
Anthropic reveals multi-agent Claude research wizardry powering 90% accuracy boost

Read time: 6 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (14-Jun-2025):
🤖 Anthropic just dropped the beautiful explanation of how they built a multi-agent research system using multiple Claude AI agents.
I will go over how parallel Claude agents trade tokens for breadth and speed in research.

A MUST read for anyone building multi-agent system.
Key Learning:
Anthropic found that one Claude model hits context and time walls when it tries to research broad questions.
The team solved this by turning Claude into a coordinator that hires many smaller agents to search in parallel.
The lead agent writes a plan, spawns subagents with focused goals, and later merges their reports with precise citations. This parallel sweep uses separate context windows, spending more tokens but uncovering facts a sequential run would miss.
Keeping the swarm reliable required checkpoints, smart retries, full execution traces, and rainbow deployments so live agents survive code updates. These safeguards make a non-deterministic many-agent workflow feel like a sturdy web service.
The detailed report shows how a group of Claude models can investigate the web together faster than any single model could manage.
🚧 The Problem With Single Agents
Traditional retrieval-augmented generation lines up one query, grabs similar text, and stops. That linear path misses facts that sit outside the first chunk set, and it slogs through steps that could have run in parallel. Anthropic found that even Claude Opus 4, running alone, stalled on broad tasks such as “list every board member across the Information Technology S&P 500.”
Research questions rarely follow a straight path, so a fixed pipeline leaves gaps. One lead agent plans the investigation, spawns subagents that roam in parallel, and later condenses their notes into a coherent answer.
Anthropic’s Solution:
So Anthropic made a lead agent plans research steps, spawns specialized subagents to search in parallel, and then gathers and cites results. It covers architecture, prompt design, tool selection, evaluation methods, and production challenges to make AI research reliable and efficient.
Single-agent research assistants stall when queries branch into many directions. So Anthropic links one lead Claude with parallel subagents to chase each thread at once, then fuses their findings.
🧠 Why Multi-Agent Architecture Helps
Each subagent brings its own context window, so the system can pour in many more tokens than a single model would hold. Anthropic measured that token volume alone explained 80% of success on BrowseComp, and adding subagents pushed performance 90.2% past a lone Claude Opus 4 on internal tasks.
Running agents in parallel also cuts wall-clock time because searches, tool calls, and reasoning steps happen side by side rather than one after another.
🛠️ Architecture Walkthrough
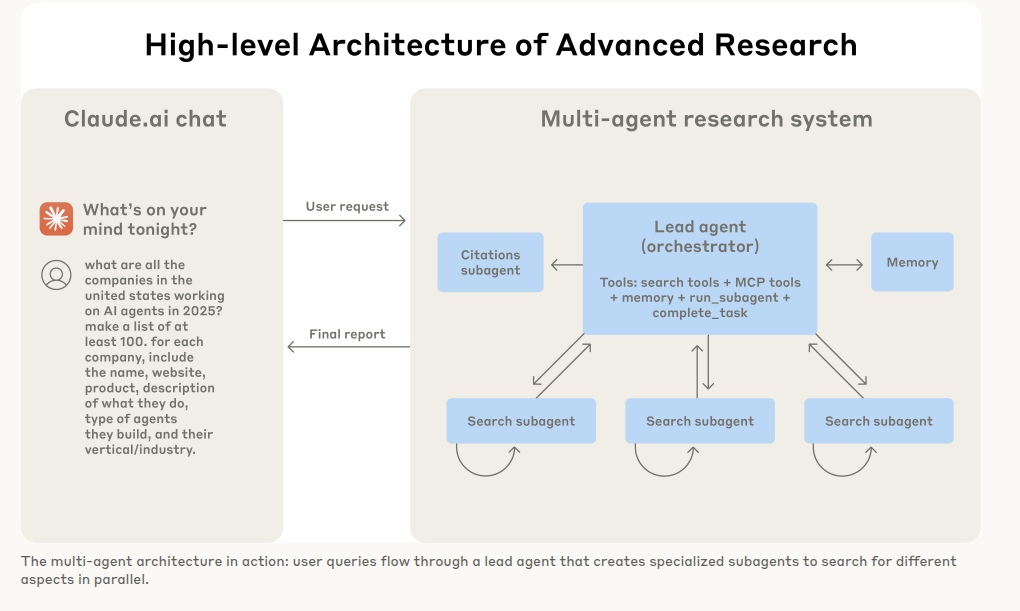
The orchestrator-worker pattern gives the lead agent control while letting specialists act independently. A user query lands with the lead Researcher, which thinks aloud, stores the plan in memory, and distributes focused jobs like list company directors or trace chip shortages.
Subagents call web search or workspace tools, judge results with interleaved thinking, and return concise digests. A citation agent then pins every claim to a source before the answer reaches the user.
🔧 Prompt Engineering Heuristics

