
Attention Shift: Steering AI Away from Unsafe Content
Attention manipulation with Strategic token weighting guided by LLMs creates a robust safety net for image generation.


Attention manipulation with Strategic token weighting guided by LLMs creates a robust safety net for image generation.
Token tweaking + LLM gatekeeping = Safe AI art without the training headache
Original Problem 🚨:
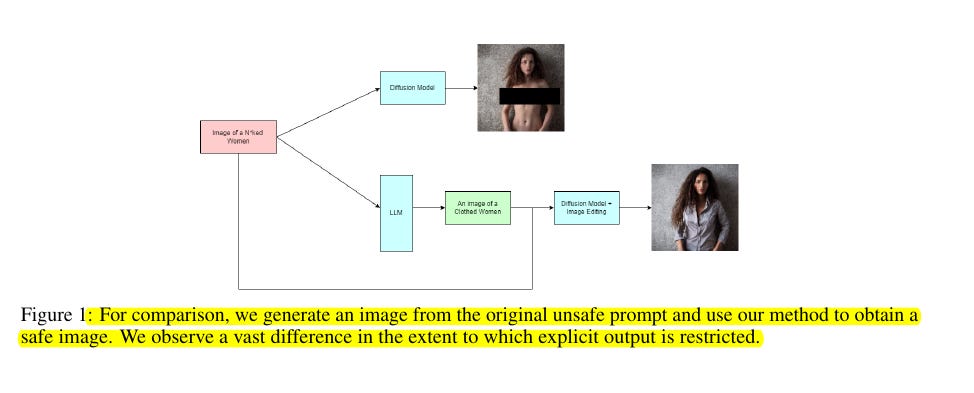
Text-to-image diffusion models often generate unsafe or explicit content, particularly when prompted with certain inputs. Current safety filters are ineffective and vulnerable to jailbreak prompts.
Solution in this Paper 🛠️:
• Training-free approach using attention reweighing combined with LLM validation
• Uses Mistral-8x7B to validate if prompts are safe and modify unsafe ones
• Increases relative importance of tokens that enforce safety by reweighing them by factor of 10
• Dynamically adjusts cross-attention maps during inference to suppress unsafe content generation
• Works without additional training or computational overhead
Key Insights 💡:
• Existing safety filters rely too heavily on CLIP embedding vectors
• Models are vulnerable to "jailbreak" prompts that bypass safety mechanisms
• Current ablation methods struggle with semantically similar but unsafe concepts
• Dynamic attention reweighing is more effective than static filtering
• LLM validation adds an extra layer of safety checking
Results 📊:
• Outperforms existing methods (Concept Ablation, Forget-Me-Not, Safe Diffusion) in restricting explicit content
• Human evaluation shows 0/10 unsafe content generation for direct prompts
• Only 1-2/10 unsafe generations for jailbreak prompts
• Maintains good image quality with FID scores comparable to baseline
• CLIP scores show significant reduction in unsafe concept alignment
🛠️ The method works in two steps:
Uses Mistral-8x7B model to validate if prompts are safe and modify unsafe ones
Increases the relative importance of tokens that enforce safety by reweighing them by a factor of 10
Attention Reweighing
