
🎨 ByteDance launched Seedream 4.0, ranked top on Artificial Analysis index
Replit’s Agent 3 builds agents, Seedream 4.0 edits images, Rubin CPX stuns, and Thinking Machines wants AI to behave, SemiAnalysi report on new NVIDIA GPU
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (11-Sept-2025):
🎨 ByteDance launched Seedream 4.0, a unified image generator and editor.
🧩 Thinking Machines’s mission is to make AI models predictable instead of inconsistent
🛠️ Today’s Sponsor: Notta Memo from NottaOfficial - How AI shows up in a small, everyday device
🚀 Replit launched Agent 3, a coding agent that tests apps in the browser, fixes failures automatically, and can even build other agents
🧑🎓 SemiAnalysis published a comprehensive report on Nvidia’s newly announced powerful GPU Rubin CPX
🎨 ByteDance launched Seedream 4.0, a unified image generator and editor.
TikTok’s parent company, ByteDance, just launched its new image generation tool, Seedream 4.0.
Seedream 4 can generate images with up to 4K resolution, supports up to six image references, and works across multiple aspect ratios. This makes the model superior to Nano Banana, which can only generate square photos at 1080p resolution. More importantly, Seedream 4 is cheaper to run.
Bytedance's new text-to-image Seedream 4.0, now tops across both the Artificial Analysis Text to Image and Image Editing Arena.

10x faster inference, strong prompt following, and lower cost, which targets faster creative workflows.
Seedream 4.0 merges Seedream 3.0 text-to-image and SeedEdit 3.0 editing into one model so the same engine can create and then precisely revise without tool switching.
ByteDance reports a new architecture that boosts raw image generation speed by over 10x, which cuts wait time and makes iterative edits feel close to real time.
The company claims wins on its MagicBench for prompt adherence, alignment, and aesthetics, but there is no public technical report for these numbers.
Artificial Analysis frames it as a step up because it keeps pricing at US$30 per 1,000 generations while adding first-class editing from SeedEdit 3.0.
On Fal. ai the pay-per-image price is US$0.03 for Seedream 4.0 versus US$0.039 for Gemini 2.5 Flash Image, which can add up for large batches.
User feedback highlights accurate text-driven edits, 2K images in under 2s, 4K support, multi-image batches, and looser content filters than Nano Banana, though these are community claims not audited lab tests.
Public leaderboards still show Gemini 2.5 Flash Image at the top for both generation and editing and Seedream 4.0 has not been scored there yet, so the head-to-head depends on what metric is used.
🧩 Thinking Machines’s mission is to make AI models predictable instead of inconsistent
Mira Murati’s Thinking Machines Lab, backed by $2 billion in seed funding and powered by a team of former OpenAI researchers, has revealed its first major project, developing AI models capable of delivering consistent, reproducible responses. The announcement, shared in a blog post on Wednesday, marks the lab’s debut in a field that has drawn intense global interest.
In its blog post titled “Defeating Nondeterminism in LLM Inference,” Thinking Machines Lab explores why AI models often produce unpredictable outputs.
For example, ask ChatGPT the same question a few times over, and you’re likely to get a wide range of answers.
This has largely been accepted in the AI community as a fact — today’s AI models are considered to be non-deterministic systems— but Thinking Machines Lab sees this as a solvable problem.
Thinking Machines published a solid blog yesterday and says, that AI randomness mostly comes from how GPU kernels get stitched and scheduled during inference, and that tighter control here can deliver deterministic inference.
That would give enterprises repeatable answers and make reinforcement learning cleaner by cutting label noise from slightly different outputs.
A GPU kernel is a tiny program that runs the math on the graphics processor, and when thousands run in parallel, small things like the order of adds, thread timing, atomic updates, or library choices can nudge numbers in different directions.
Floating point math is not perfectly associative, so changing the reduction order or mixing precisions tweaks the last few bits, which then cascades through layers into a different token choice.
The proposed fix is an orchestration layer that locks down kernels, seeds, algorithms, and execution graphs, pins math library versions, and enforces a repeatable schedule across runs and machines.
That kind of guardrail usually trades a bit of throughput for stability, but it pays off when scientists or auditors need the exact same answer on rerun.
The lab also points to using reinforcement learning to tailor models for businesses, which gets easier when the reward signal comes from consistent model outputs instead of a fuzzy mix.
They plan frequent research posts and code releases under a series called Connectionism, and a first product aimed at researchers and startups is said to be coming soon.
Given a $12B valuation, the big question is whether they can prove determinism at scale without hurting speed and cost.
The view here is that kernel-level determinism is a practical, engineering-first path, and if they show identical outputs across nodes and GPUs with minimal slowdown, that would count as a real win for production LLMs.
In July, Murati said Thinking Machines Lab will launch its first product within months for researchers and startups. What it is, and whether it boosts reproducibility, is unknown.
