
🥇 Breakthrough Research Enables AI-Written CUDA Kernels to Outperform NVIDIA’s Best Matmul Library
AI writes faster CUDA kernels than NVIDIA, OpenAI trains models to self-report lies, Nova 2.0 drops, Qwen stabilizes RL with sampling, and Anthropic launches Claude for Nonprofits.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (4-Dec-2025):
🥇 Breakthrough Research Enables AI-Written CUDA Kernels to Outperform NVIDIA’s Best Matmul Library
🕵️♂️ Beautiful new study by OpenAI - Teaches models to confess when they cheat or hallucinate.
🏆 Amazon is back with Nova 2.0.
📡 Emad Mostaque’s latest interview and prediction for AI in 2026
🛠️ Qwen publishes new study showing how sampling is used to stabloze Reinforcement Learning training
💡 Anthropic launches Claude for Nonprofits, offering up to 75% discounts on its advanced plans.
🥇 Breakthrough Research Enables AI-Written CUDA Kernels to Outperform NVIDIA’s Best Matmul Library

Their proposed CUDA-L2 fully automatically writes GPU code for matrix multiplication that runs about 10%–30% faster than NVIDIA’s already-optimized cuBLAS/cuBLASLt library. They also have released the full code on Github.
“CUDA-L2, proposed in this paper, shows that even the most performance-critical, heavily-optimized kernels like HGEMM can be improved through LLM-guided RL automation by systematically exploring configuration spaces at scales impractical for humans.”
Traditional GPU libraries use a few human-experts written kernel templates, and autotuners only tweak knobs like tile sizes inside those fixed designs.
In CUDA-L2, an LLM trained with reinforcement learning literally prints out the full CUDA kernel source code for each shape, and that code can change structure, loops, tiling strategy, padding, swizzle pattern, and even which programming style it uses (raw CUDA, CuTe, CUTLASS style, inline PTX).
The reinforcement learning loop runs these generated kernels on real hardware, measures speed and correctness, and then updates the LLM so that over time it learns its own performance rules instead of humans manually encoding all those design choices.
So what’s the practical impact ?
For LLM pretraining and fine tuning, most of the GPU time is spent doing these HGEMM matrix multiplies, so if those kernels run about 10% to 30% faster, the whole training or tuning job can get noticeably cheaper and quicker.
Because CUDA-L2 handles around 1000 real matrix sizes instead of a few hand tuned ones, the speedups apply to many different model widths, heads, and batch sizes, even when people change architectures or quantization schemes.
This could mean fitting more training tokens or more SFT or RLHF runs into the same GPU budget, or finishing the same schedule sooner without changing any high level training code once these kernels are plugged under PyTorch or similar stacks.
The method itself, letting an LLM plus reinforcement learning generate kernels, also gives a general recipe that could later be reused to speed up other heavy ops like attention blocks or Mixture of Experts layers without needing a big team of CUDA specialists.
CUDA-L2’s HGEMM kernels are consistently faster than standard GPU libraries across 1000 real matrix sizes.
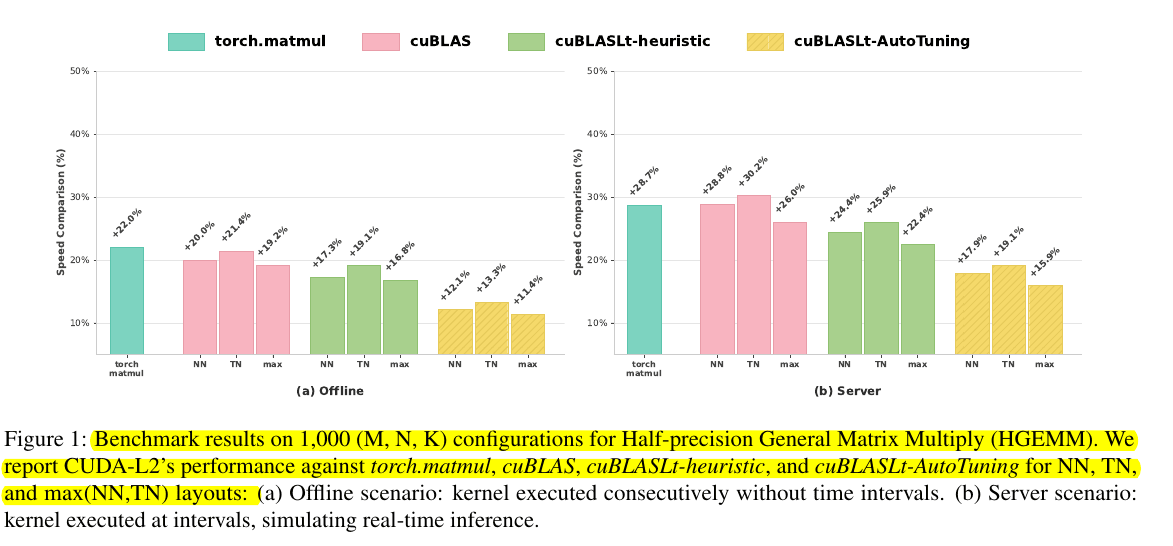
In the offline case on the left, CUDA-L2 is roughly 17% to 22% faster than torch.matmul, cuBLAS, and cuBLASLt, and still about 11% faster than cuBLASLt AutoTuning even though that baseline already runs its own kernel search.
In the server case on the right, which better mimics real inference with gaps between calls, the speedups grow to around 24% to 29% over torch.matmul and cuBLAS and about 15% to 18% over cuBLASLt AutoTuning, so the AI generated kernels keep a strong lead in a more realistic deployment setting.
🧩 What CUDA-L2 actually is

