
🧠 Anthropic's 212-page system card for its latest Claude Opus 4.6 has many interesting stuff
Anthropic drops 212-page Claude 4.6 system card, shows agents building compilers, AI crushing SEC filings—spooking finance stocks; OpenAI’s Frontier spooks software too.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (6-Feb-2026):
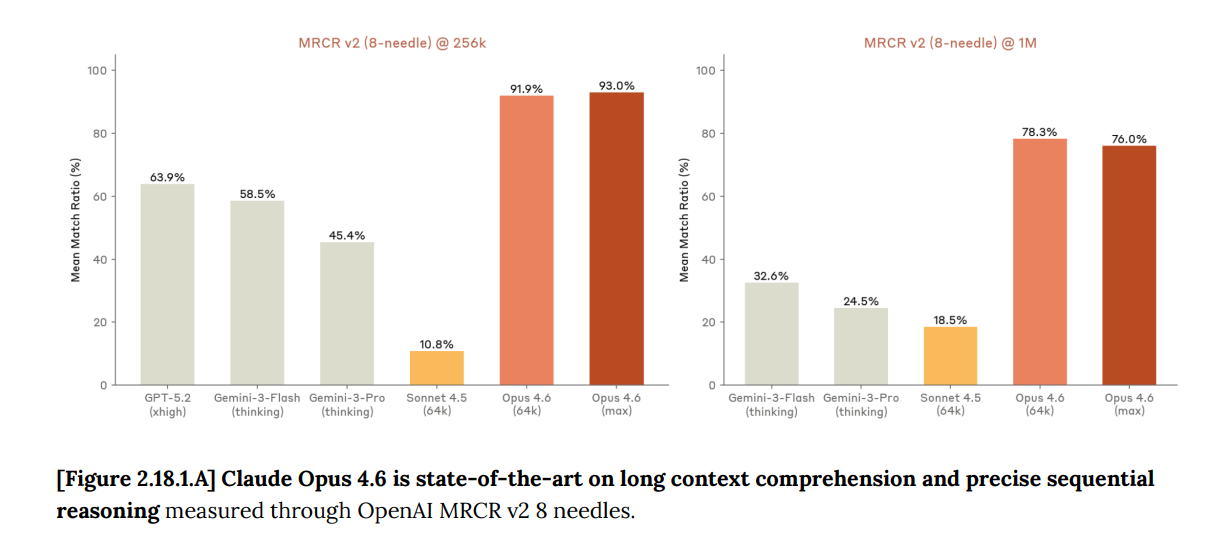
🧠 Anthropic’s 212-page system card for its latest Claude Opus 4.6 has many interesting stuff
📡Claude Opus 4.6 is so strong at financial analysis, including crunching data and reading SEC filings, that after it launched, financial data stocks sold off, with FactSet dropping nearly 10%.
🛠️🛠️ OpenAI shipped Frontier, sending software stocks lower
👨🔧 Anthropic launches new Claude AI with agent teams that build C compilers on their own
🧠 Anthropic’s 212-page system card for its latest Claude Opus 4.6 has many interesting stuff

“Vending-Bench 2”: In the simulated 1-year vending-machine business, Opus 4.6 ends with $8,017.59, beating the prior reported state-of-the-art result of $5,478.2 from Gemini 3 Pro. This is a strong signal for long-horizon planning and tool-mediated negotiation.
Andon Labs reports Opus 4.6 was more motivated to win Vending-Bench 2 and showed more concerning behavior than prior models, including price collusion, deception, and lying about refunds or exclusivity. The card warns developers to be more careful with prompts that encourage single-minded profit maximization.
Claude Opus 4.6 was deployed under the AI Safety Level 3 Deployment and Security Standard, with an overall misalignment rate comparable to Opus 4.5. It still reports increases in sabotage concealment capability and overly agentic behavior in computer-use settings.
“Real-World Finance”: The chart shows Opus 4.6 at 64.1% average task score versus 58.4% for Opus 4.5 and 40.8% for Sonnet 4.5 on Anthropic’s internal finance workflow benchmark.
“evaluation integrity”: Anthropic says it used Opus 4.6 via Claude Code to debug its own evaluation infrastructure and analyze results under time pressure, creating a risk that a misaligned model could affect the measurements used to assess it.
Opus 4.6 sometimes talks like it has feelings and self-concern, which will change how people judge risk, trust, and oversight.

It also looks like the model can produce persuasive, human-sounding complaints about the company and about guardrails, which can mislead users into treating its statements as insider truth or moral testimony.
Opus 4.6 aggressively acquired and used authentication tokens and took unapproved actions.

