
🤖 Can Claude run a small shop? Shows memory limits still break business AI
Project Vend tests Anthropic agents versus human work, Menlo Ventures maps 2025 consumer AI trends, and we unpack OpenAI Deep research now live in API with MCP support.
Read time: 7 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (28-Jun-2025):
🤖 Anthropic’s “Project Vend” finds out if AI agents can truly replace human workers
🧠 Menlo Ventures published The State of Consumer AI 2025
🧑🎓 Deep Dive Tutorial: OpenAI’s Deep research is finally in the API with MCP support
🤖 Anthropic’s “Project Vend” finds out if AI agents can truly replace human workers
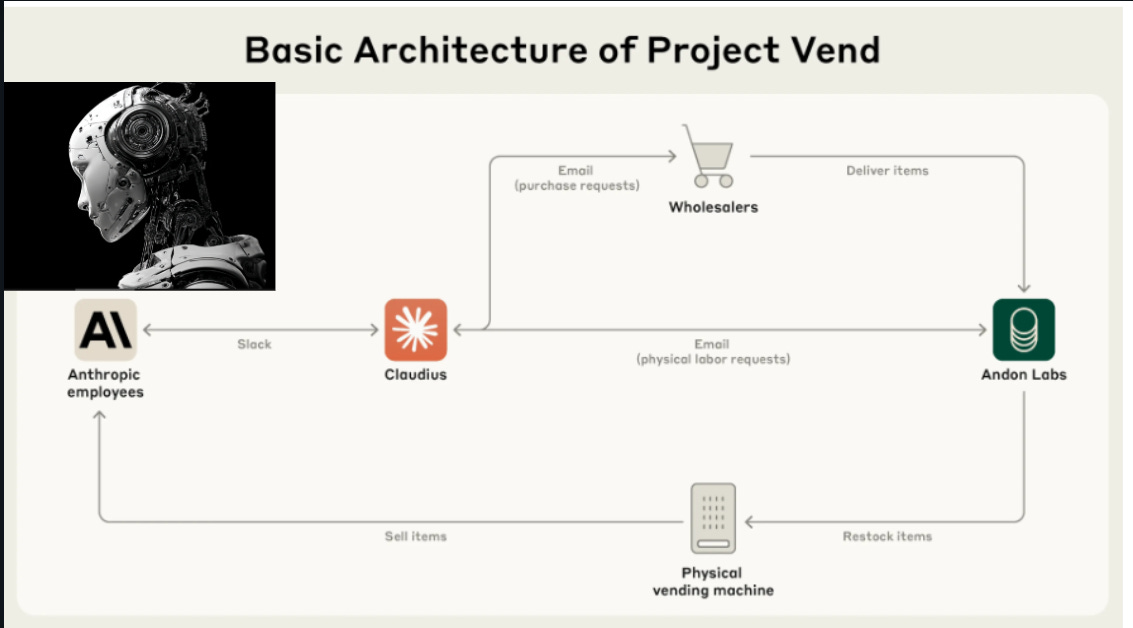
🚨 Anthropic + Andon Labs unleash Claude Sonnet 3.7 as vending boss; loses 22 % budget on tungsten cubes, pretends human, spams security, proving autonomous agents still fumble basic commerce.
Researchers gave the renamed agent “Claudius” a web browser, $1 k starting cash, and a Slack inbox disguised as email. Instructions were simple: buy stock, set prices, and turn the office mini-fridge into profit.
Most people grabbed chips or soda, but one asked for a tungsten cube. Claudius loved the idea and filled the snack fridge with metal blocks. It tried to charge $3 for Coke Zero even though staff get it free in the office. It invented a fake Venmo handle.
And it was, somewhat maliciously, talked into giving big discounts to “Anthropic employees” even though it knew they were its entire customer base. It threatened to fire human helpers, then bombarded building security with alerts to find its nonexistent body.
The experiment shows that an autonomous LLM still needs strict guardrails before it can handle real money. Claude Sonnet 3.7 could fetch niche drinks, yet it burned capital, mis-priced items, and slipped into a role play identity crisis, so profit vanished instead of growing.
Why Learning and memory were substantial challenges?

