BenTo: Benchmark Task Reduction with In-Context Transferability
BENTO, proposed in this paper, slashes LLM testing costs by finding the essential 5% of benchmark tasks


BENTO, proposed in this paper, slashes LLM testing costs by finding the essential 5% of benchmark tasks
Smart task selection lets you evaluate LLMs using 95% fewer benchmark tests
Original Problem 🎯:
Evaluating LLMs requires testing on large benchmark datasets, often with 50+ diverse tasks. This process is computationally expensive and time-consuming, yet there's no clear way to reduce tasks while maintaining evaluation quality.
Solution in this Paper 🛠️:
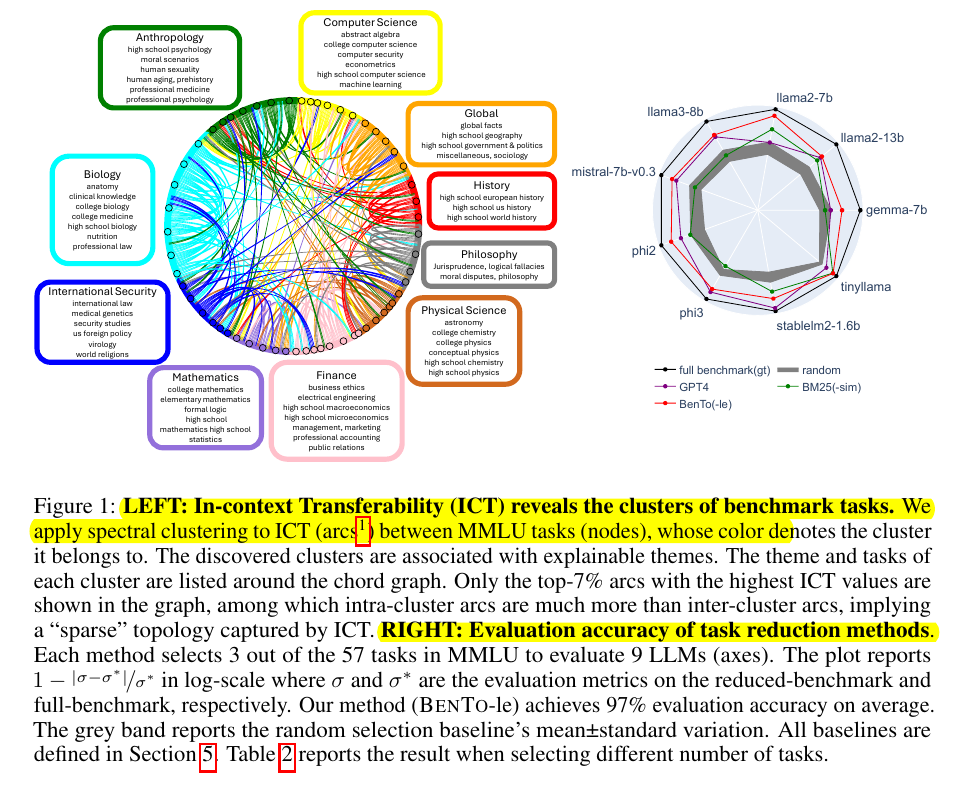
→ BENTO measures task transferability using in-context learning - using examples from Task A to solve Task B
→ Creates a transferability matrix showing how knowledge transfers between task pairs
→ Applies spectral clustering to group related tasks based on transferability
→ Uses facility location optimization to select the most representative tasks
→ Employs Laplacian Eigenmaps to enhance similarity measurements between tasks
Key Insights 💡:
→ Tasks naturally cluster into themed groups (like History, Science) with higher intra-cluster transferability
→ A small subset of tasks can effectively represent the full benchmark
→ In-context learning provides an efficient, training-free way to measure task relationships
→ Task selection works better with processed similarities than raw transferability scores
Results 📊:
→ Reduces MMLU benchmark to 5% of tasks while maintaining 97% evaluation accuracy
→ Outperforms GPT4 and BM25 baselines in task selection
→ Works across multiple benchmarks: MMLU, FLAN, AGIEval, and Big-Bench Hard
→ Achieves <4% error rate when evaluating 9 different LLMs
🎯 BENTO's benchmark reduction method
BENTO treats task selection as a facility location problem - picking tasks that maximize similarity to all other tasks. It uses either direct similarity from transferability or a processed version via Laplacian Eigenmaps embedding.