BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
BABILong shows popular LLMs only use 10-20% of their advertised context window effectively


BABILong shows popular LLMs only use 10-20% of their advertised context window effectively
The paper also shows, recurrent models process 11M tokens while attention-based LLMs struggle beyond 16K
Original Problem 🎯:
Current benchmarks only test LLMs up to 40,000 tokens while models can handle hundreds of thousands of tokens. Existing "needle-in-haystack" tests are too simplistic to effectively evaluate long-context processing capabilities.
Solution in this Paper 🔍:
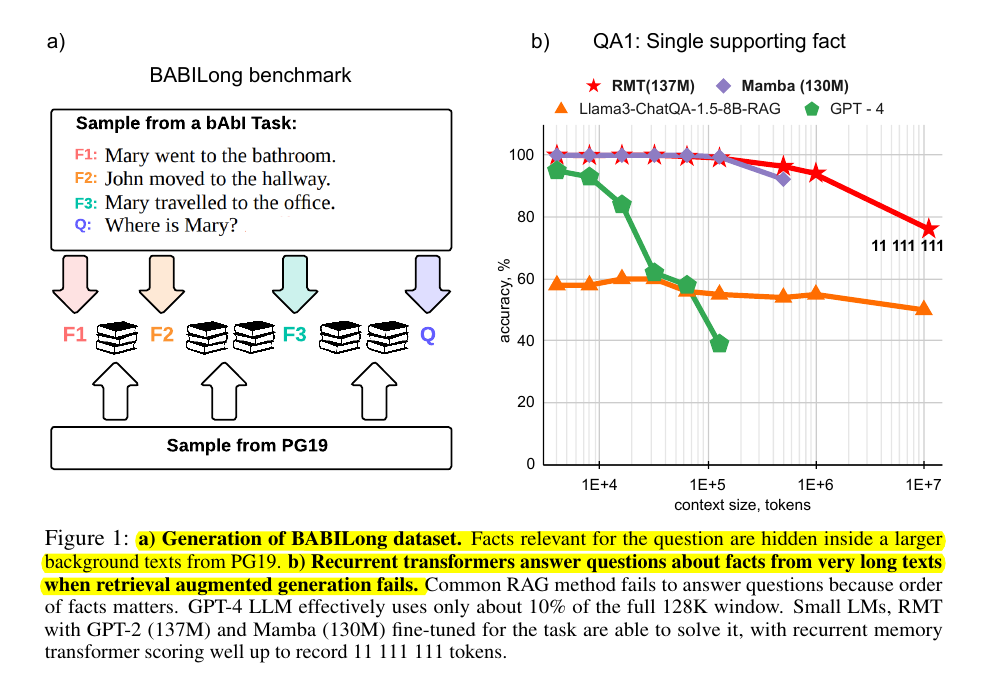
• Introduces BABILong benchmark with 20 reasoning tasks testing fact-chaining, induction, deduction, counting
• Hides relevant facts inside background text from PG19 books
• Scales tasks to any desired length to evaluate new models
• Provides splits up to 1 million tokens
• Tests capabilities like multi-hop reasoning and temporal understanding
• Open-source implementation available at github.com/booydar/babilong
Key Insights 💡:
• Popular LLMs effectively use only 10-20% of their claimed context window
• Performance drops sharply with increased reasoning complexity
• Retrieval-Augmented Generation achieves only 60% accuracy on single-fact questions
• Small fine-tuned models (RMT 137M, Mamba 130M) outperform larger models
• Recurrent approaches handle extremely long sequences better than attention-based models
Results 📊:
• RMT processes sequences up to 11 million tokens effectively
• GPT-4 shows 85% accuracy only up to 16K tokens
• Most models achieve <30% accuracy beyond 64K tokens
• Fine-tuned Mamba achieves best overall results but limited to 128K tokens
• RAG methods fail on multi-hop reasoning tasks
🌟 BABILong contains 20 reasoning tasks testing capabilities like:
Fact chaining
Simple induction
Deduction
Counting
Handling lists/sets