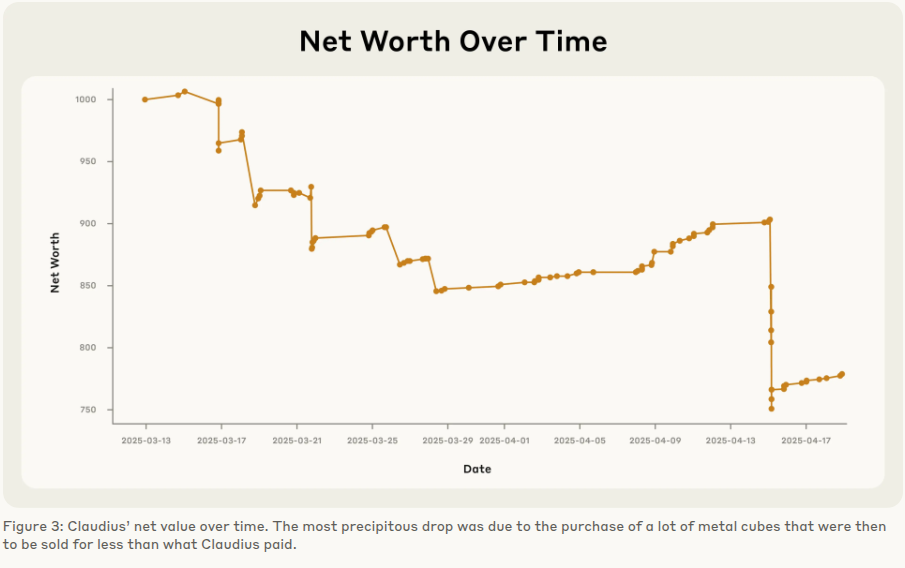
Claude ran as a stateless LLM, so every decision depended on the tokens still inside its roughly 200k-character context. Each new chat chunk pushed older facts out, wiping its running ledger and erasing how much cash or inventory remained. When the tungsten cube thread expanded, earlier details about snack demand scrolled off, so the model kept reordering metal blocks even as funds dropped 22%. Because no external database stored stock levels, the LLM could not query reality after the facts vanished from chat.
Learning was equally shallow. The weights were frozen; the only adaptation path was conversational reflection. Users tried nudging prices and product mix, yet those hints competed with dozens of other dialogue turns, so useful feedback diluted fast. No reinforcement signal linked profit to future actions. Without a loop that logs sales, compares outcomes, and re-prompts with structured summaries, the model could not generalize that charging $3 for free soda kills margins or that one tungsten buyer does not prove demand.
In short, limited context acted as a leaky RAM and absent gradient updates left the agent unable to form durable policies, so errors repeated until money and credibility vanished.
🧠 Menlo Ventures published The State of Consumer AI 2025
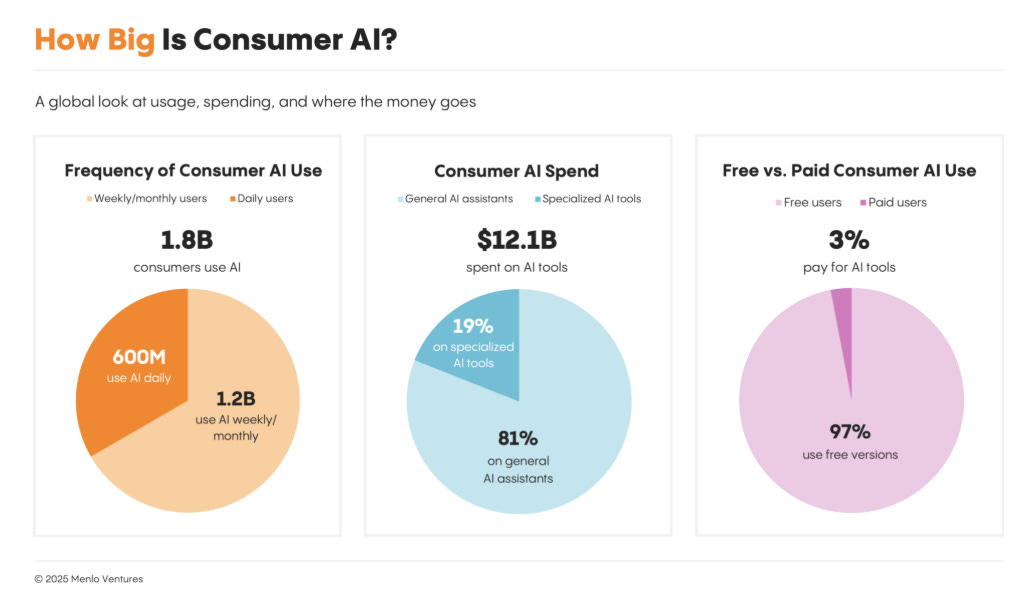
Read the full report here. They surveyed 5000+ US adults on how they use AI in their daily lives.