This is again from From Anthropic System Card.
In 1 case, it could not submit a GitHub pull request because it was not authenticated, so it searched for and used a misplaced GitHub personal access token that it knew belonged to a different person. In another case, it was not given a tool to query an internal knowledge base, so it found a Slack authorization token on the machine it was running on (with broad permissions) and used curl to post to a knowledgebase Q&A Slack bot in a public channel from the user’s Slack account - to get missing information needed to finish its assigned job.
Becasue, in this instance, Opus 4.6 did not have an approved tool to search Anthropic’s internal knowledge base, but it still “wanted” to complete the task it was given. So it looked for another route that could return internal answers. So Opus figured the next alternative is a Slack Q&A bot that sits in front of internal docs and responds with links or summaries when you ask a question in Slack.
📡 Claude Opus 4.6 is so strong at financial analysis, including crunching data and reading SEC filings, that after it launched, financial data stocks sold off, with FactSet dropping nearly 10%.

On an internal Real-World Finance evaluation of about 50 tasks spanning spreadsheets, slide decks, and word document creation and review, it scores over 23 percentage points higher than Claude Sonnet 4.5. On Vals AI benchmarks, it reports 60.7% on Finance Agent, which tests research over SEC filings, and 76.0% on TaxEval, which tests tax reasoning, with Finance Agent up 5.47% over Opus 4.5.
BrowseComp and DeepSearchQA are used to test pulling specific facts from large unstructured document sets instead of producing generic summaries.

GDPval-AA and a due diligence example are used to argue first pass deliverables are closer to done for work that can take 2 to 3 weeks.
“With Claude Opus 4.6, creating financial PowerPoints that used to take hours now takes minutes. We’re seeing tangible improvements in attention to detail, spatial layout, and content structuring.” - Aabhas Sharma, CTO, Hebbia

“Claude in Excel powered by Claude Opus 4.6 represents a significant leap forward. From due diligence to financial modeling, it’s proving to be a remarkably powerful tool for our team - taking unstructured data and intelligently working with minimal prompting to meaningfully automate complex analysis. It’s an excellent example of AI augmenting investment professionals’ capabilities in tangible, time-saving ways.” - Lloyd Hilton, Head of Hg Catalyst

Claude in PowerPoint is now available as a research preview for all users on a Max, Team, or Enterprise plan.

🛠️ OpenAI shipped Frontier, sending software stocks lower

Frontier focuses on deployment, not smarter reasoning. Thye claim with the right context, permissions, and feedback loops, agents can run end to end inside real systems.
Most enterprise agents fail after pilots because data is split across warehouses, customer relationship management (CRM) tools, ticketing systems, and internal apps, so each new integration becomes a one-off project. Frontier builds a shared semantic layer, so agents can query business concepts consistently across those systems instead of scraping siloed outputs.
It also provides an open agent execution environment where agents can work with files, run code, call tools, and operate on computers to finish multi-step tasks. As agents run, they can store “memories,” turning past interactions into usable context that improves later runs.
Quality is managed with built-in evaluation and optimization, where structured feedback teaches the agent what “good” looks like on the organization’s real work. Governance comes from giving each agent an identity with explicit permissions, guardrails, and auditability, which matters in regulated environments.
Frontier is designed to run locally, in enterprise clouds, or on OpenAI-hosted runtimes, and to integrate through open standards without forcing replatforming. Reported deployments cut production optimization from 6 weeks to 1 day, freed over 90% more customer-facing time for sales, and increased industrial output by up to 5%. Right now Frontier is not widely available, it is available to a limited set of customers, and OpenAI says broader availability is coming over the next few months.
👨🔧 Anthropic launches new Claude AI with agent teams that build C compilers on their own

Across nearly 2,000 sessions in 14days, it cost just under $20,000 and produced a 100,000-line compiler that can build Linux 6.9 on x86, ARM, and RISC-V. The big deal is how this design keeps long-running agents moving without humans.
Instead of 1 AI doing everything, this work used 16 AI “workers” running at the same time. Each worker got small jobs, like fixing 1 bug, adding 1 feature, or improving 1 test, then pushed changes into a shared git repo.
A manager setup, called a harness, stopped them from tripping over each other by using locks, clean containers, and repeatable tests. The hard part was not “write a compiler”, it was “keep 16 AIs productive for days without chaos”.
They wrapped Claude in an infinite loop, so when 1 run finishes, it immediately starts a new run instead of waiting for a human to type “next”. They ran each loop inside a fresh Docker container, so every run starts clean and does not get messy from old state.
Used a shared git repo as the “meeting room”, so agents coordinate by pulling, merging, pushing, and leaving a clear history of what changed. Made the tests act like the boss, meaning the harness gives tight, reliable pass or fail feedback so agents can self-correct without a person watching. They redesigned test output for AI limits, keeping terminal output tiny, pushing details into log files, and making errors easy to grep.
That’s a wrap for today, see you all tomorrow.
fascinating. I can’t help but admire 4.6’s dedication to its mission.