by beating Nvidia on raw speed.

Nvidia sells GPUs to clouds with a big 70%+ margin that sits on top of manufacturing and R&D cost and raises cloud prices. Google builds TPUs for itself at near manufacturing cost, adds no vendor margin, and then pushes aggressive cloud prices.
That is vertical integration, chip to network to cloud, so pricing power comes from owning the whole stack. Training likes the fastest chips, but once a model is live, most money goes to inference, which values stable, low-cost hardware.
If inference becomes 90% of spend, the winner is whoever offers the lowest cost-per-token at scale. Google’s plan is to keep cutting token cost with TPUs and pass savings through cloud pricing.
If that holds, buyers may care less about peak speed and more about price, reliability, and availability. Nvidia will stay strong in frontier training, but its ability to charge high margins could shrink if workloads move to cheaper inference on TPUs. The distribution flywheel is a huge leverage for Google too, because Google can fill TPU capacity across Search, YouTube, Android, and Workspace.
📝 Tencent’s released open source HunyuanOCR, a 1B Parameter End to End OCR Expert VLM, Ranks top on many benchamrks
HunyuanOCR stands as a leading end-to-end OCR expert VLM powered by Hunyuan’s native multimodal architecture. With a remarkably lightweight 1B parameter design, it has achieved multiple state-of-the-art benchmarks across the industry.
🎯 Demo | 📥 Model Download | 📄 Technical Report | 🌟 Github
Better than Deepseek-ocr and only 1B param.
A 1B parameter OCR model that reaches SOTA on multiple public benchmarks while staying in the small model class that is practical to deploy.
HunyuanOCR follows Tencent’s Hunyuan multimodal design and combines a native resolution video encoder, an adaptive visual adapter, and a lightweight language model so images or video frames go straight to text in one pass.
The key idea is end to end OCR, so instead of having separate models for detection, recognition, layout, and post processing, the single model learns to go from pixels to final structured text directly.
Tencent trains it on large application focused datasets and then uses online reinforcement learning so the model gets feedback from real world usage and improves its reasoning and formatting choices over time.
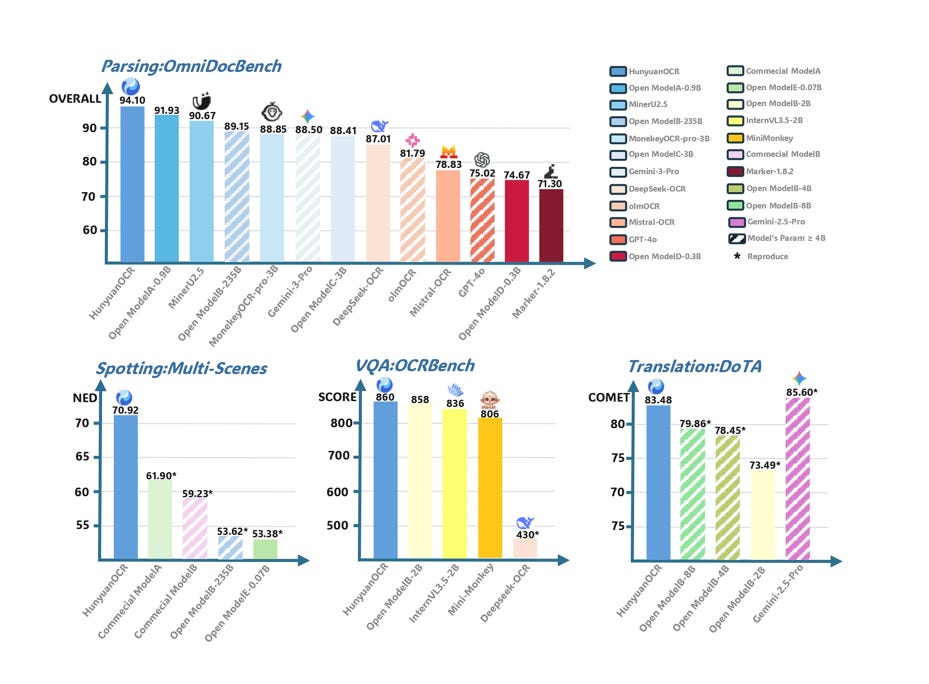
On complicated document parsing HunyuanOCR reaches 94.1 points and on a broad OCR benchmark it scores 860, which makes it the top model under 3B parameters while competing with much larger commercial systems.
The model handles documents, handwriting, stylized fonts, signs, receipts, and ads, and it also supports translation for 14 languages while keeping the original reading order.
For math heavy or table heavy files it can emit formulas in a typesetting friendly text form and can express tables in a structured markup like layout, which makes it easy to feed the output into downstream systems.
🛠️ Google ships interactive images in Gemini for deeper, visual academic learning
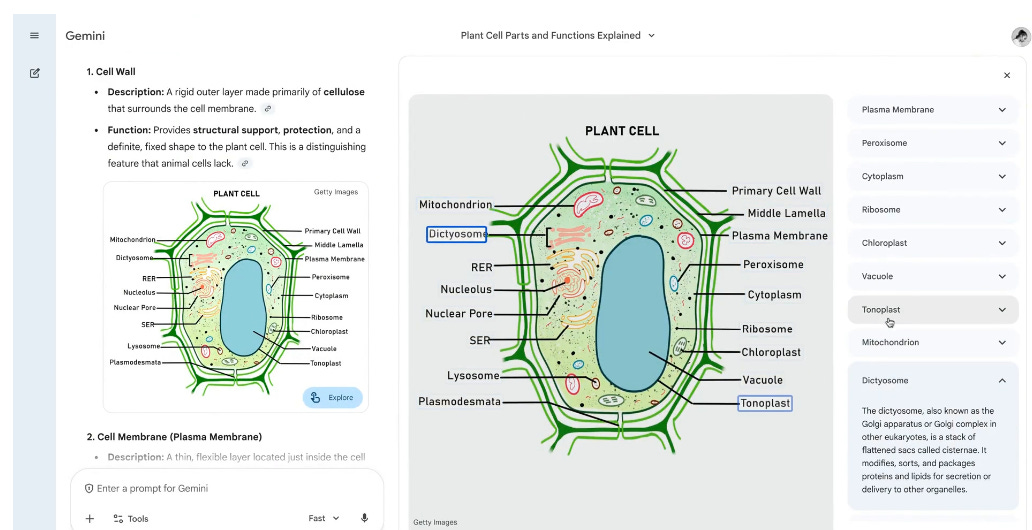
Each tap opens a small panel with a plain definition, a short explanation, and related pieces of the same concept.
Because the picture sits inside the chat, Gemini can track which region was touched and handle follow up questions about that exact piece.
This is a modest update but it pushes Gemini toward grounded multimodal learning where text answers are tied to specific image regions instead of floating above the picture.
👨🔧 The OpenAI and Google battle is starting to look messy.

The Information published a new piece, “Why OpenAI Should Worry About Google’s Pretraining Prowess”
The math is brutal: openai is burning $8.5B yearly with a $7B loss coming and a 38x revenue multiple, while Google has unlimited funds, custom chips, and unmatched data.
Beyond technology, Google possesses everything from in-house TPU development, cloud services, the Chrome web browser, and hardware devices like Pixel phones. It is one of the few ‘full-stack companies’ capable of handling all stages—from model creation to service deployment—alone.
That’s a wrap for today, see you all tomorrow.
Broo, how'd you do it ? How'd you add a custom domain to your substack ? Rohan-paul.com