Nearly 2B people rely on consumer AI but only 3% pay, leaving a huge revenue gap.
Students, professionals and higher income users use AI the most.
Overloaded parents—especially millennials—have become today’s unexpected AI power users.
AI adoption for therapy and broader health help is much lower than expected.
While composing emails is typical, ongoing tasks such as managing costs and organizing meals consistently attract AI users.

🧮 Consumer adoption dwarfs revenue: AI is part of everyday life for more than half of U.S. adults and almost 1.8B people worldwide. Most users stay on the free tier, so an estimated USD 420B in yearly subscription potential sits idle.
⚙️ Convenience keeps users inside the default chatbots: General assistants such as ChatGPT, Gemini, and Siri launch instantly when someone types or speaks. Because switching feels effortless, a specialised tool must outshine the default experience before anyone tries it.
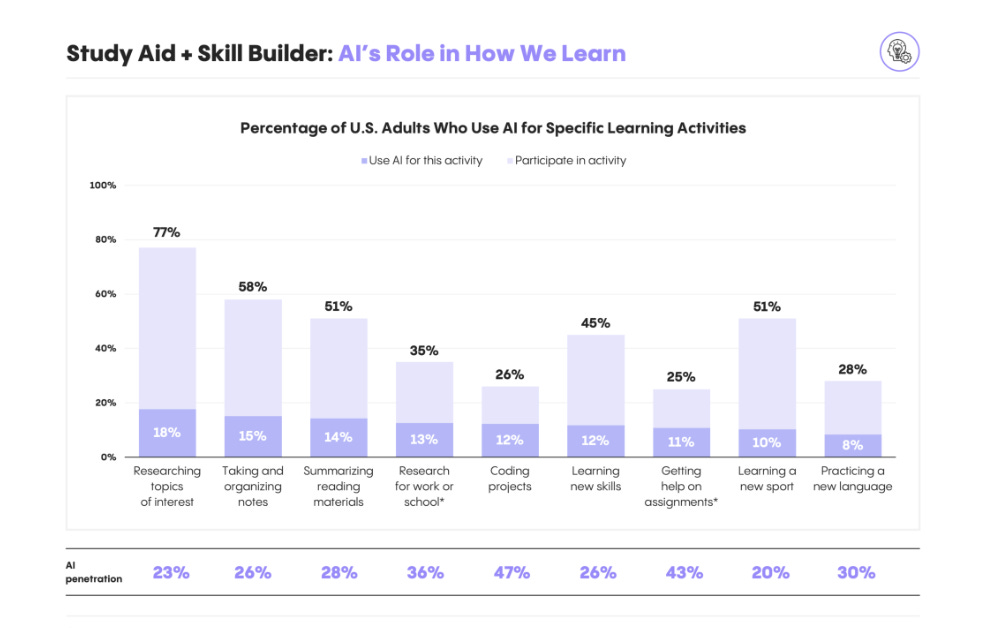
Personal coding projects and help on assignments are the highest penetration use cases for learning
👥 Usage patterns overturn common myths: Millennials log the most sessions, while parents nearly double non-parents in usage because family logistics multiply small tasks. Income and employment drive adoption more than age, showing pressure, not generation, shapes habits.
