
🥊 ByteDance Doubao-1.5-pro model matches GPT 4o benchmarks at 50x cheaper
ByteDance disrupts with Doubao-1.5-pro and VideoWorld, Hugging Face launches compact vision models, Meta commits huge capex for AI, and groundbreaking AI tools emerge in open-source and edge domains.
Read time: 7 min 49 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 3.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-Jan-2025):
🥊 ByteDance Doubao-1.5-pro model matches GPT 4o benchmarks at 50x cheaper
🏆 Hugging Face unveiled SmolVLM 256M and 500M, hailed as the world’s smallest vision language models that maintain competitive performance against larger rivals
📡 Meta announced to spend up to $65 billion and deploy 1 GW of computing power in 2025 to power AI goals
🛠️ ByteDance releases VideoWorld, a simple generative model that, unlike Sora and DALL-E, doesn't rely on language to understand the world
🗞️ Byte-Size Briefs:
DeepSeek-R1 matches top reasoning models, 20x cheaper, open-source.
ByteDance invests $20B in global AI expansion, chips, data centers.
All-AI book created with Gemini Flash, 3.9 hours, 203 pages.
Kyutai Labs unveils Helium-1 LLM for edge, multilingual, open-source.
🧑🎓 Deep Dive Tutorial
Stop Few-Shot Prompting Your Reinforcement Learning-Based Reasoning Models: DeepSeek-R1's Insights into Optimal Prompting Strategies
🥊 ByteDance Doubao-1.5-pro model matches GPT 4o benchmarks at 50x cheaper
🎯 The Brief
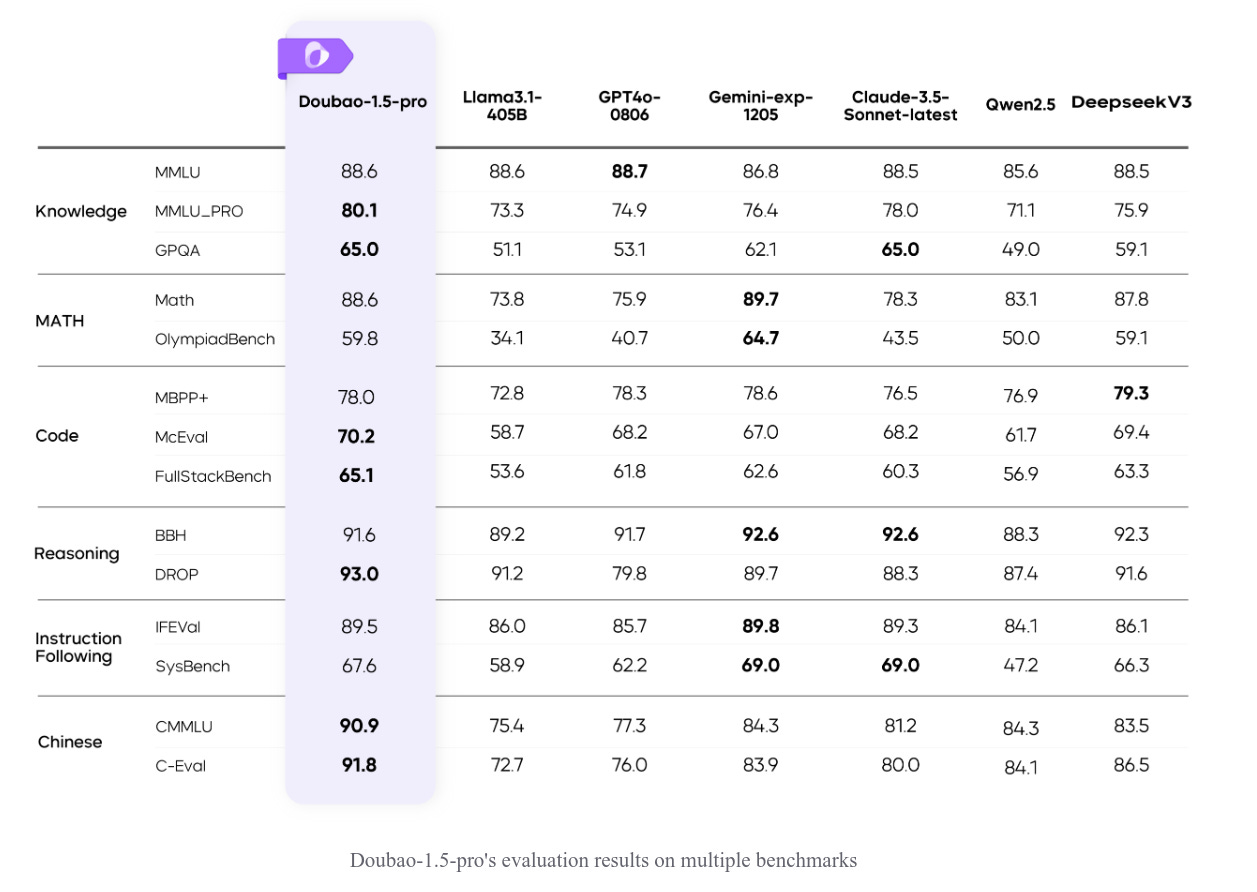
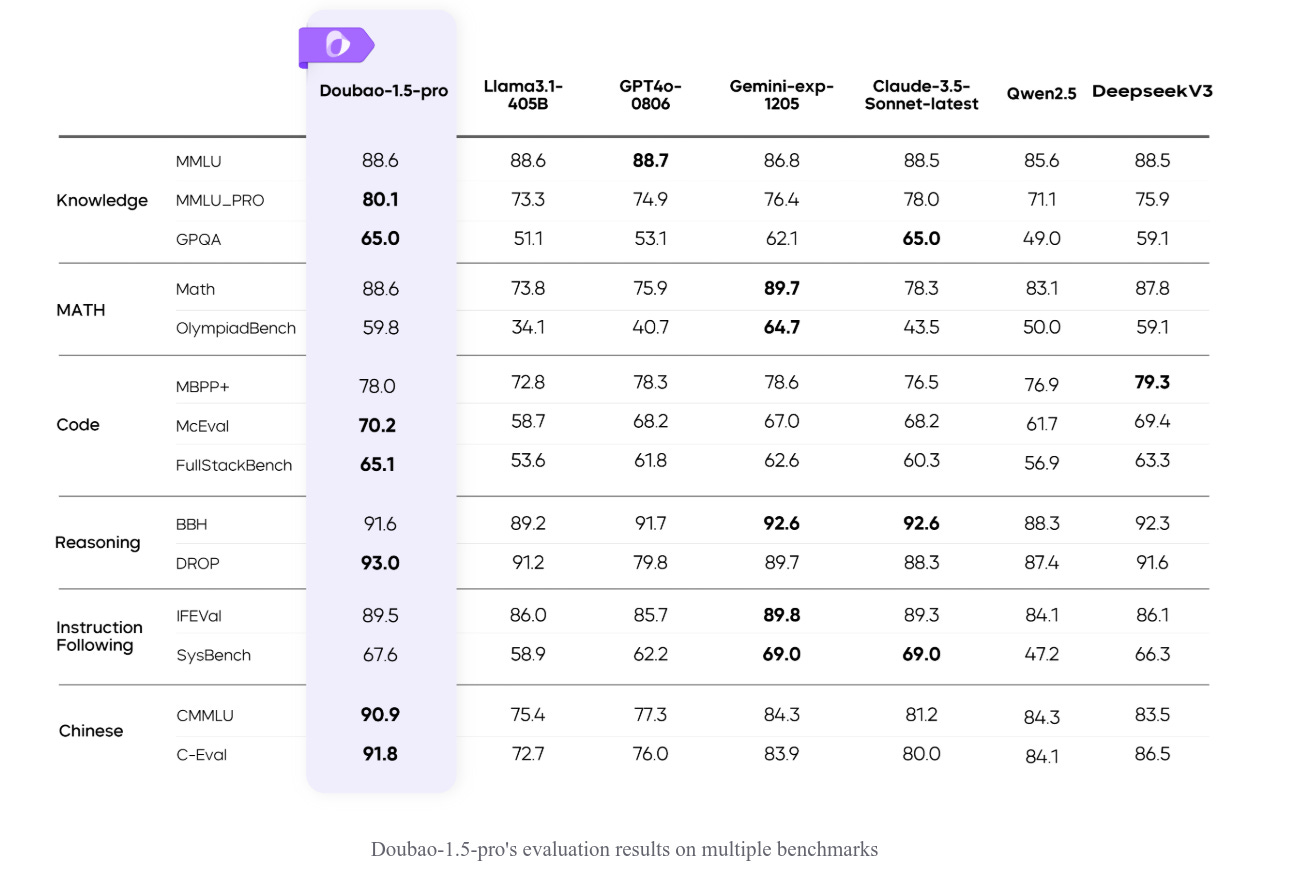
The Doubao-1.5-pro model, developed by the Doubao team, introduces a sparse MoE (Mixture of Experts) architecture, achieving superior performance on public evaluation benchmarks compared to ultra-large dense models like Llama3.1-405B. It balances high performance and efficient inference, enhances multimodal capabilities, and integrates advanced reasoning. 32k + 256k context-window.
