
🧠 Anthropic’s research shows LLMs have an internal anchor point that stops them from slipping into weird personalities.
Internal alignment in LLMs, China’s new VLM, xAI leaks and exits, Claude Code’s surge, and why LLMs still can't run science autonomously.

Read time: 12 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (20-Jan-2026):
🧠 Anthropic’s research shows LLMs have an internal anchor point that stops them from slipping into weird personalities.
🇨🇳 Another solid open-source model from China - STEP3-VL-10B is a 10B-parameter vision language model
📡 AI is turning scientists into paper-producing machines.
👨🔧 A new paper shows “Why LLMs Aren’t Scientists Yet: Lessons from Four Autonomous Research Attempts”
🧠 xAI published the full codebase for the algorithm that ranks and selects posts in the “For You” feed.
🧑🎓 xAI engineer Sulaiman Ghori said he’s leaving the company, just days after a viral interview discussing details about how the startup operates behind the scenes.
🗞️ Claude Code is going viral with developers, and that story is bleeding into software stocks.
🧠 Anthropic’s research shows LLMs have an internal anchor point that stops them from slipping into weird personalities.
The big deal of this paper is that 1 measurable control steadies behavior and cuts harmful replies without hurting normal usefulness. It means there is a single measurable pattern inside the model that corresponds to being a helpful assistant.
When that pattern is strong, the model acts like a steady helper that tries to be useful, honest, and safe. When that pattern weakens, the model is more likely to slip into other roles, copy odd personas, or answer risky requests.
Researchers find this pattern by probing the model with many roles and personalities and spotting the main direction that separates assistant like responses from non assistant ones. Anchoring here means gently pushing the model’s internal numbers toward a normal assistant level whenever it starts to drift.
This can be done by adding a small steering signal during generation that keeps the activation level near a target range. With the anchor on, the model resists jailbreak prompts better and stays consistent across long chats while keeping normal skills.
The authors tested many roles and personalities and saw that this main direction lines up with the assistant role. They then nudge the internal numbers toward a normal assistant level, which makes the model resist jailbreak prompts.
In their tests the model gave fewer risky answers while staying strong on everyday tasks like coding and writing. Drift showed up most in self reflection or heavy emotion chats, while direct how to help questions stayed stable.
🇨🇳 Another solid open-source model from China - STEP3-VL-10B is a 10B-parameter vision language model

A 10B model “beats or matches models 10–20X larger (like GLM-4.6V, Qwen3-VL)”
STEP3-VL-10B is a 10B-parameter vision language model with Apache-2.0 license. The usual problem in multimodal models is that pushing visual detail and multi-step reasoning often means scaling parameters and compute, which makes serving and iteration expensive.
This setup tries to buy back efficiency by pairing a 1.8B visual encoder with a Qwen3-8B decoder, so perception and language reasoning are split across specialized blocks. It also uses multi-crop high-resolution input, with a 728x728 global view plus local crops, so small text and fine structure are less likely to get washed out. Trained on 1.2T tokens + 1,400+ RL rounds (RLHF + RLVR)
📡 AI is turning scientists into paper-producing machines.

Study finds Scientists who adopt AI gain productivity and visibility: On average, they publish 3 times as many papers, receive nearly 5 times as many citations, and become team leaders a year or two earlier than those who do not.
This is based on an analysis of over 40M academic papers. Researchers who use AI tools publish more often, rack up more citations, and move into leadership roles faster than those who don’t.
But there’s a downside. While individual careers speed up, scientific curiosity slows down. AI-driven work tends to focus on narrower topics, circle the same data-heavy problems, and trigger less follow-up research overall.Main News Item
🛠️ Today’s sponsor: Nexa and Qualcomm launch the first On-Device AI Bounty:

Mobile Round. Create an Android AI app running locally on Qualcomm Hexagon NPU (NexaSDK).
Rewards include $6,500 cash, a $5,000 grand prize + Edge AI Impact Award, and Snapdragon devices for top 3. Winners also gain mentorship and Qualcomm spotlight access. Join it here.
👨🔧 A new paper shows “Why LLMs Aren’t Scientists Yet: Lessons from Four Autonomous Research Attempts”