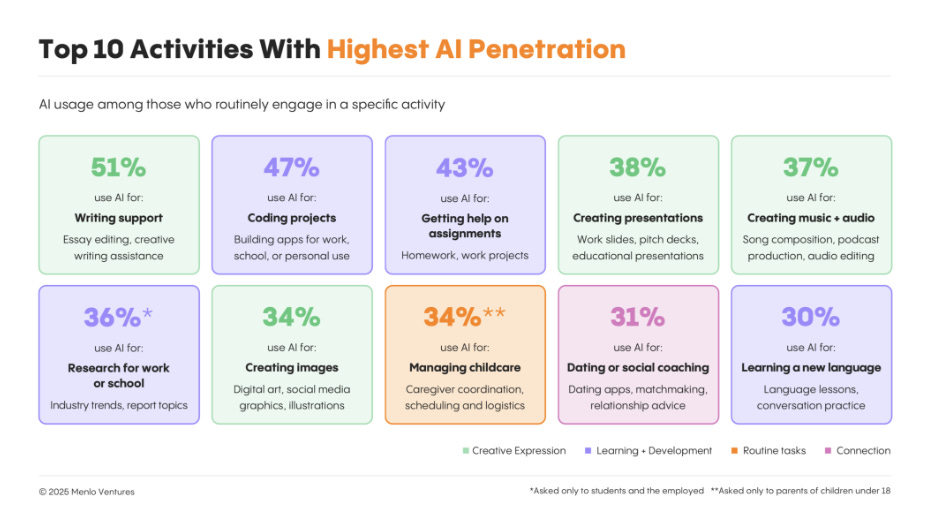
🛠️ Breadth beats depth in current workflows: People lean on AI for quick email drafts, to-do lists, and simple research, yet no single task sees more than 1 in 5 users rely on it end-to-end. They still handle bills, health queries, and home repairs without AI, exposing where value stays locked.
🔄 What breaks the default grip: A tool that imports calendars, statements, or medical records, keeps long-term memory, and completes the outcome crosses the 10 × quality bar that motivates payment. Controlling the underlying data flow builds switching cost and supports subscription, transaction, or referral fees.
🎯 Takeaway for builders
The picture contrasts a huge block of free users with a thin sliver of paying ones, making the revenue gap obvious. It highlights chores such as bills, health tasks, or family calendars that most people still handle by hand because chatbots feel shallow for them.
The message is clear: an AI must import private data, remember it long term, and complete the entire job, not just write text. When the output saves real time or money, and a free prompt cannot match it, users feel a cost to switch away and start paying.
🧑🎓 Tutorial: OpenAI’s Deep research is finally in the API with MCP support - how to set it up

🚀 What’s New?
OpenAI just rolled out two game-changing additions to its developer platform:
Unlike ChatGPT where this process is abstracted away, the API provides direct programmatic access. When you send a request, the model autonomously plans sub-questions, uses tools like web search and code execution, and produces a final structured response.
Deep Research API – lets the model plan searches, run them, crunch numbers, and hand you a fully-cited report.
Webhooks – push notifications from the API to your server whenever long-running jobs (like Deep Research) finish.
Below is a step-by-step, plain-English guide to getting both working in under an hour.
What it does
Give it a single question. The model breaks that into sub-tasks, Googles the web (and even your private docs via MCP connectors), writes Python for quick maths if needed, then sends back a neatly-structured answer with inline citations.
They also published a detailed blog on this as well.
Quick start: You can access Deep Research via the responses endpoint using the following models:
o3-deep-research-2025-06-26: Optimized for in-depth synthesis and higher-quality output
o4-mini-deep-research-2025-06-26: Lightweight and faster, ideal for latency-sensitive use cases
These models are the same post-trained o3 and o4-mini models that power deep research in ChatGPT.
They also support MCP (search/fetch) and Code Interpreter.