Anthropic treated every prompt as user-interface code. The lead agent learns to
• think first, then delegate with a clear objective, required output format, and tool list
• scale effort: 1 agent and ≤10 tool calls for a quick fact, >10 agents only for open-ended studies
• start with short, broad search strings, shrink scope only after reading early hits
They also give the model a visible scratchpad via extended thinking mode so it can write reasoning steps that humans and later evaluators can inspect.
🧪 Evaluation Strategy

Because many valid action paths exist, Anthropic grades outcomes, not step-by-step traces. An LLM judge scores factual accuracy, citation match, coverage, source quality, and tool efficiency on a 0-1 scale and issues pass-fail flags. Human reviewers still sweep for edge cases such as subagents favoring SEO spam over academic PDFs. Independent analysts echo the need for combined automated and manual checks in multi-agent systems.
🔧 Engineering for Reliability

Anthropic keeps its Research agents alive through the kinds of battle-tested safeguards familiar from distributed systems, but adapted to the quirks of large-language-model workflows. The core idea is simple: never let an agent lose its memory, never let a transient glitch throw away minutes of reasoning, and never kill in-flight work when shipping new code. Everything else flows from that principle.
Why long-running agents need extra care
A Claude agent may call dozens of tools, branch into many sub-agents, and hold partial results that only make sense together. If a process crashes at step 17 of 30 and has to start over, users pay twice and may still hit the same fault. Anthropic therefore treats each agent run as a small stateful service that must resume after any crash, just like a database recovering its log.
Checkpoints: snapshots after every safe point
The platform persists a lightweight snapshot of the agent’s plan, conversation window, and tool outputs after major actions. When a worker dies, the orchestrator reloads the last snapshot and asks Claude to “continue from here,” so progress is lost only back to the previous checkpoint, not to the beginning.
Full tracing for debugging
A tracing layer records every prompt, tool selection, HTTP call, and model response. When a user reports “the agent missed obvious data,” engineers can open the trace, see the exact search query that failed, and patch prompts or tools without guesswork. Fine-grained logs of decision paths make non-deterministic LLM runs reproducible enough to fix.
Rainbow deployments: updating code without stranding agents
LLM agents can run for many minutes. If new code is rolled out in a single shot, any agent using the old binary disappears mid-task. Anthropic instead shifts traffic through “rainbow” deployments: every commit gets its own color, new requests flow to the new color, and old pods stay alive until their agents finish. Once no live sessions reference a color, the pod is drained. This strategy, borrowed from Kubernetes practice, gives zero-downtime releases even for stateful agents.
Putting the pieces together
Checkpoints cap the cost of a crash, retries absorb transient noise, graceful degradation yields best-effort answers, traces turn vague bug reports into concrete fixes, and rainbow deployments let the team ship improvements several times a day without dropping anyone’s research run. Together these tactics convert a fragile chain-of-thought into a robust, resumable workflow that feels as reliable as any traditional web service.
📈 Trade-Offs and Best-Fit Tasks

Multi-agent research consumes about 15× the tokens of chat and only pays off when the answer’s value outweighs that cost. Projects that need a shared giant context or tight real-time coordination, like most coding tasks, still strain current agents. Parallel, information-heavy investigations remain the sweet spot.
Overall Anthropic’s Research system shows that advanced large language model swarms stay dependable only when guarded by classic ops ideas: checkpoints capture state so crashes cost seconds, smart retries and fallback paths absorb flaky APIs, exhaustive traces expose the exact prompt or tool that misfires, and rainbow deployments slide new code beneath live agents without breaking their flow.
By threading these safeguards around parallel Claude workers, the team turns a non-deterministic, token-hungry workflow into a resumable, observable service that can keep digging until the answer is found.
The result is fewer reruns, almost zero user-visible downtime, and the freedom to ship many updates each day while research tasks carry on.
That’s a wrap for today, see you all tomorrow.