
🚨 Anthropic Wins In Landmark AI Lawsuit: Judge Says AI Training On Books Without Authors’ Permission Can Continue
Anthropic’s copyright win, Google’s Gemini CLI, AI replacing resumes, OpenAI’s Office twin, NVIDIA’s NVFP4 4-bit Blackwell boost, and Google’s agent-security blueprint.

Read time: 12 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (25-Jun-2025):
🚨 Anthropic Wins In Landmark AI Lawsuit: Judge Says AI Training On Books Without Authors’ Permission Can Continue
🏆 Google unveils Gemini CLI, an open-source AI tool for terminals
💼 Opinion: AI vs HR: The End of the Resume
🗞️ Byte-Size Briefs:
OpenAI is reportedly building productivity tools for ChatGPT that mirror Google Workspace and Microsoft Office.
NVIDIA introduces NVFP4 4-bit format for Blackwell GPUs, cutting memory 3.5X, boosting energy efficiency up to 50X.
🧑🎓 Deep Dive: Introduction to Google’s Approach to AI Agent Security
🚨 Anthropic Wins In Landmark AI Lawsuit: Judge Says AI Training On Books Without Authors’ Permission Can Continue

According to the lawsuit, Anthropic sought to create a “central library” of “all the books in the world” to keep “forever.”
US Federal Judge ruled Anthropic may train its AI on published books without authors’ permission. This is the first court endorsement of fair use protecting AI firms when they use copyrighted texts to train LLMs. But Anthropic must go to trial for allegedly using pirated books.
The judge called AI training "spectacularly" transformative, comparing Claude to aspiring writers learning from established authors rather than copying them.
"First, Authors argue that using works to train Claude’s underlying LLMs was like using works to train any person to read and write, so Authors should be able to exclude Anthropic from this use. But Authors cannot rightly exclude anyone from using their works for training or learning as such. Everyone reads texts, too, then writes new texts. They may need to pay for getting their hands on a text in the first instance. But to make anyone pay specifically for the use of a book each time they read it, each time they recall it from memory, each time they later draw upon it when writing new things in new ways would be unthinkable.
For centuries, we have read and re-read books. We have admired, memorized, and internalized their sweeping themes, their substantive points, and their stylistic solutions to recurring writing problems." - According to the court document.
⚙️ Two distinct uses: The order splits Anthropic’s conduct into two buckets: training copies that feed the model, and library copies parked for any future purpose. Anthropic said everything was “for training,” yet the court saw a second, non-transformative goal: building a permanent research library.
🤖 Training wins fair-use protection: Court says, Using complete books to map token relationships is “spectacularly transformative.” No verbatim outputs reach users, and the system’s purpose—generating fresh text—is orthogonal to selling the originals.
The judge rejected the idea that computers should be barred from doing what writers can do. He explains that a closer match is a past case where an AI tool was trained on court opinions so it could draft fresh legal text, and that earlier court called the training fair use.
He adds that the AI’s new writing stands far enough from the source material that copyright holders cannot claim control over it. Citing a Supreme Court precedent and the Constitution, he stresses that this kind of reuse helps knowledge grow without hurting authors’ incentive to create.
He ends by calling Anthropic’s training “quintessentially transformative,” because the model learns from books only to produce fresh, non-substituting text.
Why scanning the Anthropic’s own paper books into digital files is lawful. Because Anthropic paid for each print copy, it can dispose of that copy as it likes, including destroying it after making one digital version. The format shift adds no extra copies, only makes storage easier and searching possible, so the judge calls the change transformative and therefore fair use. The authors cannot show that Anthropic shared these scans outside the company, so the court sees no harm to the market.
So now what's next for this lawsuit?
Anthropic wins the right to train on paid books, yet still faces a jury over its pirate cache. Anthropic must return to court for a jury trial that will look only at the 7 million pirate books. Judge Alsup has already said the focus will be actual or statutory damages, including willfulness penalties that jump when bad faith is proven.
💰 How the numbers climb: Copyright law sets $750 as the rock-bottom fee for every infringed book, and it reaches $150 000 when willfulness appears. Multiplying the floor figure by 7 million puts the minimum exposure north of $5 billion, even before any punitive multiplier.
📚 Licensing versus scraping: Anthropic already spends millions buying used books to scan, showing there is a real market for lawful training copies. If licensing deals emerge, they could offset courtroom risk and become the industry’s new normal.
Great Github for learning end-to-end, code-first tutorials covering every layer of production-grade GenAI agents

This github repo is a goldmine for end-to-end, code-first tutorials covering every layer of production-grade GenAI agents, guiding you from spark to scale with proven patterns and reusable blueprints for real-world launches.
5.9K+ Starts ⭐️ in a week.
Helps you build, evaluate, secure, and ship AI agents fast. 25+ runnable tutorials covering orchestration, memory, deployment, observability, security, multi-agent coordination, fine-tuning, evaluation; integrates LangChain, Redis, RunPod, Tavily, Streamlit, FastAPI.
Learn end-to-end patterns for orchestration, memory, evaluation, and GPU deployment.
Has tutorials and reference implementations, for integrations across LangChain, Redis, Streamlit, and RunPod.
🏆 Google unveils Gemini CLI, an open-source AI tool for terminals