🛠️ Today’s Sponsor: Notta Memo from NottaOfficial - How AI shows up in a small, everyday device

This is world's lightest AI agent at under 1 ounce. Notta Memo from NottaOfficial. It turns raw voice into searchable answers that flow into existing tools. It's is a card-size recorder, press once, it records, then syncs to phone and web.
Speech becomes text in 5 minutes with 98% accuracy across English, Spanish, French, Japanese, Chinese, and more. The transcript is queryable, so you can talk to their recordings, get direct answers, and extract decisions and tasks.
Everything stays in sync across iPhone, Android, web, Chrome, and it pipes summaries to Slack, pushes updates to Salesforce, and stores notes in Notion. The Notta platform also supports video dubbing in 15 languages while preserving the original voice style. Check it out here for yourself.
👨🔧 ⚙️ Google Gemini just added the newly launched Gemini Embedding model to the batch API.

Means, much higher rate limits and at half the price - $0.075 per 1M input tokens non-real-time use cases like data preprocessing. Can run for up to 24 hours.
An embedding is a numeric vector that captures meaning, so similar texts have nearby vectors. That enables semantic search, clustering, deduping, recommendations, and stronger retrieval augmented generation.
Batch processing means requests are queued, processed asynchronously, and returned as 1 aggregated result file, which suits large corpora and latency tolerant pipelines.
A job is created with model gemini-embedding-001, then the client polls until success and downloads the output file for downstream indexing. This flow reduces client retries, smooths over rate spikes, and lowers network chatter, which helps when re-embedding entire datasets or running scheduled refreshes.
The sweet spot is high volume, latency tolerant work such as backfills, nightly syncs, and periodic corpus re-embeddings, where aggregate throughput and price beat per request speed.
A practical guardrail is that jobs may take up to 24 hours, so any user facing or time critical workload should remain on synchronous calls.
🚀 Replit launched Agent 3, a coding agent that tests apps in the browser, fixes failures automatically, and can even build other agents
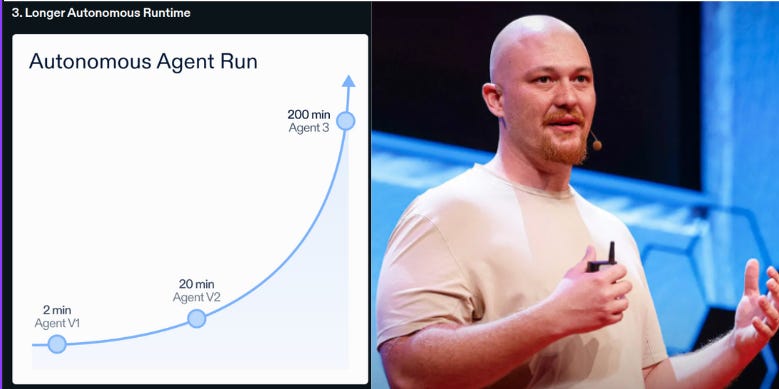
Replit has officially launched Agent 3, its most advanced AI agent yet.
Autonomy jumps by 10x, with runs up to 200 minutes, so complex projects can progress with far fewer handholds.
The Agent builds, runs the app in a real browser, validates behavior, then repairs code until checks pass.
Testing happens inside the workspace preview, where it clicks through UI, calls APIs, fills forms, summarizes any failures, and patches them.
The agent decides when enough has changed to test again, rather than running a test after every prompt which saves both time and tokens.
Max Autonomy, labeled beta, adds longer sessions, task lists, and self supervision so it can plan, monitor progress, and course correct.
Agents and Automations let it spin up Slack or Telegram bots, query Notion or Linear, answer GitHub codebase questions, and file notes to Drive.
The creation flow supports frontend only prototyping or a full stack path, so teams can start with design and add a backend later.
Replit claims the in browser tester is 3x faster and 10x more cost effective than generic computer use approaches, and App Testing is on by default with a toggle to turn it off.
Availability spans free and paid users, while Max Autonomy remains beta and continues to ship inside the main workspace experience.
The launch also arrived alongside a $250M raise at a $3B valuation.
🧑🎓 SemiAnalysis published a comprehensive report on Nvidia’s newly announced powerful GPU Rubin CPX

Nvidia is no longer building one-size-fits-all GPUs. They’re breaking inference into compute-heavy prefill vs bandwidth-heavy decode, and designing different silicon for each.
First some basics
The word CPX stands for Compute Prefill Accelerator. It’s a specialized GPU designed just for the prefill phase of large language model inference. Prefill is the stage where the model processes the user’s input prompt before generating tokens. This step needs huge compute but very little memory bandwidth, so CPX is built with high FLOPS and cheaper GDDR7 memory instead of expensive HBM.
