
🥉 Apple drops on-device LLMs with 3-line Swift access, no API costs, local inference
Apple goes full on-device LLM, Sam Altman signals AGI takeoff, while OpenAI, Nvidia, and Hugging Face push updates across evals, infra, assistants, and access limits.

Read time: 9 mint
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (11-Jun-2025):
🥉 Apple drops on-device LLMs with 3-line Swift access, no API costs, local inference
🔥 “We are past the event horizon; the takeoff has started. Humanity is close to building digital superintelligence”: Sam Altman writes long blog
📡Meta to acquire $15 billion stake in Scale AI and on its way to create a ‘Superintelligence’ Lab
🗞️ Byte-Size Briefs:
ARC-AGI confirms o3 price drop keeps same performance, 80% cheaper
OpenAI doubles o3 message limits for Plus—now 200/week
Hugging Face releases MCP Server to unify tools with assistants
Manus adds Veo 3 for cinematic AI video with speech, scenes
OpenAI upgrades Evals with tool use, structured output support
Nvidia partners with Mistral, Perplexity—18k GB chips for EU AI
🧑🎓 Video to Watch: Michael Truell, co-founder and CEO of Anysphere (Cursor), with Garry Tan (President & CEO Ycombinator): Long Context, Future of Coding
🥉 Apple drops on-device LLMs with 3-line Swift access, no API costs, local inference
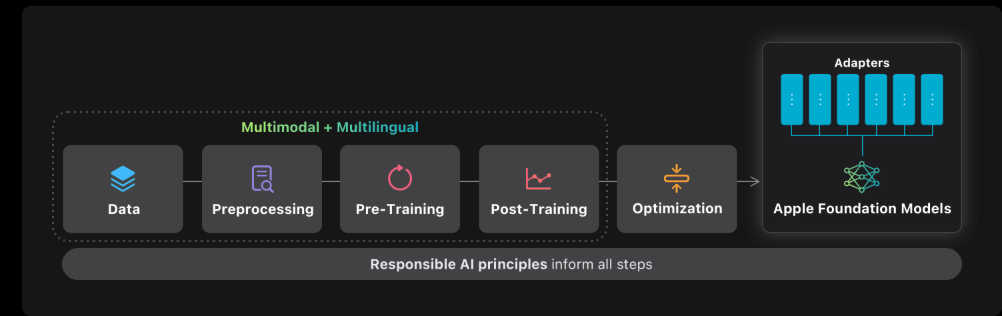
→ Apple introduced a new Foundation Models framework to let developers build apps using a 3B parameter on-device LLM, with local inference and no cloud API fees. This is part of the broader Apple Intelligence initiative.
→ The framework integrates tightly with Swift. Developers can generate structured output by annotating Swift structs with @Generable. It also supports tool calling and multi-turn memory, plus streamed partial outputs for faster UI feedback.
→ Apple’s on-device model is quantized to 2 bits per weight and optimized for Apple silicon, cutting KV cache memory by 37.5% using a dual-block design. The server model uses a PT-MoE architecture to reduce sync overhead and improve scalability.
→ Guided generation ensures outputs conform to developer-defined formats via Swift types. A system daemon handles constrained + speculative decoding at runtime, enabling real-time, format-safe model outputs.
→ Evaluation shows the on-device model beats Qwen-2.5-3B in 33.5% of cases and ties in 53.5%, while holding up against Qwen-3-4B and Gemma-3-4B in multiple languages. It also wins 50.7% of image tasks vs Qwen-2.5-VL-3B.
→ Developers can fine-tune with rank-32 adapters via a Python toolkit. No support for full fine-tuning or external model deployment.
→ Foundation Models framework is available only on devices with OS version 26+. Inference runs locally and is free to developers. Testing is live via Xcode Playgrounds.
→ Data was sourced from licensed, curated, and Applebot-crawled public web content, including over 10B filtered image-text pairs and 14T text tokens. No user data is used in training.
→ Apple added language grounding, image grounding, and math/code skills through multiple stages of pretraining and RLHF. Safety is enforced through localized evaluation, cultural risk mitigation, and developer-facing guidelines.
→ This strategy plays to Apple’s strengths: hardware optimization, privacy-first design, and a locked-in App Store ecosystem that still shapes what “mobile software” looks like. If someone builds the next breakout AI experience on iOS, Apple wins, whether it wrote the code or not. There’s no licensing, no throttling, and no user data leaving the device.
→ So the real winners in this case will be niche apps, side projects, and indie utilities that flood the store with personalized, privacy-first AI helpers. With zero cloud overhead and no per-query costs, even small indie teams can afford to get weird with it. We’ve seen this before. Apple didn’t make the most popular fitness app; it built the Apple Watch. It didn’t build the App Store’s most iconic games; it gave developers the tools to build them. The difference this time is that Apple needs developers to carry the load.
With no API fees or usage caps, Apple is effectively inviting devs to throw ideas at the wall and see what sticks, hoping that at least a few do.
🔥 “We are past the event horizon; the takeoff has started. Humanity is close to building digital superintelligence”: Sam Altman writes long blog

→ Sam Altman says we've passed the AI "event horizon"—with digital systems now smarter than humans in some domains and amplifying human output significantly. GPT-4 and GPT-4o are described as early but strong proof points.
→ He predicts AI agents that do real cognitive work are now arriving, and systems capable of generating novel scientific insights may emerge by 2026. Physical robots with useful real-world task ability could follow by 2027.
→ Altman frames recent progress as a soft singularity—not instantly world-transforming, but accelerating in compounding ways. Advanced AI is already doubling or tripling researchers' productivity, and recursive improvement in AI research is starting, even without full autonomy.
→ He sees self-reinforcing feedback loops: more economic value leads to more infrastructure investment, which enables more powerful models. He notes future robot-built datacenters could trigger exponential automation.
→ Altman projects the cost of intelligence will approach electricity costs, as AI inference becomes more efficient.
→ He emphasizes that alignment remains the hard part—citing social media recommendation algorithms as examples of misaligned systems optimizing short-term user behavior at the expense of long-term well-being.
We also get for the first time real data on ChatGpt’s resource use per query. And it’s barely anything.