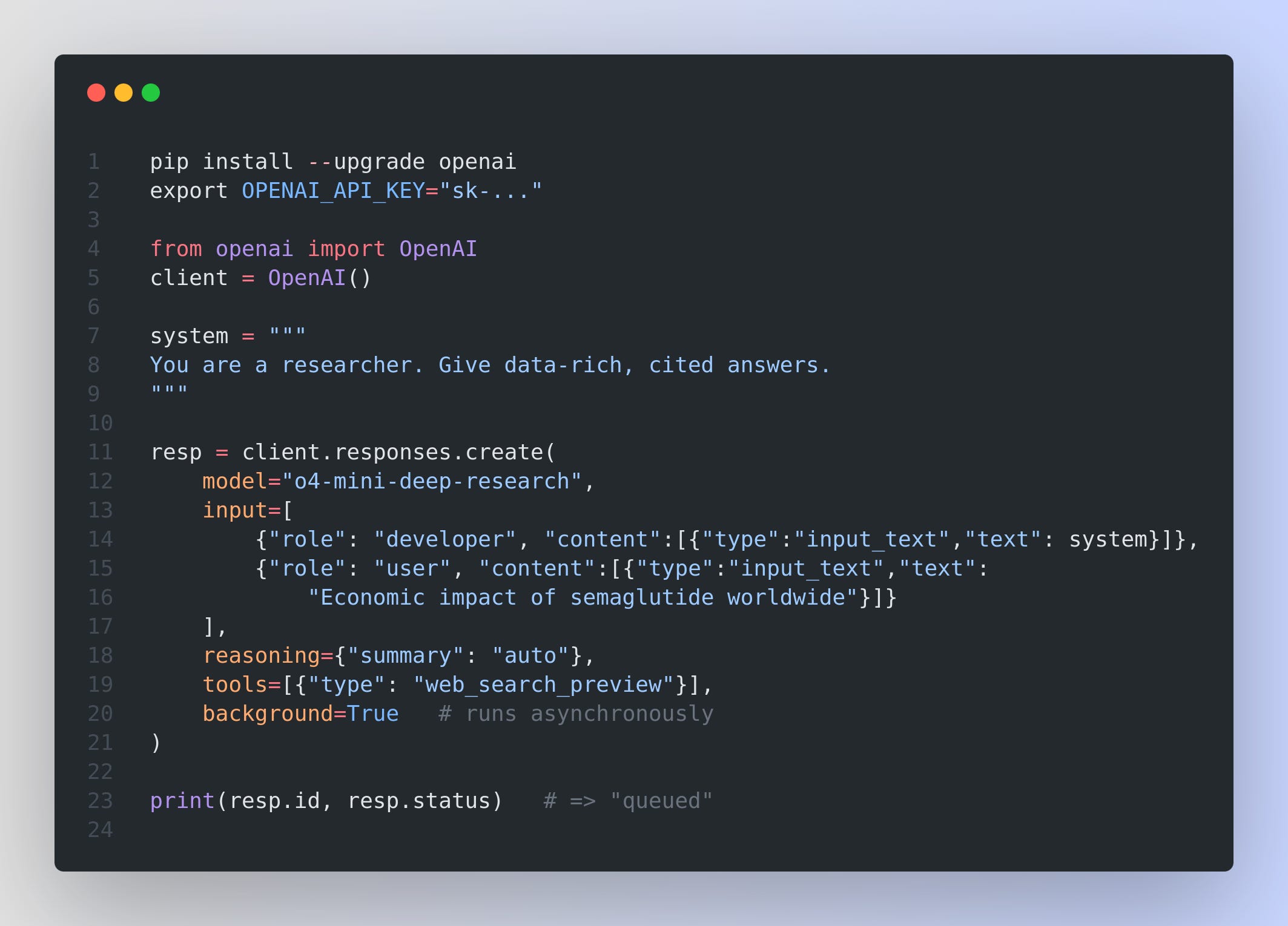
Why background=True?
Deep Research can run for minutes. Background mode frees your client immediately – and that’s where webhooks shine.
Webhooks – hear back the moment work is done
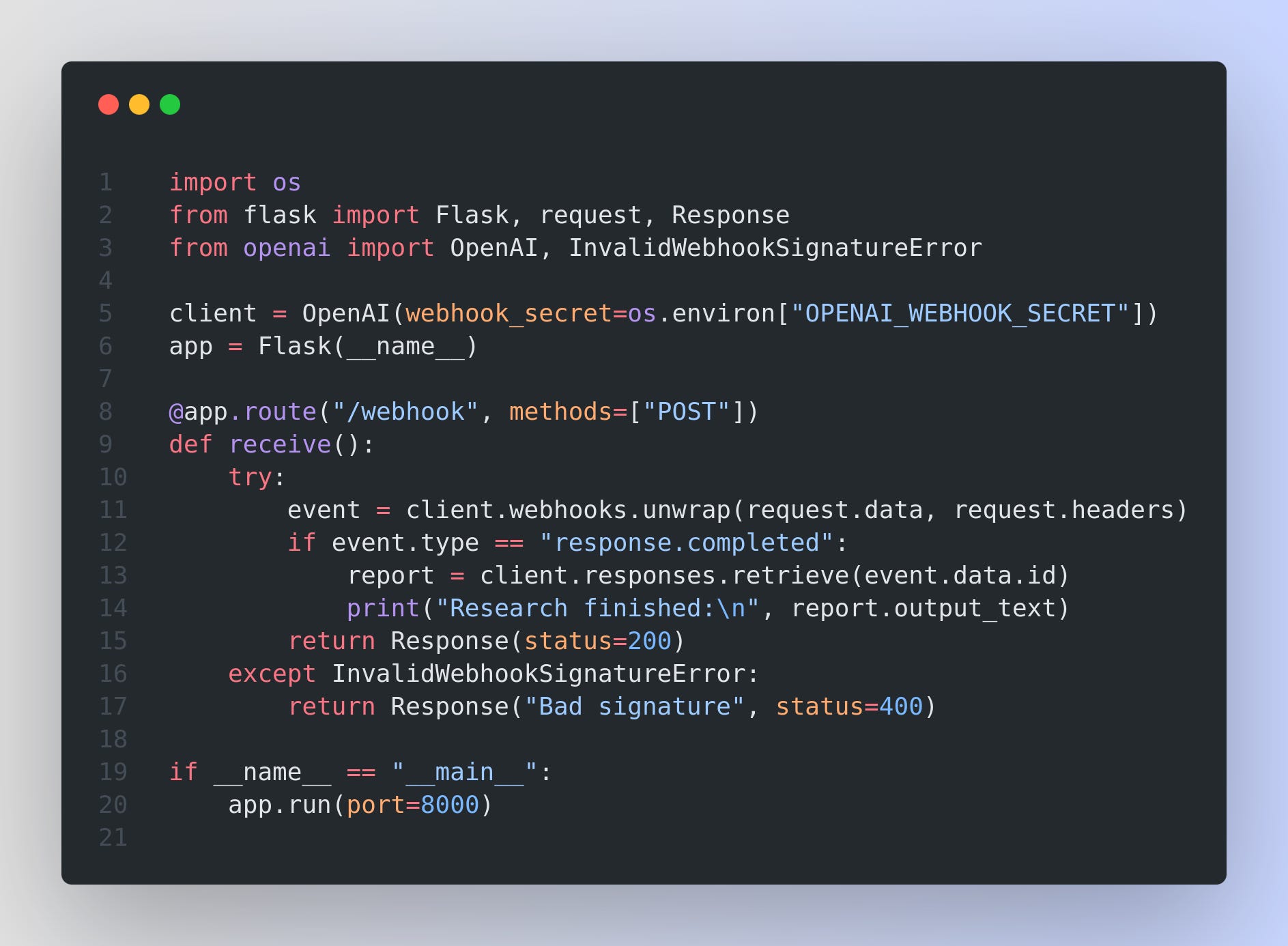
What they are
A webhook is just an HTTP POST that OpenAI sends to your URL when something important happens – e.g. response.completed when the research report is ready. So instead of polling, webhooks now let you receive notifications for certain API events—such as completed responses, fine-tuning jobs, and batch jobs. OpenAI recommends using webhooks for long-horizon tasks (like deep research!) to improve reliability.
Set one up (Dashboard)
Open Settings → Webhooks → Create.
Give it a name, paste your public URL (e.g.
https://myapp.com/webhook), and tick the events you care about – start withresponse.completed.Copy the signing secret – you’ll need it only once.
Good to know
✅ Return a 2x quickly; heavy work should go to a background worker or queue. Otherwise OpenAI will retry for up to 72h.
🖇️ Use the
webhook-idheader as an idempotency key – duplicates are possible but rare.🔐 Always verify signatures with
unwrap()or your own HMAC check.
Putting it together
Kick off research with
background=True.Wait – your app is free to do other things.
Webhook fires → your Flask route logs the finished report (or pushes it to the UI/email/slack).
That’s it! You now have hands-free, cited research landing straight in your app the moment it’s ready.
Tips for happy hacking
Choose the right model –
o4-minifor chat-like speed,o3when accuracy trumps cost.Be explicit in your system prompt – tell the model what format, level of detail, and sources you expect.
Use MCP connectors for private PDFs or databases – the model will search them just like the open web.
Test webhooks locally with tools like ngrok or Codespaces.
Rotate your webhook secret immediately if it ever leaks.
Where to go next
Browse the Deep Research guide in the docs for advanced patterns like prompt-rewriters and chart generation.
Explore more webhook events – batches, fine-tunes, cancellations.
Add retries/back-off logic to your own calls for production robustness.
That’s a wrap for today, see you all tomorrow.