Baichuan-Omni Technical Report
7B parameters of pure multimodal magic: Baichuan-Omni handles text, visuals, and sound together

7B parameters of pure multimodal magic: Baichuan-Omni handles text, visuals, and sound together
Original Problem 🔍:
Lack of open-source multimodal LLMs capable of processing image, video, audio, and text concurrently while delivering advanced interactive experiences.
Solution in this Paper 🛠️:
• Baichuan-Omni: First open-source 7B Multimodal LLM
• Architecture: Image, Video, and Audio branches integrated with LLM
• Training schema: Multimodal alignment followed by multitask fine-tuning
• Data: High-quality omni-modal dataset for training
• Streaming input support for real-time audio and video processing
Key Insights from this Paper 💡:
• Effective multimodal training schema for 7B model
• Importance of high-quality, diverse omni-modal data
• Streaming input processing enhances real-time interactions
• Conv-GMLP audio projector improves performance robustness
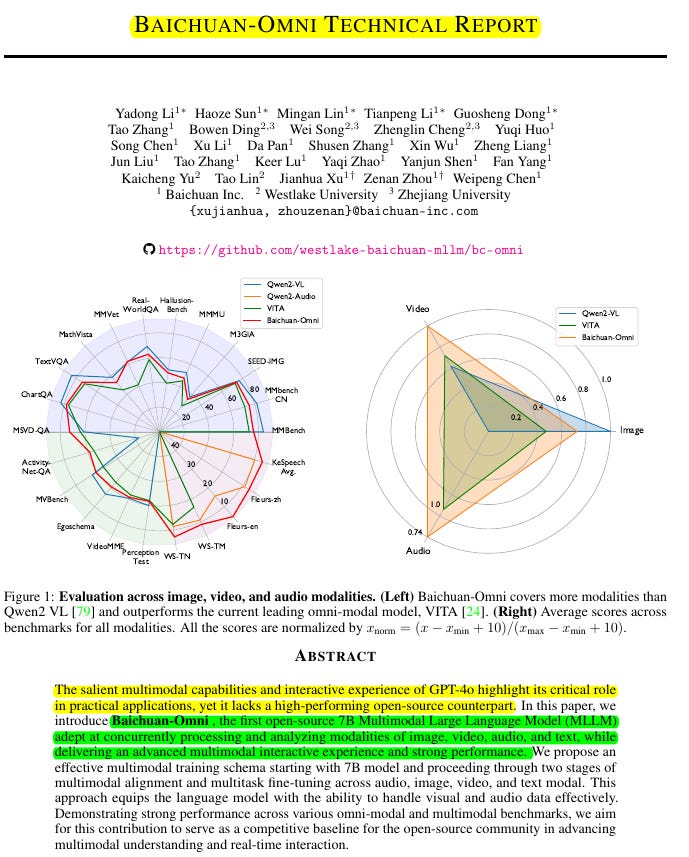
Results 📊:
• Outperforms open-source LLMs in comprehensive benchmarks (MMLU, CMMLU, AGIEval, C-Eval)
• Strong performance in image tasks (MMBench, SEED-IMG, MME)
• Competitive in video understanding (MVBench, VideoMME, ActivityNet-QA)
• Superior audio transcription (WER 6.9% on WenetSpeech test_net)
• Excels in Chinese ASR and dialect recognition
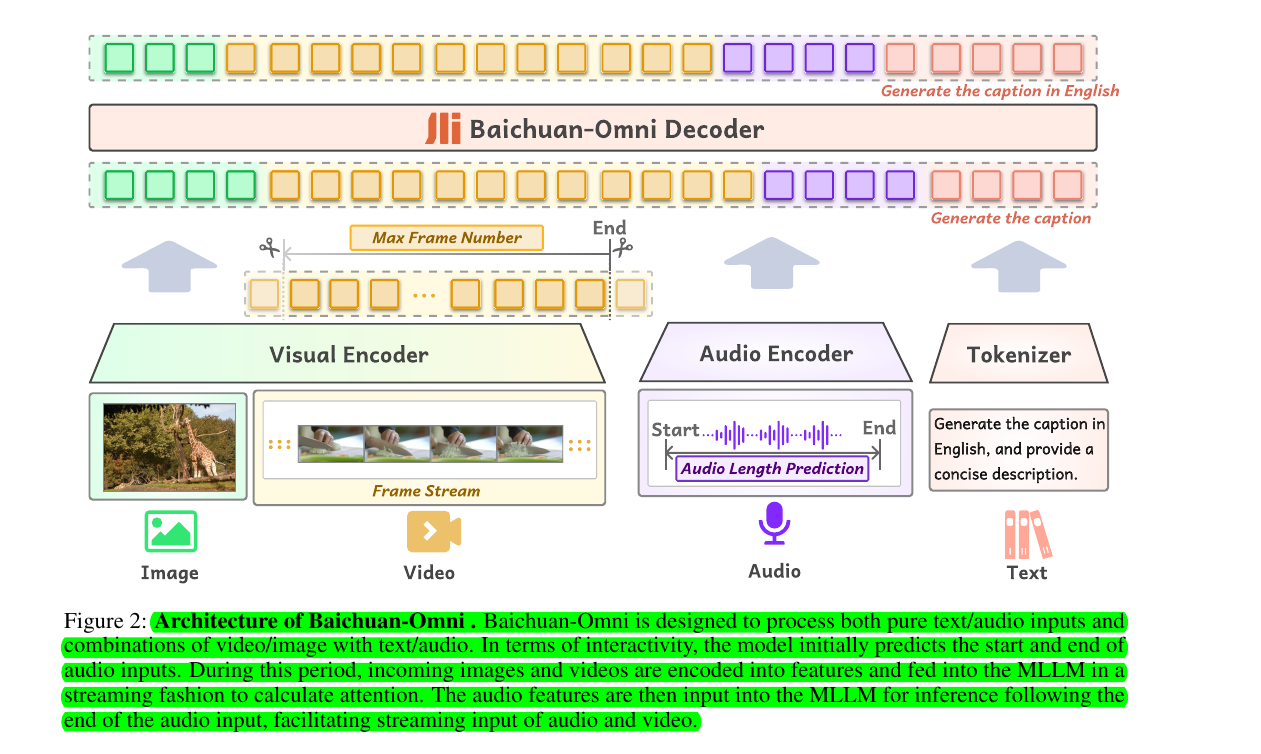
🔍 The architecture of Baichuan-Omni includes:
Image-Language Branch: Uses Siglip-384px as the visual encoder and a Mean Pool projector.
Video-Language Branch: Builds on the visual capabilities from the Image-Language Branch and uses a video projector.
Audio-Language Branch: Incorporates an audio encoder from the Whisper-large-v3 model and a newly introduced audio projector with Conv-GMLP.
Multimodal Alignment: Integrates all modalities for comprehensive understanding.