
👨🔧 Bytedance Just Launched An Opensource Lipsync Model LatentSync
Bytedance's LatentSync lipsync model, Google's AI agents whitepaper, breakthrough RL algorithm, plus updates on Altman's AI claims and Stanford's STORM platform.
Read time: 5 min 9 seconds
⚡In today’s Edition (5-Jan-2025):
👨🔧 Bytedance Just Launched An Opensource Lipsync Model LatentSync
🦜 Google Releases White Paper On AI Agents Covering The Basics And A Quick Langchain Implementation
🏆 A New Reinforcement Learning Algo With Outcome-Based Rewards Achieves Better Results Using 90% Less Data
🗞️ Byte-Size Brief:
Sam Altman hints at singularity breakthrough, signaling transformative AI capabilities
Samsung acquires 35% Rainbow Robotics stake, advancing humanoid robotics development
Stanford launches STORM AI opensource multi-agent research system, outperforms major platforms
SmallThinker-3B releases mobile-first 3B parameter model achieving CoT reasoning
🧑🎓 Deep Dive Tutorial
🧠 An Analysis Of AI's Rapid Evolution In December-24, Showcasing Breakthrough Capabilities Across Multiple Domains.
👨🔧 Bytedance Just Launched An Opensource Lipsync Model LatentSync
🎯 The Brief
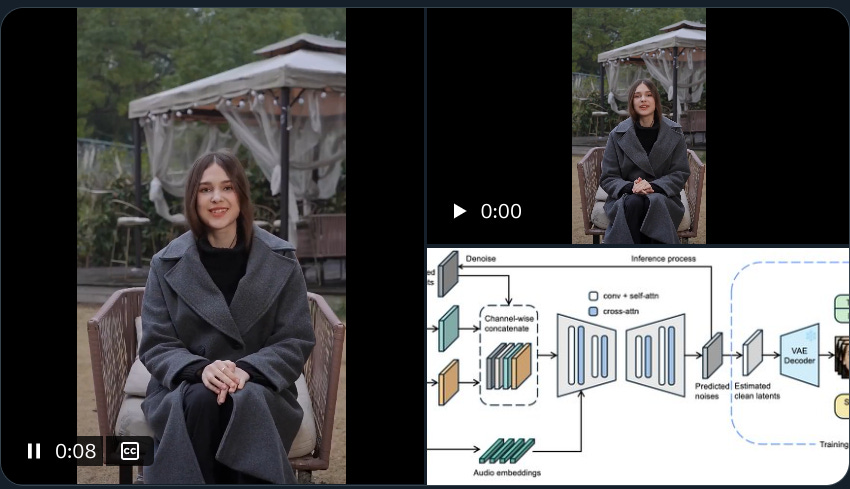
ByteDance introduces LatentSync, an end-to-end audio-conditioned latent diffusion model for lip synchronization, achieving 94% accuracy on the HDTF test set. This new framework outperforms existing methods by leveraging Stable Diffusion capabilities and implementing Temporal REPresentation Alignment (TREPA) for enhanced temporal consistency. The GitHub code is here.
⚙️ The Details
→ The model demonstrates superior performance across multiple metrics, achieving SSIM scores of 0.79 on HDTF and 0.81 on VoxCeleb2 datasets. LatentSync significantly outperforms existing solutions like Wav2Lip, VideoReTalking, DINet, and MuseTalk in lip-sync accuracy and visual quality.
→ A key innovation is the implementation of TREPA (Temporal REPresentation Alignment), which uses temporal representations extracted by large-scale self-supervised video models to align generated frames with ground truth frames. This maintains high lip-sync accuracy while improving temporal consistency.
→ The framework operates without intermediate motion representation, diverging from previous diffusion-based methods that rely on pixel space diffusion or two-stage generation. The model utilizes SyncNet supervision with a batch size of 1024 and 16 frames for optimal performance.
→ Quality control includes filtering videos using HyperIQA scores, removing any content scoring below 40 to maintain high visual standards. The model is so good, that it could literally replace every news anchor.