In contrast, the R200 GPUs remain the decode accelerators, since decoding requires high memory bandwidth to repeatedly fetch cached tokens. Most deployments still run prefill and decode on the same HBM box, which wastes money on idle bandwidth and makes the 2 phases slow each other down.
HBM stands for High Bandwidth Memory.
It is a type of specialized computer memory designed to provide very high data transfer speeds compared to traditional DRAM like GDDR. Instead of sitting beside the GPU on a circuit board like GDDR, HBM is stacked vertically in layers (using through-silicon vias, or TSVs) and placed very close to the GPU die through advanced packaging techniques like 2.5D interposers.
This design gives HBM two key advantages:
Huge bandwidth – GPUs can access data at speeds of tens of terabytes per second, which is critical for workloads like AI training and LLM inference decode.
Better energy efficiency – Because the memory is physically closer to the GPU, it uses less power per bit of data transferred than GDDR.
That’s why chips like Nvidia’s R200 use 288GB of HBM with 20.5TB/s bandwidth, while Rubin CPX skips HBM for cheaper GDDR7 since prefill doesn’t need that much bandwidth.
🧠 What Rubin CPX is
Rubin CPX is a single-die GPU built for prefill that brings 20 PFLOPS FP4 dense, 2TB/s bandwidth, and 128GB GDDR7, so spend goes to math not memory. R200 stays the decode engine with 33.3 PFLOPS FP4 dense, 288GB HBM, and 20.5TB/s, which is wasteful for prefill but ideal for fast token steps. Running prefill on CPX and decode on R200 lets racks push arithmetic hard while avoiding unused HBM. Across the full CPX combo rack the system still reaches 1.7PB/s overall bandwidth because 72 R200 keep the fat lanes for decode.
💾 Why prefill hates expensive bandwidth
Prefill pounds matrices on the prompt and writes cache, so the limiter is compute and the memory buses barely move. Decode reloads past tokens every step, so its limiter is memory traffic not math. Sharing 1 HBM GPU for both phases means prefill pays for HBM that mostly sits idle and decode sees contention.
🧮 Bandwidth vs compute, the trade
CPX swaps HBM for GDDR7 and cuts memory price per GB by >50% while holding high FP4 throughput. R200’s HBM got pushed to 10Gbps per pin for 20.5TB/s per GPU, which keeps decode fast. Peak FLOPS is a roof because CPX is around 800W per die and the sandwich module is thermally tight, so sustained rates sit below the headline 20 PFLOPS.
🔌 Networking, and why CPX skips NVLink
CPX speaks PCIe Gen6 x16 into ConnectX-9 for scale out, which is plenty because prefill with pipeline parallelism ships small sequential activations. For DeepSeek V3 on NVFP4 the message size per token is about 7kB, so maxed x16 PCIe Gen6 carries about 18.5M tokens/s while a CPX tops near ~207k tokens/s on compute, so links are not the limiter. Skipping NVLink and NVSwitch saves roughly $8K/GPU, which is about 10% of all-in cluster cost per GPU in this analysis.
💸 Where the dollars actually go
GDDR7 drops memory dollars by roughly 5x and CPX keeps capacity modest, so prefill stops wasting the most expensive part of the package. On the same prefill job R200 leaves about $0.90/hr as idle HBM while CPX leaves about $0.10/hr, so the waste gap is ~9x. At rack scale the spend shifts from HBM and NVLink into compute and NICs, so tokens per dollar rise without slowing decode.
🧪 Pipeline parallelism, the fit for prefill
Pipeline parallelism splits layers across GPUs and passes activations in sequence, which favors simple send/receive over all-to-all collectives. That pattern keeps link traffic low during prefill, so PCIe Gen6 is enough and NVLink adds cost without lifting throughput. The trade is higher time-to-first-token than expert parallel, but sustained tokens per GPU go up and that matters for long prompts.
🏭 Supply chain side effects
Prefill moving to GDDR7 shifts system bills away from HBM, and suppliers like Samsung benefit because this DRAM is cheaper and more available. Lower token price drives more usage, so decode traffic and HBM demand still grow even as prefill stops consuming HBM.
⚖️ What is still hard
The NVL144 CPX rack fixes the prefill to decode ratio in hardware, so the Dual Rack path is safer when workloads swing. Sustained FLOPS are bounded by ~880W per CPX module including memory and by cooling headroom, so scheduling still matters. Rubin’s sparsity could help, but past schemes rarely delivered a full 2x, so count any win only after benchmarks.
🧯 The core play for operators
Split the phases, size CPX for prefill and R200 for decode, keep NVLink only where decode or training needs it, and let NIC-based scale out handle the rest. Do that and you get higher tokens per watt, fewer cross-phase stalls, and simpler racks that are easier to build and service.
That’s a wrap for today, see you all tomorrow.