
Can we use Principal Component Analysis (PCA) for feature selection (Data Science Interview Question)

Can we use PCA for feature selection
Simple ans NO, now lets go through it in detail.
PCA is a primarily a dimensionality reduction technique, but it is not explicitly used for feature selection. However, it can be useful in the preprocessing stage to aid in feature selection.
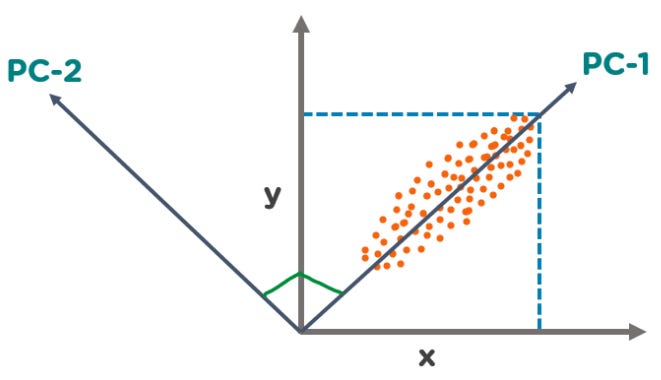
PCA works by transforming the original features into a new set of linearly uncorrelated features called principal components (PCs). These PCs are linear combinations of the original features and are ranked in order of decreasing variance, with the first principal component accounting for the largest variance in the data, the second PC accounting for the second-largest variance, and so on. By selecting a subset of these PCs, we can retain most of the variance in the data while reducing the dimensionality.
For many more of these type of discussions check out my YouTube Channel
Now, what do I mean "The principal components are linear combinations of the original features"
Suppose we have a dataset with three features - height, weight, and age.
Now, in PCA, we aim to find a new set of variables that are linear combinations of the original features.
Let's say we have two principal components - PC1 and PC2 represented by the following formula
PC1 = a1height + b1weight + c1age
PC2 = a2height + b2weight + c2age
The coefficients a1, b1, c1, a2, b2, and c2 represent the contribution of each of the original features to the principal component. These coefficients are calculated such that the variance explained by each principal component is maximized.
The principal components can be used to represent the original dataset in a lower-dimensional space. We can project the original dataset onto the principal components to obtain a new dataset with fewer dimensions. This new dataset will have the same number of samples as the original dataset but with fewer features.
Now, let's dive into the reasons why PCA is not considered a feature selection technique:
Loss of Interpretability: The principal components are linear combinations of the original features, which means that they do not retain the original feature's interpretability. As a result, it can be challenging to interpret the results from a model that uses PCs as inputs. In contrast, feature selection methods, like filter or wrapper methods, retain the original features and are more interpretable.
Principal component analysis (PCA) yields the directions that maximise the variance of the data. In other words, it projects the entire dataset into another feature sub space where the covariance between the new features is reduced to minimum - as if they are statistically independent variables. The resulting features are new features that are the orthogonal combinations of previous features. It doesn’t help much in identifying the right feature from the original dataset. PCA certainly reduces the dimensions - but not in terms of the feature vectors you initially have - but in terms of new complex feature vectors.
In this regard, note another point, if you are looking to identify which feature vector has the greatest correlation with the target value at hand, XGBoost package (i.e a tree based method) has feature selection module called “plot_importance” which can give you exactly that. It ranks your columns in the order of feature importance correlation to the target variable.
Linearity: PCA is a linear technique, which means it assumes a linear relationship between the original features. This assumption may not hold for all datasets. Feature selection techniques do not make such assumptions and can be used with linear or non-linear models.
However, PCA can be useful in the preprocessing stage before feature selection for the following reasons:
Noise Reduction: PCA can help remove noise from the dataset by capturing the most significant variance in the data while discarding the low-variance components, which may represent noise.
Correlation Reduction: PCA transforms the original features into a new set of linearly uncorrelated features. This transformation can help with feature selection methods sensitive to multicollinearity, such as LASSO or Ridge regression.
When using PCA in the preprocessing stage to help in the feature selection
The basic idea when using PCA as a tool for feature selection is to select variables according to the magnitude (from largest to smallest in absolute values) of their coefficients
How do the PCs relate to features? Each PC is a linear combination of the original features. The coefficients of the linear combination indicate the importance of each feature in that PC. Features with high coefficients are more important for that PC.
By examining the coefficients of the PCs we keep, we can determine which of the original features are most significant for those PCs. Hence, we have performed a kind of semi-feature selection. We have identified the most important features that contribute most to the major trends in the data as encapsulated by the principal components.
In summary, PCA is not considered a feature selection technique, as it creates linear combinations of the original features, leading to a loss of interpretability and assumption of linearity. However, it can be a useful preprocessing step to reduce noise and multicollinearity in the data, thereby aiding the feature selection process.
For many more of these type of discussions check out my YouTube Channel