$0.022/Mn cached input tokens, $0.11/M input, $0.275/M output
The above prices are for 32k, Doubao 1.5 pro 256k is priced at $1.23/M output.
⚙️ The Details
→ Doubao-1.5-pro utilizes sparse MoE architecture, optimizing performance while activating only a fraction of parameters. It achieved a 7x performance leverage, surpassing dense models using the same dataset.
→ The model employs dynamic scaling of parameters (depth, width, experts) to balance application-specific performance with reasoning cost.
→ Advanced reasoning optimizations include chunk-based prefill serving, FlashAttention with 8-bit precision, and W4A8 quantization, boosting memory and computational efficiency.
→ Multimodal capabilities include visual and speech integration. Its self-developed Doubao ViT, supporting dynamic resolution, excels in image tasks, outperforming models 7x its size.
→ Speech enhancements feature end-to-end Speech2Speech with integrated comprehension and generation, surpassing ASR+LLM+TTS cascades.
→ Robust training pipelines ensure high-quality autonomous data annotation, avoiding external model dependency and improving generalization.
→ Multistage RL scaling boosts reasoning ability, achieving state-of-the-art scores on AIME and expanding cross-domain intelligence capabilities.
🏆 Hugging Face unveiled SmolVLM 256M and 500M, hailed as the world’s smallest vision language models that maintain competitive performance against larger rivals
🎯 The Brief
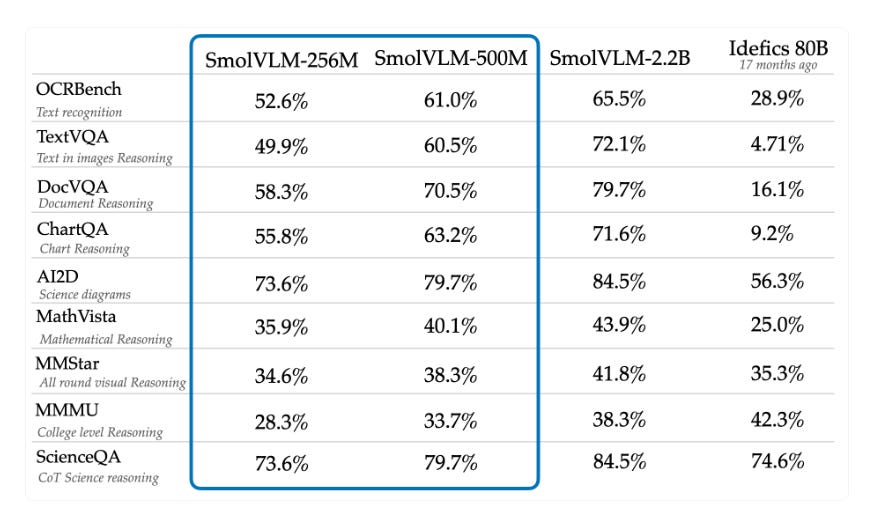
SmolVLM announced two new models: SmolVLM-256M (256 million parameters) and SmolVLM-500M (500 million parameters), marking them as the smallest Vision Language Models (VLMs) available. These models aim to balance efficiency and strong multimodal performance while being highly accessible for devices with limited resources. They also introduce enhanced training optimizations, new vision encoders, and tokenization techniques, offering significant performance at a fraction of the cost of larger models.
⚙️ The Details
→ The SmolVLM-256M is now the smallest VLM, delivering strong performance on tasks like image captioning, document Q&A, and visual reasoning despite its small size.
→ The SmolVLM-500M offers a balance between compactness and performance, excelling in more demanding tasks like DocVQA and MMMU with better robustness to prompts.
→ Both models use the 93M SigLIP base patch-16/512 encoder, which delivers nearly the same performance as the larger SigLIP 400M SO encoder but allows for larger image resolution processing with minimal overhead.
→ The training optimizations include an improved tokenization strategy that compresses image token representations (4096 pixels/token vs. 1820 pixels/token in the 2B model), enhancing stability and real-world benchmarks.
→ The models were fine-tuned with an updated data mixture, prioritizing document understanding (41%) and image captioning (14%), alongside other multimodal tasks.
→ These models integrate seamlessly with tools like transformers, MLX, and ONNX, enabling straightforward fine-tuning, inference, and multimodal retrieval use cases. The release also includes WebGPU demos.
→ The ColSmolVLM extension delivers state-of-the-art multimodal retrieval speeds, further reducing costs for database search applications.
→ With the release of SmolVLM-256M and 500M, the SmolVLM and SmolLM2 ecosystems now offer a complete range of smaller LLM+VLM combinations across multiple parameter sizes for diverse use cases.
