
🥉 Apple’s open sources FastVLM Models with WebGPU
Apple drops FastVLM with WebGPU, Meituan unveils Longcat Flash rivaling DeepSeek and Gemini, Epoch AI sizes GPT-5 leap, and new report questions global AI affordability.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (1-Sept-2025):
🥉 Apple’s releases FastVLM Models with WebGPU
🏆 Chinese Food Delivery Company Meituan Releases Longcat Flash Model Comparable To Deepseek V3 And Gemini Flash 2.5
🛠️ New report from Epoch AI found that while GPT-5 may feel like incremental update to the frontier, but its a major leap from GPT-4
📡 A new sensational report claims, “The world just doesn’t have the ability to pay for this much AI”
🥉 Apple’s releases FastVLM Models with WebGPU

🖼️ Apple releases FastVLM and MobileCLIP2 vision language models on Huggingface. Real-time video captioning demo (in-browser + WebGPU)
Key Takeawys
major latency cuts. Upto 85x faster Time to first token than LLaVA-OneVision-0.5B with a 3.4x smaller vision encoder, which also lowers memory and serving cost.
You can run it in-browser
Vision language models often stall because the vision encoder produces many image tokens, which forces heavy cross attention and delays the first word appearing.
FastViTHD is a hybrid vision encoder that compresses high resolution inputs into fewer tokens, so the language model can start decoding sooner.
This directly slashes Time to first token, which is the wait between sending an image and seeing the first generated word.
The larger FastVLM variants paired with Qwen2-7B beat Cambrian-1-8B while using a single image encoder and deliver 7.9x faster Time to first token, which puts them on a better speed to quality tradeoff.
A single encoder removes multi trunk overhead, simplifies batching, and reduces framework glue work that often becomes the hidden tax in production.
Producing fewer visual tokens also shrinks the key value cache, so every decoding step gets lighter and long answers speed up, not just the first word.
The reported accuracy versus latency plot implies a stronger Pareto frontier, meaning at the same accuracy it is much faster, or at the same latency it is more accurate.
Much better Pareto curve, meaning for the same accuracy it is faster, and for the same latency it is more accurate.

The plot compares accuracy on 5 vision language model tests against Time To First Token, which is how long the model waits before showing the first word. FastViTHD stays higher accuracy at much lower Time To First Token than the others, so it is both strong and quick.
At roughly 55% accuracy, FastViTHD is about 3.2x faster in Time To First Token than ConvNeXt-L. As image resolution grows from 256x256 to 1024x1024, FastViTHD keeps latency low, while ConvNeXt-L slows a lot.
Single point baselines like ViT-L/14, SigLIP-SO400M, and ConvNeXt-XXL sit with worse speed accuracy tradeoffs than FastViTHD.
Licensing terms on Apple's FastVLM-7B

