Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
RAG gets supercharged when it can see and read industrial manuals together


RAG gets supercharged when it can see and read industrial manuals together
🎯 Original Problem:
LLMs lack domain-specific knowledge and often hallucinate. While Retrieval Augmented Generation (RAG) helps, industrial documents combine complex technical text with visuals like diagrams and schematics, making it challenging for AI to provide accurate insights.
🔧 Solution in this Paper:
→ Integrated multimodal models into RAG systems specifically for industrial applications
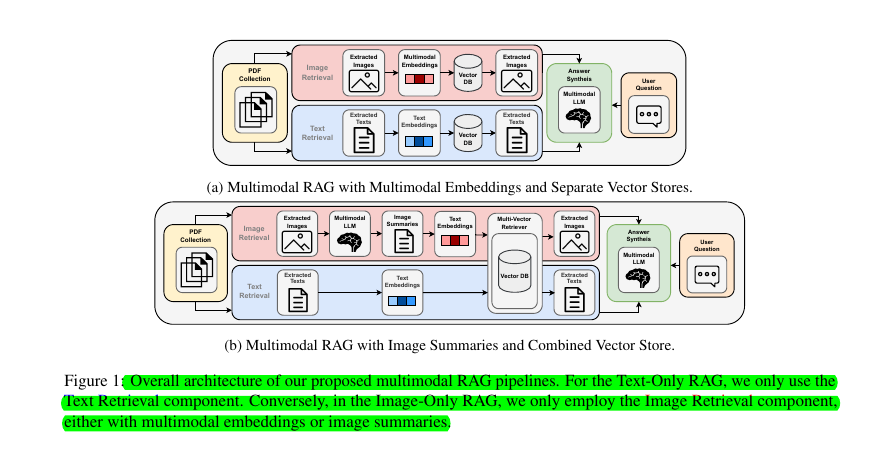
→ Used two distinct approaches for image processing:
Multimodal embeddings using CLIP to jointly embed images and questions
Generation of textual summaries from images using multimodal LLMs
→ Tested with GPT4-Vision and LLaVA for answer synthesis
→ Created custom dataset: 20 PDF documents, 8540 text chunks, 8377 images, 100 manually annotated QA pairs
💡 Key Insights:
→ Multimodal RAG outperforms single-modality RAG when configured optimally
→ Image retrieval is more challenging than text retrieval
→ Using textual summaries from images shows more promise than multimodal embeddings
→ Multiple images in prompts improve performance across all metrics except Image Faithfulness
📊 Results:
→ Answer Correctness: Multimodal RAG (83%) vs Text-only RAG (59%)
→ Image Context Relevancy: 72% with multiple images vs 28% with single image
→ Text Faithfulness: 98% with LLaVA, 76% with GPT-4V
🔍 The paper conducted experiments using two distinct approaches for image processing and retrieval:
→ Multimodal embeddings using CLIP to jointly embed both images and questions
→ Generation of textual summaries from images using multimodal LLMs
They tested these approaches with two Large Language Models - GPT4-Vision and LLaVA - for answer synthesis.