Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance
LLM ensembles effectively clean training data, boosting model performance by 4%


LLM ensembles effectively clean training data, boosting model performance by 4%
Your AI model might be better than you think - blame the wrong test answers - as per this Paper.
🎯 Original Problem:
NLP benchmarks rely heavily on labeled datasets, but obtaining high-quality labels is challenging. Expert annotations are expensive and don't scale, while crowd-sourcing is inconsistent. This leads to mislabeled data in both training and test sets, affecting model performance and evaluation accuracy.
🔧 Solution in this Paper:
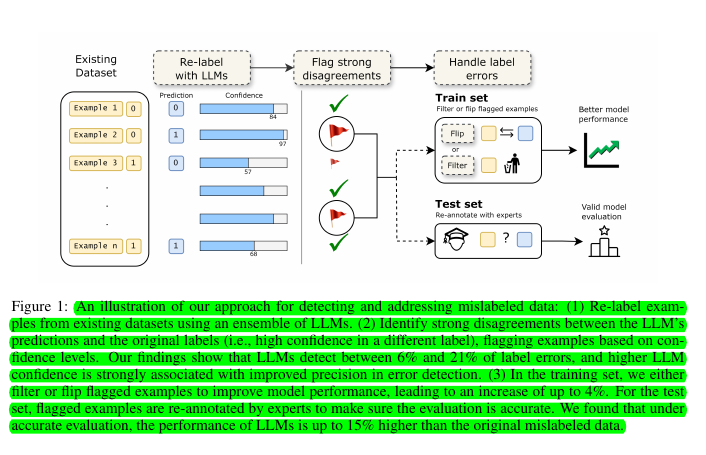
• Used an ensemble of LLMs to detect potentially mislabeled examples by analyzing their confidence scores
• When LLM confidence exceeds 95%, over 2/3 of flagged labels are confirmed errors
• Proposed two methods to handle mislabeled training data:
Filtering out examples flagged by LLMs
Flipping labels according to LLM predictions
• For test sets, flagged examples undergo expert verification
💡 Key Insights:
• Current datasets contain 6-21% label errors
• LLMs are effective error detectors when used as high-confidence ensembles
• Label errors significantly impact both training and evaluation
• LLM-based annotation offers better quality-cost-scale balance than crowdsourcing
• Most label changes (69.3%) were from "consistent" to "inconsistent" during expert review
📊 Results:
• Improved model performance up to 4% by handling mislabeled training data
• LLM performance is up to 15% higher when evaluated on corrected test sets
• LLMs show high inter-annotator agreement (Fleiss's κ = 0.706-0.750)
• Cost-effective: LLM annotation is 100-1000x cheaper than human annotation
💡 The paper proposes two main approaches, that can mitigate the impact of mislabeled data
Filtering out examples flagged by LLMs as potentially mislabeled
Flipping labels of flagged examples according to LLM predictions
Both methods improve model performance by up to 4% in training.