📡Meta to acquire $15 billion stake in Scale AI and on its way to create a ‘Superintelligence’ Lab

Meta Is Creating a New A.I. Lab to Pursue ‘Superintelligence’
The new lab, set to include the Scale AI founder Alexandr Wang, is part of a reorganization of Meta’s artificial intelligence efforts under Mark Zuckerberg.
The deal isn't finalized yet but gives Meta a direct pipeline to high-quality labeled training data, critical for building large models.
Scale AI provides data curation and labeling infrastructure. Its clients include OpenAI, Cohere, Microsoft, and Meta itself. It earned $870 million in 2024 and is forecasting over $2 billion revenue in 2025.
Scale's CEO Alexandr Wang will join Meta to head a newly formed "superintelligence" lab. This signals a major shift in Meta’s AI leadership and organizational focus.
Scale AI was last valued at $13.8 billion and is backed by top-tier VCs like Accel, Index Ventures, Founders Fund, and Greenoaks. This exit is a strong win for early investors.
As per reports, Meta is also paying upto $100M+ per person to win the AGI talent war 🤯
Zuckerberg is directly recruiting top AI researchers, often meeting them privately at his homes in Palo Alto and Lake Tahoe. Offers reportedly range from $10 million to over $100 million per person.
Internally, Zuckerberg has reshuffled seating at Menlo Park HQ so the new team works close to him. The hands-on approach is part of his “founder mode” strategy.
🗞️ Byte-Size Briefs
After OpenAI reduced the price of o3 model by 80%, many people were concerned if the new o3 model from OpenAI is a quantized one or smaller-sized one. ARC-AGI just confirmed that, the 80% price drop of o3 did not change its performance. They retested the o3-2025-04-16 model on ARC-AGI, and the retest results were the same. So basically its the same model, same intelligence—now at a fraction of the cost.
OpenAI doubled the rate limits for o3 for Plus users. Currently its 100 total messages per week, so now it will become 200. However, some users pointed out if the o3 model’s cost is now just 1/5th of what it was, the weekly quota for ChatGPT should have been increased closer to 5x, not just 2x.
Hugging Face releases official Hugging Face MCP (Model Control Protocol) Server, enabling seamless integration between the Hub and any MCP-compatible AI assistant—including VSCode, Cursor, and Claude Desktop. This lets any MCP-compatible AI assistant directly use Hugging Face Spaces, Papers search, models, datasets, and even custom Gradio apps—bringing Hugging Face's ML tools into everyday coding workflows.
🎬 Manus adds Veo 3 support to generate richer, more cinematic AI videos with natural speech and longer scenes. Veo 3 brings sharper visuals and better narrative structure, letting users craft more lifelike stories directly in Manus with synchronized audio and extended shot control across membership tiers.
OpenAI upgrades Evals with full tool use and structured output support.
This lets developers evaluate LLMs using actual tool calls—checking both arguments and responses—including OpenAI-hosted tools, non-hosted APIs, and Multi-Call Protocol (MCP), enabling more realistic, workflow-level testing of model capabilities. OpenAI Evals is an open-source framework and registry that helps you systematically evaluate LLMs—like GPT‑4o on various benchmarks and custom tasks.
⚙️ Nvidia teams up with Mistral and Perplexity to expand Europe's AI infrastructure with local models and massive compute. Nvidia will power Mistral Compute with 18,000 Grace Blackwell chips, support reasoning model development in low-resource European languages, and deploy “AI factories” across 20+ countries—aiming to localize LLMs and reduce EU dependence on US infrastructure.
🧑🎓 Video to Watch: Michael Truell, co-founder and CEO of Anysphere (Cursor), with Garry Tan (President & CEO Ycombinator): Long Context, Future of Coding

Cursor went from from beta to $100M ARR in 20 months.
Key Themes discussed in this video:
Cursor's end-state is intent-based programming where the codebase itself becomes less visible and editable through new interfaces.
Their internal custom models now handle over 500 million inference calls per day.
Key bottlenecks to agents going superhuman: context window limits, incomplete continual learning, and weak multimodal grounding (e.g., aesthetics or design awareness).
AI coding agents hit a wall when codebases get massive. Even with 2M token context windows, a 10M line codebase needs 100M tokens. The real bottleneck isn't just ingesting code - it's getting models to actually pay attention to all that context effectively.
Cursor believes the long-term UX must evolve. Text prompts are too vague; users need precise, editable representations of software logic, possibly through a mix of high-level code and direct UI manipulation.
Ultimately, Cursor is betting that all coding flows through LLMs — and they want to own the new interface to that.
That’s a wrap for today, see you all tomorrow.