You can only use the model for non-commercial scientific research and academic purposes.
You cannot use it for product development, commercial exploitation, or in any commercial product or service.
You may copy, modify, distribute, and create derivatives, but all derivatives must also be limited to research use.
Apple can revoke your license if you breach terms, and then you must delete all copies.
🏆 Chinese Food Delivery Company Meituan Releases Longcat Flash Model Comparable To Deepseek V3 And Gemini Flash 2.5
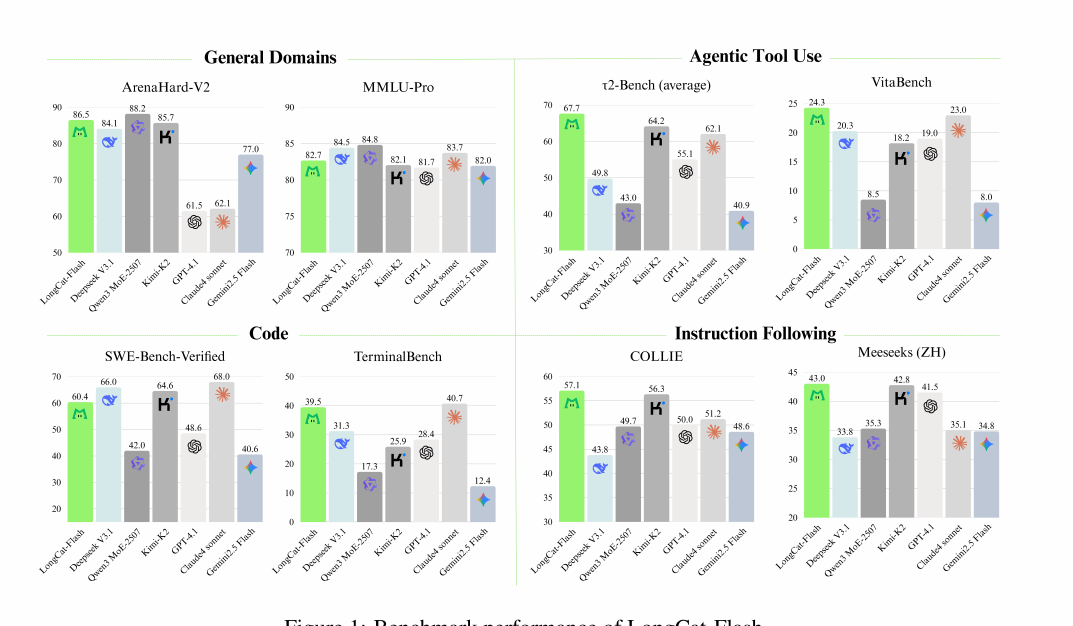
Chinese food delivery company Meituan has released the Longcat Flash model that compares to DeepSeek V3 and Gemini 2.5 Flash. The model is open-source, with the weights and the source code released under the MIT license.
LongCat-Flash-Chat arrived on Huggingface
560B Total Params | 18.6B-31.3B Dynamic Activation
Trained on 20T Tokens
Nice Performance
The technical report of is dense with lots of details.
New Architecture
Zero-computation experts let the router skip work for easy tokens and spend extra compute on hard ones.
Expert bias with a PID-style controller keeps the average number of active experts stable per token.
Load-balance loss spreads tokens across devices and treats all zero experts as one group for fairness.
Shortcut-connected MoE overlaps dense FFN compute with MoE communication, hiding comms inside real compute.
Single Batch Overlap inference pipeline overlaps NVLink and RDMA paths so TPOT nearly halves.
Variance alignment scales the two attention paths to equalize magnitudes, stabilizing training at large widths.
Fine-grained experts are variance-compensated with a scalar to restore proper initialization scale.
Hyperparameter transfer scales proxy model settings to big width, avoiding expensive full sweeps.
Model growth initialization stacks half-depth checkpoints into full-depth for smoother convergence. They first train a 2x smaller model and then "when it's trained enough" (a bit unclear here how many Bilions tokens) they init the final model by just stacking the layers of the smaller model.
Hidden z-loss suppresses huge activations in BF16, preventing loss spikes.
Tiny epsilon in Adam (1e-16) keeps optimizer adaptive even at huge batch sizes.
Speculative decoding with a single dense MTP head reaches \~90% acceptance at lower parameter cost.
Multi-head Latent Attention compresses KV strongly, cutting KV I/O and storage.
Custom kernels and quantization (block-wise and FP8) improve inference efficiency without quality loss.
But what makes this model so interesting is that it doesn’t come from an AI-first company. Meituan was founded in 2010 as a group discount website, and is now best known for food deliveries. Meituan has a super-app that offers a wide range of local consumer services, including food delivery and related on-demand services, in-store dining, hotel and travel bookings, and various new initiatives such as community e-commerce, grocery delivery, ride-sharing, bike-sharing, and micro-lending. It is now one of China’s largest platforms with over 770 million annual transacting users and millions of merchants, and aims to get people to “eat better and live better”.
And even a food delivery company creating a serious model that comes close to the state-of-the-art shows the depth of China’s AI ecosystem.
🛠️ New report from Epoch AI found that while GPT-5 may feel like incremental update to the frontier, but its a major leap from GPT-4

While Initial reactions to GPT-5 were mixed: to many, it did not seem as dramatic an advance as GPT-4. But when analyzed with the proper timeframe, both GPT-4 and GPT-5 were big generational moves, a major leap from previous best.
GPT-4 was a clean step up over GPT-3 on mainstream tests, and GPT-5 keeps that pattern on tougher targets that matter now.
But the reception felt mixed, because, between GPT-4 and GPT-5 there were many intermediate releases and feature upgrades, so part of the gain showed up gradually over 2024 to 2025, which softened the feeling of one dramatic jump even though the end state is clearly higher.
But this was not the case with GPT-4, as there were very few significant releases between GPT-3 and GPT-4, meaning users felt more progress suddenly all at once, when GPT-4 was released.
🛠️ The newly released Grok Code Fast 1 is now #1 on the OpenRouter leaderboard, beating Claude Sonnet.

