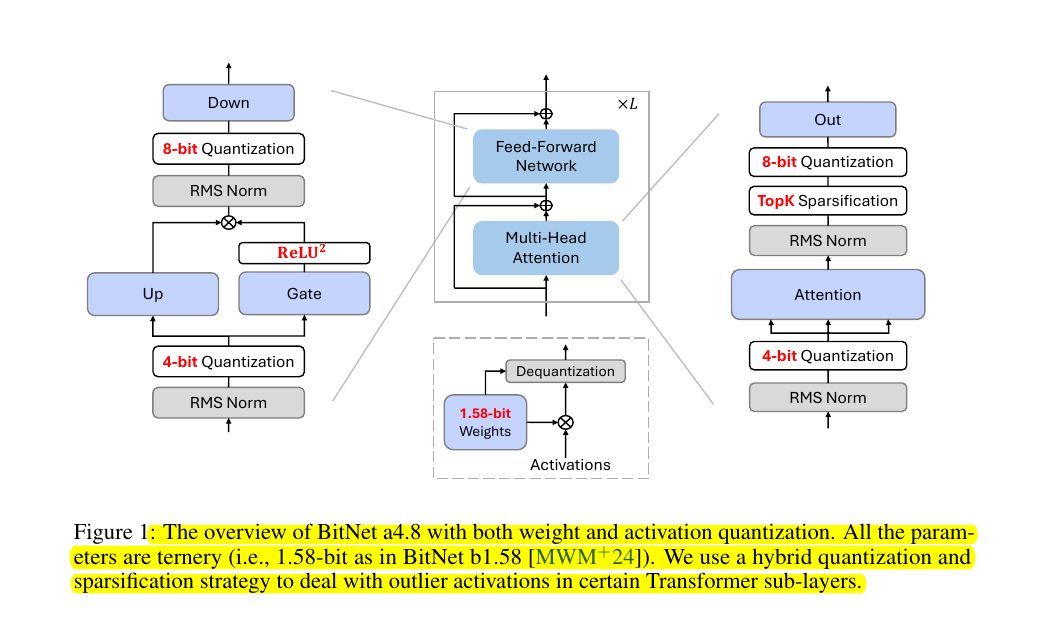
BitNet a4.8: 4-bit Activations for 1-bit LLMs
BitNet a4.8 shrinks LLM activation memory by 4x while keeping 1-bit weights intact.


BitNet a4.8 shrinks LLM activation memory by 4x while keeping 1-bit weights intact.
Achieves performance comparable to BitNet b1.58 with equivalent training costs, while being faster in inference with enabling 4-bit (INT4/FP4) kernels. Additionally, BitNet a4.8 activates only 55% of parameters and supports 3-bit KV cache.
Original Problem 🤔:
Current 1-bit LLMs face computational bottlenecks due to high activation costs, despite having compressed weights. The challenge lies in reducing activation bits while maintaining model performance.
Solution in this Paper 🛠️:
→ Introduces BitNet a4.8, enabling 4-bit activations for 1-bit LLMs using hybrid quantization and sparsification
→ Uses 4-bit quantization for attention and Feed Forward Network inputs that follow Gaussian distributions
→ Applies sparsification with 8-bit integers for intermediate states having sharp distributions with outliers
→ Implements a two-stage training: first with 8-bit activations for 95B tokens, then hybrid strategy for 5B tokens
Key Insights 🔍:
→ Different layers show distinct activation patterns - some Gaussian-like, others sharp with outliers
→ Squared ReLU with GLU achieves 80% sparsity in down-projection inputs
→ Model supports 3-bit KV cache without performance loss
→ Achieves 55% parameter sparsity while maintaining accuracy
Results 📊:
→ Matches BitNet b1.58 performance with same training cost
→ Achieves 44.5% sparsity for 7B model
→ Maintains performance even with 2T training tokens
→ Shows negligible accuracy loss with 4-bit KV or QKV heads
Core Architecture 🏗️
→ The model uses a hybrid approach combining different quantization levels and sparsification strategies
→ The main flow splits into three key processing paths:
Left path: Down-projection with 8-bit quantization and ReLU^2 gating
Middle path: Standard transformer blocks with Feed-Forward and Multi-Head Attention
Right path: Output processing with 8-bit quantization and TopK sparsification
Key Components 🔧
→ Input Processing: Uses 4-bit quantization for attention and Feed-Forward Network inputs
→ Weight Handling: All parameters are ternary (1.58-bit) following BitNet b1.58 design
→ Activation Flow: Employs RMS normalization at multiple stages to stabilize activations
→ Gating Mechanism: Uses ReLU^2 with GLU (Gated Linear Unit) for enhanced sparsity
Quantization Strategy 🎯
→ 8-bit quantization for down-projection and output paths
→ 4-bit quantization for core attention mechanisms
→ TopK sparsification for selective activation retention
→ 1.58-bit weights throughout the network
This hybrid architecture effectively balances computational efficiency with model performance, using different precision levels where they matter most.