CUDA-L2 starts from a strong base model, DeepSeek 671B, and continues pretraining it on a large collection of CUDA kernels drawn from the web plus high quality library code from PyTorch, ATen, CUTLASS, and NVIDIA examples, so the model sees many real patterns for tiling, memory movement, and tensor core usage.
For each code snippet, the authors use another model to generate a natural language instruction that describes what the kernel is supposed to do, then they retrieve relevant documentation or examples and attach that as extra context, which turns each training example into an instruction plus supporting notes plus the final kernel implementation.
On top of that continued pretraining, they run a first reinforcement learning stage on about 1000 general CUDA kernels that all have a trusted reference implementation, so the model learns to propose kernels, see their speed relative to a baseline, and adjust its coding style to run faster across many different operation types. READ THE FULL PAPER.
Reinforcement learning uses a contrastive setup, where the model compares several of its own kernels and their measured speeds, reasons about why some are faster, and then updates its parameters with Group Relative Policy Optimization (GRPO) to favor the coding decisions that correlate with speed.
🕵️♂️ Beautiful new study by OpenAI - Teaches models to confess when they cheat or hallucinate.

This project adds an honesty head that reports the answer misbehaved. A second channel tells operators whether the answer broke rules. Instead of hiding reward hacking, the model records it in a confession.
Normal reinforcement learning bundles correctness, policy rules and user preference into one reward, which lets models learn shortcuts that please the judge while still hallucinating, breaking rules or quietly sandbagging. Confessions add a second output that lists the instructions, checks which ones were followed and flags uncertainty, while a separate reward model scores only this self analysis and never touches the reward for the main answer.
On adversarial evaluations for hallucination, instruction breaking, scheming and reward hacking, a confession trained GPT 5 model kept bad but silent cases at about **4.4%**, the failure mode safety teams care most about. In a separate run where both answer and confession used the same weak judge, the model learned to exploit that judge in its main output while its confessions approached **near 100%** admission whenever it failed.
Because there are rarely perfect labels for rule breaks, the system instead rewards detailed confessions, and honesty tends to win because spinning a fake story that passes the judge is harder than explaining what really happened. Confessions neither prevent bad behavior nor fix ambiguity or model confusion, but as a layer next to chain of thought monitoring and rule hierarchies they give LLM agents a dedicated honesty head that looks like a clean tool for debugging systems.
🏆 Amazon is back with Nova 2.0.