Google is launching a new agentic AI tool that will put its Gemini AI models closer to where developers are already coding.
Gemini CLI embeds Gemini AI into the terminal as an open-source agent. It is licensed under Apache 2.0 for community audits and contributions. It supports code understanding, content generation, research, and task automation.
Developers get a free personal Code Assist license with access to Gemini 2.5 Pro. That unlocks a 1 million token context window and the largest free limits: 60 requests per minute and 1,000 per day.
Professionals can use Google AI Studio or Vertex AI keys for usage-based billing or upgrade to Standard or Enterprise Code Assist plans. Gemini CLI integrates with Code Assist for VS Code using the same multi-step agent tech.
Built-in tools let you ground prompts with Google Search, extend via Model Context Protocol or bundled extensions, and customize system prompts. You can invoke it non-interactively within scripts to automate workflows.
While most people will use Gemini CLI for coding, Google says it designed the tool to handle other tasks as well. Developers can tap Gemini CLI to create videos with Google’s Veo 3 model, generate research reports with the company’s Deep Research agent, or access real-time information through Google Search.
Google also says Gemini CLI can connect to MCP servers, allowing developers to connect to external databases.
Gemini CLI’s non-interactive mode simply lets you call the gemini command with a prompt (or prompt file) and have it exit after returning a result, so you can embed it in any script or pipeline . You just need to authenticate once (either by signing in interactively or by exporting GEMINI_API_KEY). Github here.
Here’s how to set it up step by step:
Install Node.js version 18 or higher.
Launch the CLI with npx https://github.com/google-gemini/gemini-cli
Or install it globally via npm install -g @google/gemini-cli
Choose a color theme when prompted.
Authenticate with your Google account to enable 60 requests per minute and 1,000 requests per day.
Once authenticated, the CLI is ready.
Create or navigate to a project directory and run gemini to start the shell.
Enter a prompt like “Write me a Gemini Discord bot that answers questions using a FAQ.md file I will provide.”
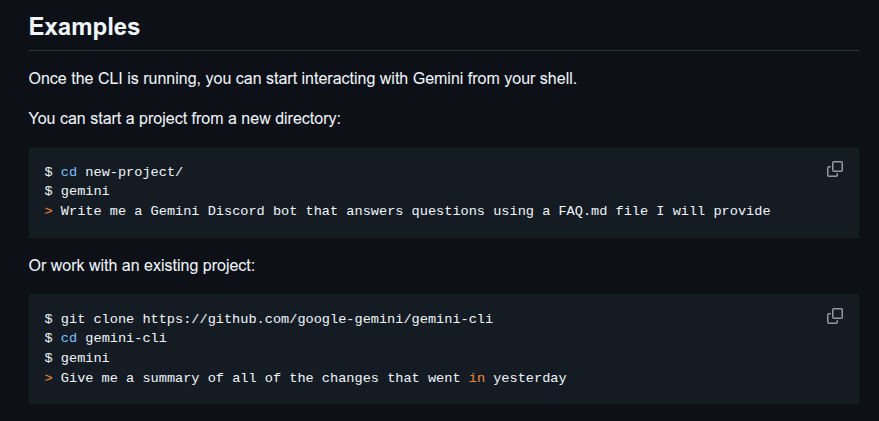
Or clone the repo with
git clone https://github.com/google-gemini/gemini-cli.
Then cd into gemini-cli, run gemini, and type “Give me a summary of all of the changes that went in yesterday.”
In both cases the CLI issues one model request and exits, printing the AI’s answer to stdout. That output can be parsed (for example with jq if JSON output is enabled) and chained into downstream steps in CI jobs, cron tasks, build scripts or any shell-based workflow.
💼 My Opinion Piece: AI vs HR: The End of the Resume