🦜 Google Releases White Paper On AI Agents Covering The Basics And A Quick Langchain Implementation
🎯 The Brief
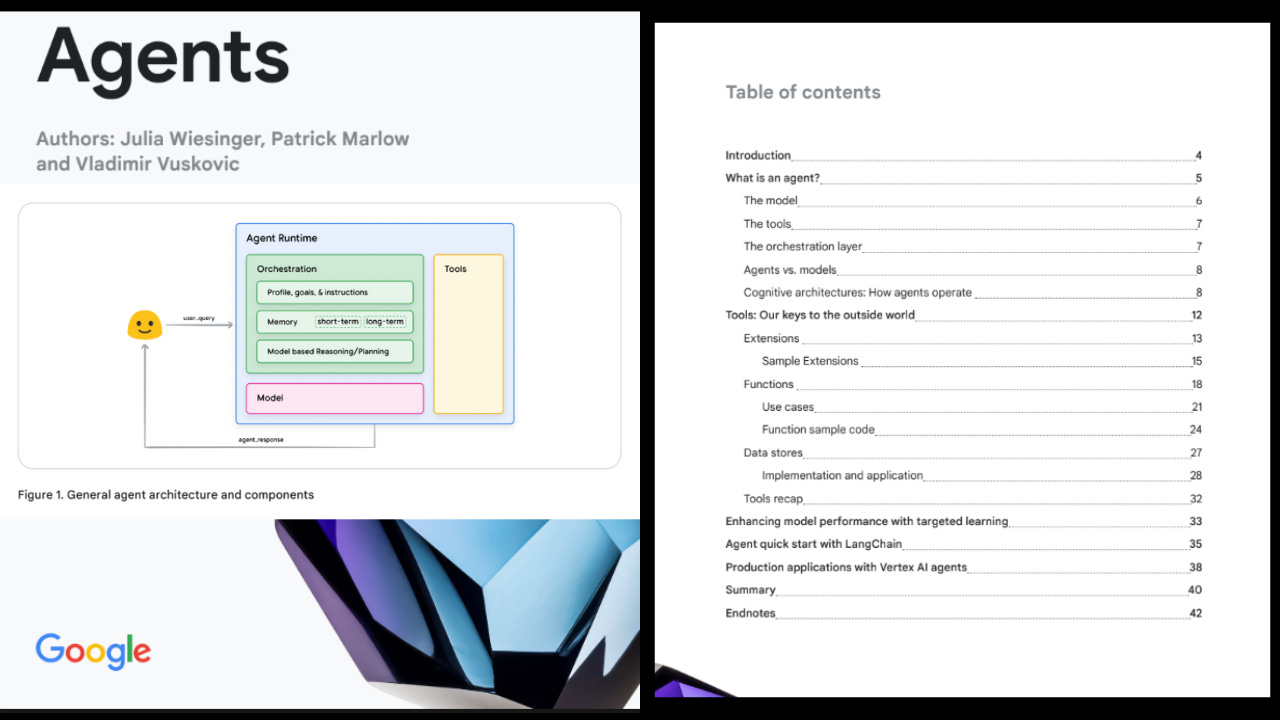
Google releases comprehensive white paper detailing the three-layer architecture for building AI agents, integrating LLMs with real-world tools and orchestration systems to enable autonomous task completion. This represents a major advancement in practical AI system design and production-grade implementation.
⚙️ The Details
→ The architecture consists of three fundamental layers: Model Layer for cognitive processing, Orchestration Layer for execution management, and Tools Layer for real-world interactions. The Model Layer leverages advanced prompting frameworks like ReAct and Chain-of-Thought for structured reasoning.
→ The Tools Layer introduces three key components: Extensions for direct API integration, Functions for client-side control, and Data Stores for vector database integration enabling RAG capabilities. These tools bridge the gap between model capabilities and real-world applications.
→ Implementation challenges focus on sophisticated tool selection logic, robust state management across conversations, and performance optimization for real-time operations. The system balances inference latency with reasoning depth while managing API efficiencies.
→ The architecture demonstrates evolution from simple LLM interfaces to production-ready AI systems, emphasizing practical engineering requirements over theoretical capabilities. This framework provides a foundation for building complex, autonomous AI agents.
🏆 A New Reinforcement Learning Algo With Outcome-Based Rewards Achieves Better Results Using 90% Less Data

🎯 The Brief
Researchers introduced PRIME (Process Reinforcement through IMplicit REwards), a novel reinforcement learning framework that achieves 26.7% pass@1 on AIME 2024, surpassing GPT-4 and Qwen2.5-Math-7B-Instruct while using only 1/10th of the training data. This breakthrough demonstrates efficient scaling of advanced reasoning capabilities through implicit process rewards.
⚙️ The Details
→ PRIME introduces implicit process reward modeling that requires no process labels, training as an outcome reward model while functioning as a process reward model during inference. The system provides dense token-level rewards without needing additional value models.
→ The framework employs online prompt filtering that dynamically maintains problems within 0.2-0.8 accuracy range, ensuring stable training progression. This approach outperforms static filtering methods by adapting to model improvements.
→ Implementation combines RLOO ( "Reinforcement Learning Leave-One-Out"), for advantage estimation with PPO policy updates, demonstrating 16.7% average improvement over supervised fine-tuning. The model, Eurus-2-7B-PRIME, achieves strong performance across mathematical reasoning benchmarks with only 230K SFT and 150K RL training examples.
🗞️ Byte-Size Brief
Sam Altman tweeted indicating that humanity might be on the cusp of reaching the technological singularity, the hypothesized point at which artificially intelligent systems surpass human comprehension, autonomy, or capabilities.
Samsung bets big on robots, partners with creators of Korea's first walking humanoid. The 35% stake acquisition brings Rainbow Robotics' manufacturing expertise under Samsung's umbrella, establishing a Future Robotics Office led by KAIST's robotics pioneer Dr. Jun-Ho Oh.
Stanford's STORM AI outperforms Perplexity & Google Deep Research - and it's completely FREE. STORM AI combines multiple AI agents to generate comprehensive research reports that surpass commercial alternatives. The open-source system simulates diverse expert viewpoints, producing Wikipedia-style documentation while matching or exceeding the capabilities of established platforms like Perplexity.
SmallThinker-3B achieves chain-of-thought reasoning capabilities in a compact 3B parameter model. It’s small enough to run on your phone. SmallThinker-3B serves as an efficient draft model for larger systems, accelerating generation speed by 70%. The project includes a massive dataset of long-form reasoning examples.
🧑🎓 Deep Dive Tutorial
🧠 An Analysis Of AI's Rapid Evolution In December-24, Showcasing Breakthrough Capabilities Across Multiple Domains.
This blog discusses:
Emergence of multiple GPT-4 class open-source models and their technical architectures
Test-time compute methods enabling superior reasoning in LLMs through o1's approach
Implementation details of running advanced AI locally on consumer hardware
Medical diagnosis systems achieving superhuman performance through novel neural architectures
Multi-modal integration techniques combining voice, vision, and reasoning capabilities
Video generation breakthroughs in physics simulation and scene consistency
Some techniques explored:
Advanced prompt engineering for research-grade tasks
Local inference optimization strategies
Multi-modal model architecture designs
Hardware-software co-optimization techniques
Test-time compute implementation specifics