Grok Code Fast 1 surpasses Claude Sonnet, tops OpenRouter leaderboard.
Means, Grok Code Fast 1 is generating the most tokens among models used through OpenRouter in that window.
Grok Code Fast 1 is positioned as a fast, low-cost agentic coding model, which aligns with high-throughput coding tools. OpenRouter lists it with aggressive pricing and large context, which encourages heavy token generation in iterative coding loops. With reasoning traces visible in the response, developers can steer Grok Code for high-quality work flows."
OpenRouter is a unified API that sits between apps and many LLM providers. Developers plug into 1 endpoint and can call hundreds of models. Because all traffic passes through the gateway, OpenRouter can tally token counts per model. Its public “Leaderboard” shows token usage across models with time windows like “Top today” and “Top this week.”
Ranking #1 here means Grok Code is generating the most tokens among models used through OpenRouter in that window. That indicates strong real-world pull from apps that opted to send their requests through OpenRouter, especially coding agents and IDE copilots, which currently dominate the “Top Apps” section. So it is a meaningful adoption milestone inside the OpenRouter ecosystem.
Why this happened now likely comes down to fit and economics. Grok Code Fast 1 is positioned as a fast, low-cost agentic coding model, which aligns with high-throughput coding tools. OpenRouter lists it with aggressive pricing and large context, which encourages heavy token generation in iterative coding loops. xAI’s launch notes and the model page reinforce that “speedy and economical” positioning for agentic coding.
There may also be go-to-market effects. Reuters reported xAI offered Grok Code to selected launch partners for free, which can spike token counts when large apps trial or default to a new model. OpenRouter itself also does provider routing and load balancing, so availability and price can shift traffic quickly toward a model. These factors amplify usage without necessarily reflecting raw model quality.
What the leaderboard measures is tokens, not accuracy, safety, or revenue. Tokens are simply the units of text processed in and out of a model, which OpenRouter records as request metadata. Heavy tokens can come from low prices, promo credits, or a few large customers, and reasoning-trace tokens also count toward totals. So treat #1 as “most used on this network right now,” not “best model overall.”
📡 A new sensational report claims, “The world just doesn’t have the ability to pay for this much AI”

The report says, AI data centers are absorbing huge capital, and a new analysis says the math fails, with $40B yearly depreciation on 2025 builds versus $15-20B revenue.
The core pieces age on different clocks, chips churn in 2-4 years, networking around 10 years, buildings far longer, so depreciation snowballs.
On those lifetimes, 2025 sites show $40B annual write-downs against $15-20B revenue before power and staff, which already implies negative cash. To earn a normal return at this scale, United States data centers would need about $480B revenue in 2025, far above current run rates.
Spending is set at $375B in 2025 and $500B in 2026, so the revenue gap widens as the base grows. For scale, Netflix makes $39B from 300M users, so at similar pricing AI software would need 3.69B paying customers.
The point is capital intensity plus short hardware life compress margins unless pricing, load factors, or efficiency rise by about 10x.
Chip and construction suppliers win near term, but operators eat depreciation and power risk, and customers see higher prices if providers chase break even.
"new data centers have a very tiny runway in which to achieve profits that currently remain way out of reach"

My own Counterpoints
The GPU depreciation numbers assumed in the above report, seems to be exaggerated.
Here's some numbers on the timeline that large clouds now take to depreciate servers and network equipment from their annual financial reports.
Alphabet says servers and network kit are “generally” 6-year life.
Microsoft 6 years, Meta pushed most servers and network to 5.5 years starting 2025.
AWS even shortened some older gear back to 5 years for 2025, which shows they actively tune lives by cohort.
Also, there is a real secondary market for the usedup datacenter GPUs, i.e. after after book depreciation falls to near zero. Refurbishers actively buy and sell A100s, and public listings show live price discovery.
e.g. recent e-commerce asks for A100 40GB are roughly $2,400–$4,400. And A100 80GB refurb or used listings cluster roughly $9,000–$13,000, which is a substantial fraction of original cost depending on the SKU and when you bought it.
That is not a guarantee of liquidity at scale, but it proves residual value is not zero.
🗞️ Byte-Size Briefs
🇨🇳 China’s Huawei launced an SSD (solid state drive) with a MASSIVE storage capacity of 245 terabytes per drive.
This is the largest single-disk capacity available in the AI industry, to speed AI training and inference by fixing storage bottlenecks.
GPUs hit a capacity wall and a memory wall as data explodes, so these new SSDs (EX 560 and SP 560) aim to feed batches and checkpoints faster to cut idle time.
With maximum capacity of 245 terabytes, these can improve data pre-processing efficiency by 6.6 times and reduce space usage by 85.2% when used in AI training clusters.
Although hard-disk drives are still the dominant form of server storage, solid-state drives are gaining ground fast thanks to their energy savings, high efficiency, and low operating costs, and AI server SSD share could reach 20% by 2028.
Enterprise SSD supply is still led by Samsung, SK Hynix, Micron, SanDisk, and Kioxia.
AI scale needs are brutal, e.g. a 671-billion-parameter LLM alone consumes 3.5 petabytes of training data, and the global internet’s multimodal data has already soared to 154 zettabytes, which is far too much for standard storage technology.
So what’s the update with Meta Superintelligence Labs and all these hires?
Meta's near term story is to centralize power under Wang, shelve the underperforming Behemoth model, and direct compute into a small scaling team while product and infrastructure reorganize around it.at this scale is GPUs and data pipelines, so whoever controls those knobs sets research speed and what actually ships.
Churn is loud but narrower than rumor, with at least 2 hires boomeranging back to OpenAI and a few quick exits.
The freeze is presented as budgeting for 2026 with case by case exceptions, so the pace of net hiring slows while the compute budget gets aimed.
That’s a wrap for today, see you all tomorrow.