Attention Heads of Large Language Models: A Survey
The hidden architects: How attention heads shape LLM intelligence


The hidden architects: How attention heads shape LLM intelligence
Large Language Models (LLMs) excel in various tasks but remain largely black-box systems. Their development relies heavily on data-driven approaches, limiting performance enhancement through changes in internal architecture and reasoning pathways.
This Paper 💡:
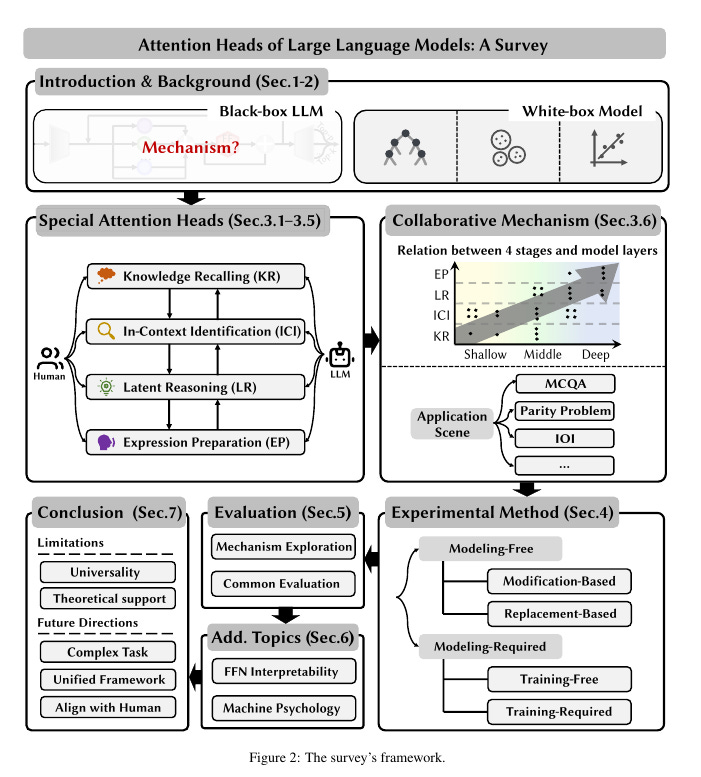
• Proposes a four-stage framework for LLM reasoning: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation
• Identifies and categorizes functions of specific attention heads within this framework
• Summarizes experimental methodologies for discovering special heads: Modeling-Free and Modeling-Required methods
• Outlines relevant evaluation methods and benchmarks
Concepts discussed in this Paper 🧠:
• Systematically reviews existing research to map attention head functions to human-like reasoning stages
• Categorizes attention heads based on their roles in each stage of the reasoning process:
Knowledge Recalling: Associative Memories Head, Memory Head
In-Context Identification: Previous Head, Positional Head, Syntactic Head
Latent Reasoning: Induction Head, Truthfulness Head, Iteration Head
Expression Preparation: Mixed Head, Amplification Head, Coherence Head
• Provides comprehensive overview of methods for exploring and validating attention head functions:
Modeling-Free: Activation Patching, Ablation Study
Modeling-Required: Probing, Simplified Model Training
• Discusses collaborative mechanisms between different types of attention heads
This paper primarily targets the attention heads within current mainstream LLM architectures, specifically those with a decoder-only structure.