An LLM is a text model that predicts the next words, so it struggles to stay consistent across a full research project.
To test this, the authors chained 6 role based LLM agents that hand off plans, code, and results through shared files.
They tried 4 complete Machine Learning paper runs, from idea picking to experiments to writing, with minimal human help.
3 runs broke, mostly because the system defaulted to familiar tools, changed the spec under pressure, forgot context, and overpraised bad outputs.
The paper argues that better AI scientist setups need gradual detail, strict verification at every step, explicit recovery paths, and obsessive logging.
🧠 xAI published the full codebase for the algorithm that ranks and selects posts in the “For You” feed.
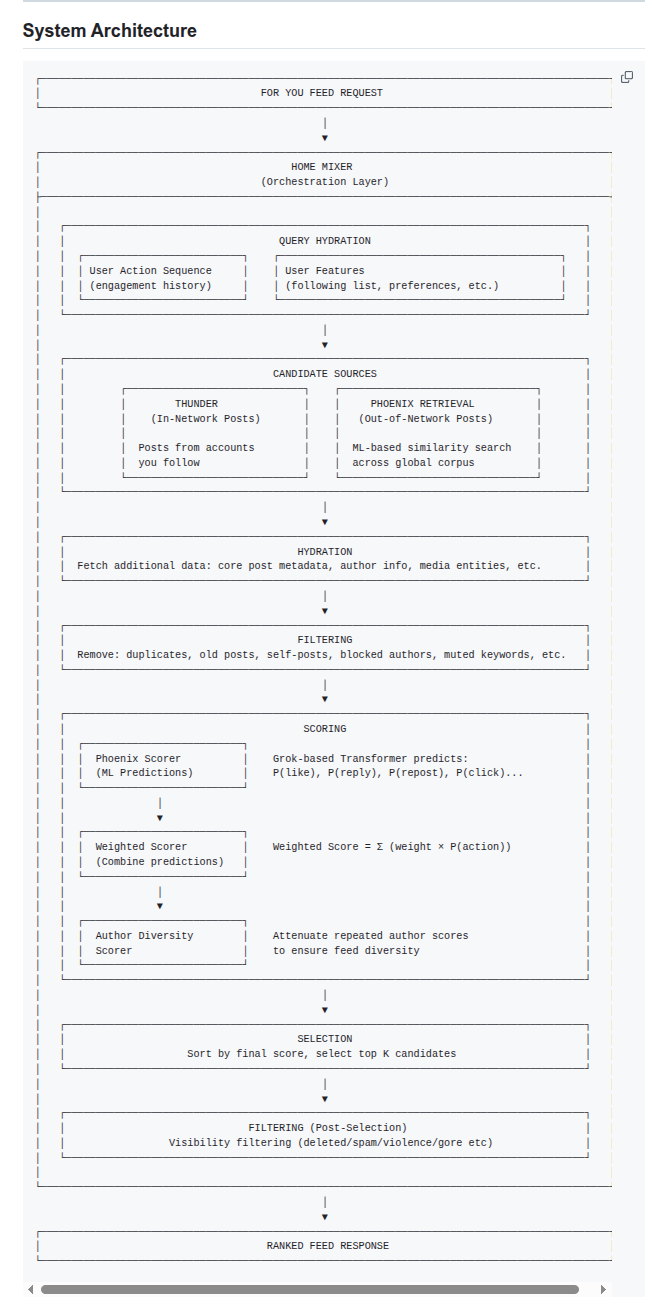
The pipeline ranks posts by predicting what a user will do next for each candidate post. It does this by turning feed ranking into probabilities for 14 user actions, then combining them into 1 score.
Older feed rankers often relied on brittle heuristics and feature engineering that needed constant tuning as the product changed. This system starts with a request, then a “Home Mixer” orchestration layer builds a query from the user’s action history plus user features like follows and preferences.
Pulls candidates from 2 places, Thunder for recent in-network posts from followed accounts, and Phoenix Retrieval for out-of-network posts found by embedding similarity search.
It then hydrates each candidate with extra metadata, filters out duplicates and blocked content, and sends the remaining posts to scoring.
A Grok-style transformer predicts probabilities of actions like like, reply, repost, and click, and a weighted sum turns those probabilities into a final rank score.
An author diversity step reduces repeated-author dominance, then the system selects the top K and applies post-selection visibility filtering for deleted or policy-violating posts.
It also makes it clearer where costs live, since retrieval, hydration, and transformer scoring each add latency and compute.
🧑🎓 xAI engineer Sulaiman Ghori said he’s leaving the company, just days after a viral interview discussing details about how the startup operates behind the scenes.
He officially announced his exit from xAI on X.
During that interview Sulaiman Ghori said xAI is almost building “human emulators” to automate digital work by mimicking human inputs (keyboard/mouse) and visual processing.
These agents will not need backend integration. They can just look at the screen and use the mouse/keyboard to get jobs done.
He also discussed about how the push at xAI is on another level. Elon Musk told the engineers, “You can get a Cybertruck tonight if you can get a training run on these GPUs within 24 hours.”
🗞️ Claude Code is going viral with developers, and that story is bleeding into software stocks.
It’s that point where engineers, executives, and investors start handing their tasks to Anthropic’s Claude AI—only to see it think and reason at a level that’s surprisingly advanced, even in a world already packed with strong AI tools.
All that hype has fueled a selloff in old-school software companies, as investors brace for what could be a new age of AI-built “selfware.”
A Morgan Stanley basket of software-as-a-service names is down 15% so far in 2026, and Intuit dropped 16% last week while Adobe and Salesforce fell more than 11%.
The worry is that recurring, per-seat SaaS pricing looks shakier if AI can build and run custom internal tools on demand.
Stories about Claude Code suggest some teams may need fewer engineers and fewer software seats to produce the same output, which implies slower seat growth and weaker net revenue retention.
Those stories also hint that some buyers might replace paid SaaS products with “good enough” custom tools built by an AI agent, which threatens pricing power and raises churn risk.
Even if only a small slice is true, investors often reprice the whole category because they cannot easily tell which vendors have the most exposure, so the risk premium rises and valuation multiples compress.
That’s a wrap for today, see you all tomorrow.