
Boosting Healthcare LLMs Through Retrieved Context
Open-source and smaller LLMs match private and big healthcare models by using smart context retrieval systems.


Open-source and smaller LLMs match private and big healthcare models by using smart context retrieval systems.
Original Problem 🔍:
LLMs lack factual accuracy in healthcare, limiting their practical use. Open-source models lag behind private solutions in medical question-answering tasks.
Solution in this Paper 🧠:
• Optimized context retrieval system for LLMs in healthcare
• Components: choice shuffling, ensemble refinement, CoT-augmented databases
• OpenMedPrompt: Framework for open-ended medical question answering
• Two strategies: Ensemble Refining (OM-ER) and Self-Reflection (OM-SR)
Key Insights from this Paper 💡:
• Context retrieval significantly boosts LLM performance in healthcare tasks
• Open-source LLMs with optimized retrieval can match larger private models
• OM-SR outperforms OM-ER for open-ended medical question answering
• Smaller models benefit most from context retrieval enhancements
Results 📊:
• Llama-3.1-70B with context retrieval: 84.60% accuracy on MedQA (vs. 90.2% for GPT-4)
• OpenMedPrompt improves open-ended answer generation by 7.54% (53.34% to 60.88%)
• OM-SR with CoT database achieves 60.88% accuracy after 15 iterations
• Carbon footprint: 197.31 kg CO2 for all experiments
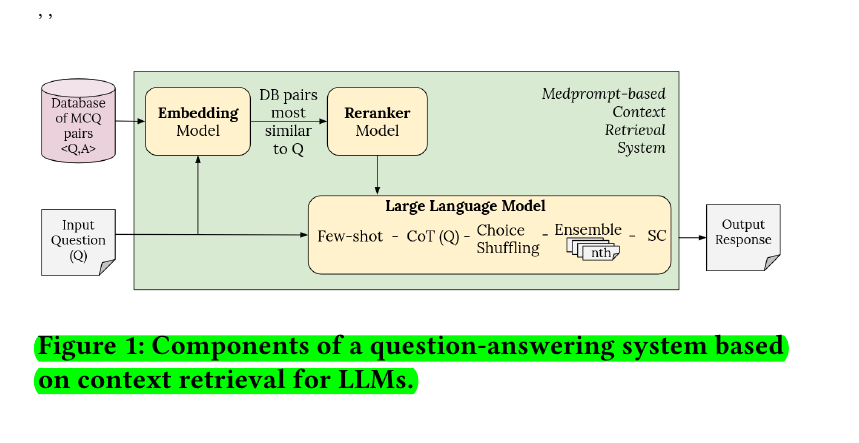
🧠 The key components in the context retrieval system
Choice shuffling: Randomly shuffling the order of answer choices to mitigate position bias.
Number of ensembles: Generating multiple independent responses and aggregating them for the final answer.
Database: Using validation sets or augmented training sets as external knowledge sources.
Embedding model: Transforming questions and database entries into numerical vector representations for similarity comparisons.
Reranking model: Refining initial retrieval results by re-ranking candidate QA pairs based on relevance.
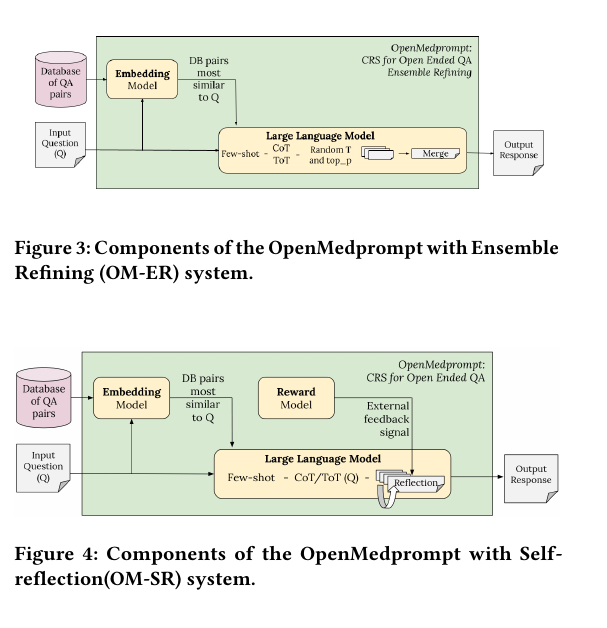
🔓 The proposed solution for generating more reliable open-ended answers
To address the limitations of multiple-choice question answering and move closer to practical applications, the researchers proposed OpenMedPrompt. This pipeline improves the generation of more reliable open-ended answers through two strategies:
OpenMedprompt with Ensemble Refining (OM-ER): Generates multiple initial answers and synthesizes them into a refined response.
OpenMedprompt with Self-reflection (OM-SR): Employs a feedback loop to iteratively improve the generated answer, incorporating attribute scores from a reward model.
Based on the research paper, here are some essential questions that capture the main proposals and core meaning:
🔬 The main objective and approach of this research
The main objective of this research is to explore the boundaries of context retrieval methods within the healthcare domain, optimizing their components and benchmarking their performance against open and closed alternatives. The approach involves enhancing Large Language Models (LLMs) with optimized context retrieval systems to improve their factual accuracy and reliability in medical question answering tasks.
The study also explores techniques like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) for enhancing the quality of retrieved information.
🏆 The performance of open LLMs augmented with the optimized retrieval system compared to private solutions
Open LLMs augmented with the optimized retrieval system achieved performance comparable to the biggest private solutions on established healthcare benchmarks. Specifically, when enhanced with the optimized context retrieval system, models like Llama-3.1-70B and Qwen-2-72B demonstrated competitive performance with Google's MedPalm-2 and OpenAI's GPT-4 on multiple-choice medical question answering tasks.
📊 The main findings and implications of the research
The main findings and implications of the research include:
Context retrieval systems significantly boost the performance of LLMs in healthcare tasks, particularly for smaller models.
Open-source LLMs, when augmented with optimized retrieval systems, can achieve accuracy comparable to larger private models.
The proposed OpenMedPrompt framework shows promise in improving open-ended answer generation in the medical domain.
These advancements have the potential to democratize access to high-performing healthcare AI systems by reducing reliance on resource-intensive large models.
🔮 Future directions and potential improvements suggested by the authors
The authors suggest several future directions and potential improvements:
Exploring dynamic retrieval techniques that adapt the number of retrieved examples based on question complexity.
Investigating the integration of multiple knowledge sources to enrich the retrieval database.
Adapting the retrieval system to support multiple languages for broader access to medical information.
Developing hybrid approaches combining OM-ER and OM-SR for more robust open-ended medical question answering.
Investigating more sophisticated reward models tailored specifically to medical knowledge evaluation.
Extending OpenMedprompt to other specialized domains beyond medicine.