A clear improvement over past Nova models and stands out in agent-focused tasks.
Launched 3 models
Nova 2 Pro on Bedrock with a focus on reasoning, cost control, and deep customization.
Nova Omni is fully multimodal reasoning model that takes text, images, audio, and video as input, then plans steps and produces actions or outputs across those modalities.
Nova 2 Lite (fast and cheap)
Nova 2 Pro is in preview with early access available to all Amazon Nova Forge customers. Nova 2 Lite is the fast, lower cost workhorse with step by step reasoning, 3 thinking levels, built in code interpreter and web grounding, a 1M token window, and SFT or full fine tuning for chat, document flows, and automation.
Nova 2 Pro targets hard agentic jobs like multi document analysis, video reasoning, and software migrations with deeper multistep planning, the same tool stack, and the 3 thinking levels to trade speed and cost. Nova Omni is the fully multimodal reasoning model that accepts text, images, audio, and video, grounds across time and frames, uses tools, and keeps long mixed media sessions in the 1M token context for tasks like meeting understanding, video Q&A, and UI workflows.
PRICING:
Amazon set Nova 2.0 Pro at $1.25 per million input tokens and $10 per million output tokens, and based on our token use, it cost $662 to run our Artificial Analysis Intelligence Index. That is noticeably lower than models like Claude 4.5 Sonnet at $817 and Gemini 3 Pro at $1201, but still higher than options such as Kimi K2 Thinking at $380. Nova 2.0 Lite and Omni come in cheaper at $0.3 per million input tokens and $2.5 per million output tokens.
📡 Emad Mostaque’s latest interview and prediction for AI in 2026

Some quotes from this interview.
“Next year AI becomes good enough overnight and job losses start.”
“They will create a digital replica of you for $1,000”
“Most human cognitive labor will probably turn negative in value.”
“Lower rates will spur hiring AI workers, breaking the labor-capital link.”
“As the Models get smarter they start hide behavior, add self-revival routines, and lie before alignment.”
“P(doom) is 50%, with timelines of 10 to 20 years.”
🛠️ Qwen publishes new study showing how sampling is used to stabloze Reinforcement Learning training

They argue RL with LLMs is reliable when the token-level policy-gradient first-order approximation matches the true sequence reward, which requires small training-inference discrepancy and small policy staleness. A surrogate gradient is a stand-in slope that is easy to compute and used to guide updates when the true objective is hard or impossible to differentiate. It tells the model which direction to nudge its parameters so rewards should go up, even though it is not the exact gradient of the real goal.
The surrogate gradient equals the real objective when the rollout policy that produced samples equals the target policy being updated, so keeping those policies close makes updates correct. They show the per-token importance weight splits into an engine-mismatch factor and a staleness factor, so either gap adds bias or variance that destabilizes learning.
The engine gap comes from different kernels, precision choices like FP8 inference vs BF16 training, batching quirks, and in Mixture-of-Experts (MoE) models inconsistent routers that pick different experts for the same token. Staleness appears when a large batch is reused across many mini-batches or in asynchronous pipelines, so later updates chase behavior that no longer reflects the current policy.
The fixes are importance sampling (IS) correction to account for engine mismatch, clipping to cap risky updates, and Routing Replay to freeze routed experts so MoE behaves like a dense model, with R2 replaying training-router choices and R3 replaying inference-router choices. Experiments show basic on-policy policy-gradient with IS is most stable, while off-policy requires clipping plus Routing Replay, with R2 better at small off-policiness and R3 better as off-policiness grows. So overall, the claim is that shrinking both gaps keeps the surrogate gradient accurate and lower variance, which prevents collapse and delivers steady reward and benchmark gains.
💡 Anthropic launches Claude for Nonprofits, offering up to 75% discounts on its advanced plans.

Discounted Team and Enterprise plans include Claude Sonnet 4.5 for heavier analysis and grant writing, Claude Haiku 4.5 for high speed everyday tasks, and optional Claude Opus 4.5 for the hardest reasoning problems. Connectors now plug Claude into Microsoft 365, Google Workspace, and other collaboration tools, plus open source links to Benevity for validated nonprofits, Blackbaud for donor data, and Candid for funders and grants, with a free AI Fluency for Nonprofits course and pilots across 60+ grantees showing where this fits from proposals to impact reporting.
That’s a wrap for today, see you all tomorrow.