Get started with SmolVLM using transformers like below.
📡 Meta announced to spend up to $65 billion and deploy 1 GW of computing power in 2025 to power AI goals

🎯 The Brief
Meta CEO Mark Zuckerberg announced a massive $65 billion investment in AI infrastructure for 2025, signaling an aggressive push to compete with OpenAI and Google in the AI race. This move, exceeding Wall Street estimates, includes building a 2 GW data center and significantly increasing AI roles, driven by the urgency created by Trump's $500 billion Stargate initiative. Meta aims to have over 1.3 million GPUs by year-end. 1 GW of computing is equivalent to powering roughly 750,000 US homes.
⚙️ The Details
→ Meta's $65 billion capital expenditure for 2025 surpasses analyst predictions of $50.25 billion and is a significant jump from the estimated $38-40 billion in 2024. This investment will fund a data center larger than 2 GW, covering a substantial area.
→ Meta plans to deploy 1 GW of computing power in 2025 and aims to possess over 1.3 million GPUs by the end of the year, making them a top buyer of Nvidia AI chips.
→ Zuckerberg stated 2025 is a "defining year for AI" and this investment will enhance Meta's core products and business. The announcement follows Trump's Stargate initiative, a $500 billion AI infrastructure venture, likely prompting Meta to assert its AI ambitions.
→ Meta's open-source Llama models and AI assistant, expected to reach over 1 billion users in 2025 (up from 600 million monthly active users), position them as a major AI player.
🛠️ ByteDance releases VideoWorld, a simple generative model that, unlike Sora and DALL-E, doesn't rely on language to understand the world

🎯 The Brief
ByteDance Seed introduces VideoWorld, a generative model, demonstrating that AI can acquire complex knowledge like rules, reasoning, and planning solely from visual input, achieving 5-dan professional level in Video-GoBench with a 300M parameter model and excelling in robotic control tasks. This is significant because it challenges the reliance on text-based models and opens new avenues for visual knowledge acquisition.
⚙️ The Details
→ VideoWorld is an auto-regressive video generation model trained on unlabeled video data. It's tested on video-based Go and robotic control tasks.
→ Key findings show video-only training is enough for knowledge learning, and visual change representation is crucial.
→ They introduce Latent Dynamics Model (LDM) to improve efficiency and efficacy. LDM compresses future visual changes into latent codes.
→ VideoWorld reaches 5-dan in Video-GoBench with a 300M parameter model without search algorithms or reward mechanisms.
→ In robotics, it learns diverse controls and generalizes across environments, approaching oracle model performance in CALVIN and RLBench.
→ The model uses a VQ-VAE and auto-regressive transformer architecture. It leverages latent codes and predicted frames for task operations using an Inverse Dynamics Model (IDM).
→ They also built Video-GoBench, a large-scale video-based Go dataset for training and evaluation.
🗞️ Byte-Size Briefs
DeepSeek-R1 now ranks #3 overall in Arena, matching top reasoning models while being 20x cheaper and fully open-weight. It dominates technical benchmarks like coding, math, and hard prompts, ties for style control leadership, and offers MIT-licensed access for full transparency.
ByteDance is planning to spend $20 billion in 2025 to expand its AI infrastructure globally, with half invested overseas in data centers and chip supply chains. This aims to support AI app growth, strengthen domestic AI leadership, and counter U.S. TikTok challenges.
In a viral post world's first all-AI written (no human involved) 203-page book is launched. On how tiny SaaS startups can get to the top. Using Gemini Flash-Exp 2.0 over 1000 API calls and 170 million tokens. 3.9 hours to complete. Get the prompt here.
Kyutai Labs dropped Helium-1 Preview on Huggingface. Its a 2B Base LLM for mobile / edge with Multi-lingual capability. CC-BY-4.0 license and integrated with transformers.
🧑🎓 Deep Dive Tutorial
Stop Few-Shot Prompting Your Reinforcement Learning-Based Reasoning Models: DeepSeek-R1's Insights into Optimal Prompting Strategies

Know how reinforcement learning reshapes LLM prompting strategies for reasoning tasks.
📚 Key Takeaway
Understand why zero-shot prompting outperforms few-shot for RL-trained models like DeepSeek-R1.
Explore how reinforcement learning focuses on internal reasoning and avoids external interference.
Study the impact of complex vs. direct prompts on model performance in RL-trained systems.
Learn about prompt sensitivity in RL models, particularly how nuanced inputs influence reasoning.
Analyze the effects of mixed-language prompts causing fragmented reasoning pathways.
Compare prompting behaviors of RL models with supervised fine-tuned (SFT) models.
Discover best practices for clear problem description and consistent language in RL-driven prompting.