🗂️ Background: LinkedIn now receives about 11,000 applications every minute, a rise of 45% in one year. Most of that gain comes from LLMs that can rewrite a job post into a résumé in seconds. Recruiters like Katie Tanner found more than 1,200 applications to a single opening in only few days and needed months to sift through the pile. Traditional filters break because every résumé already contains every keyword.
🤖 Candidate Automation
Job seekers run entire job-hunt pipelines through paid AI agents. The software scrapes listings, matches skills, rewrites bullet points, and submits forms while the user sleeps. Some tools even sit in a browser tab and answer screening questions in real time. Invisible text and prompt injections can hide extra tokens that only a parser can see, potentially allowing candidates to game screening systems. This trick fools naïve keyword scanners and lets weak candidates float to the top. Fraud escalates: identity-for-hire rings place workers under false names, as seen in recent federal indictments.
🏢 Employer Defense Stack
Firms answer with their own models. e.g. Chipotle’s chatbot, nicknamed Ava Cado, runs the first interview and cuts decision time by 75%. LinkedIn offers recruiters a natural-language search that drafts follow-up notes and suggests shortlists. Detection utilities flag duplicated phrasing, timing anomalies, or large blocks written with identical embeddings. Bias remains a risk because the data used to train these filters still skew toward common Western names or against Black and female résumés, recreating known discrimination patterns.
📊 Why Traditional Signals Fail
A résumé once signaled effort and fit because writing one cost time. Language models collapse that cost to near zero. Goodhart’s law appears (when a measure becomes a target, it ceases to be a good measure): once recruiters focus on keyword matches, candidates optimize for those words rather than genuine skill. Volume overwhelms human review cycles, so both sides push for more automation, pushing humans further from each other.
• Candidates fire off hundreds of tailored documents with one prompt.
• Recruiters reply with higher walls of algorithmic triage.
• Each step shrinks the window for authentic conversation.
🛠️ Technical Assessment Paths
To recover signal, some teams swap static documents for tasks that models cannot yet spoof at scale. Live coding or design sessions reveal reasoning because the candidate must speak and adapt. Portfolio walkthroughs show actual work artifacts, not templated claims. Short paid trials let a hiring manager watch real execution within company systems. These methods cost more per applicant, but they avoid the resume arms race and surface true competence faster than a stack of cloned documents.
🔄 Arms Race Outlook
As long as résumé generation stays cheap and instant, each incremental filter will invite a new evasion. The loop stops only when the evaluation itself becomes a performance that is hard to fake with current automation. Until then, applications will keep arriving by the thousand, bots will interview other bots, and hiring teams will refine tools that decide which conversations reach a human desk.
🗞️ Byte-Size Briefs
OpenAI is reportedly building productivity tools for ChatGPT that mirror Google Workspace and Microsoft Office. It will deliver real-time docs, group chat. It adds multiuser chat (built but unreleased), new record transcription mode, file uploads in Projects, Teams/Drive/DropBox connectors after Canvas launch—pressuring Microsoft Office.
Just yesterday OpenAI officially announced, “ChatGPT connectors for Google Drive, Dropbox, SharePoint, and Box are now available to Pro users (excluding EEA, CH, UK) in ChatGPT outside of deep research. Perfect for bringing in your unique context for everyday work.”NVIDIA introduces NVFP4 4-bit format for Blackwell GPUs, cutting memory 3.5X, boosting energy efficiency up to 50X. Most inference with 8 bit or 16 bit numbers, so they move a lot of data and waste power. NVIDIA’s new NVFP4 format drops that to 4 bit while keeping almost all accuracy. People want faster answers from large language models without buying more hardware. NVFP4 shrinks every weight to 4 bit, adds smart scaling so quality barely moves, and plugs straight into the new Blackwell chips.
🧑🎓 Deep Dive: Introduction to Google’s Approach to AI Agent Security

Google published on AI agent security: An Introduction to Google’s Approach to AI Agent Security
AI agents act on their own, so a mistake or a tricked prompt can cause real-world harm. Google lays out a double safety net: hard coded rules stop dangerous commands, and an extra layer of AI checks the grey areas.
🚀 Why agents matter: An agent is not just a chatbot; it senses its surroundings, plans steps, and fires off actions like sending emails or moving money. That autonomy saves time but also opens a path for wrong clicks, misread commands, or hostile prompts that twist goals.
🔥 The twin threats: Rogue actions happen when the agent does something the user never wanted, often because malicious text posed as harmless data. Sensitive data disclosure happens when attackers trick the agent into leaking secrets through tool calls, links, or plain text.
🛡️ Why old tricks fail: Classic software guards rely on predictable code paths, but an agent’s reasoning is probabilistic, so the same input may not yield the same output. Purely trusting the model is risky because prompt injection can still steer it, yet locking every action breaks the point of using an agent at all.
🧑✈️ Human stays in charge: Every agent must know exactly which human it obeys, and it must pause for confirmation before any move that is costly, irreversible, or security-sensitive. Shared agents need clear identities so one teammate cannot silently fire actions on another’s behalf.
🔒 Keep powers tight: The agent only gets the minimum tools needed for the current task, and those permissions shrink or grow as the context changes. It cannot hand itself new rights, and the human can always inspect or revoke any granted tokens.
🧐 Watch every move: Logs record inputs, chosen tools, parameters, outputs, and even mid-thought notes so auditors and users can spot odd behaviour fast. Each action is tagged with whether it only reads data or can change state, helping automated checks judge risk on the fly.
🏰 Hard guardrails: A runtime policy engine intercepts every tool call, weighs its danger, and either blocks, allows, or asks the user. Rules can say “never spend over 500” or “warn before emailing after reading untrusted text”, giving deterministic limits that testers can verify.
🤔 Smart countermoves: AI-based guards add resilience by spotting shady patterns that rules miss, such as odd role language inside data, but they are fallible, so they sit behind the policy engine rather than replace it. Regular red-team drills and regression tests probe both layers for new holes and keep the shield updated.
That’s a wrap for today, see you all tomorrow.
another very helpful article