
🗞️ Central bankers now fear the AI gold rush could seed the next major financial shock.
AI gold-rush financial shock, gray-market Claude API tokens, Sakana Fugu report, ultra-cheap Chinese AI models, DeepSeek inference optimization, Meta noninvasive brain-to-text at 78% accuracy

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-June-2026):
🗞️ Central bankers now fear the AI gold rush could seed the next major financial shock.
🗞️ A crazy blog, Chinese developers are buying Claude access through gray-market API transfer stations that can sell tokens at 5% to 10% of official prices while hiding the real user from Anthropic.
🗞️ Sakana Fugu Technical Report
🗞️ Chinese AI models are up to 50 times cheaper than their American counterparts on a per-token basis.
🗞️ Deepseek AI published their new inference optimization method.
🗞️ Meta just open-sourced a brain-to-text system that reaches 78% word accuracy without surgery.
🗞️ Central bankers now fear the AI gold rush could seed the next major financial shock.
Bank for International Settlements (BIS) just issued one of its sharpest warnings yet about debt building behind the AI boom.
The danger is not AI itself; the danger is building a leveraged supply chain around revenue that has not yet proved durable. The risk is that if AI demand disappoints, data-center spending could slow, borrowers could struggle to repay, and stress could spread from tech into credit markets.
AI demand pushed hyperscalers to spend heavily on chips, data centers, and power capacity, and that spending supported growth, trade, and easy financial conditions while equity investors priced in years of high earnings growth. Debt changed the shape of the boom because hyperscaler bond issuance topped $100B in 2025, while off-balance sheet vehicles shifted data-center obligations toward private credit funds, insurers, and other non-bank lenders.
Circular financing adds another weak point because chipmakers, hyperscalers, AI labs, and compute providers can fund each other while also booking future sales from each other, which can make real demand harder to read. A capex slowdown could hit suppliers first, then credit markets, then households, because US stocks make up about 64% of the MSCI Global index and household equity exposure is higher than in past cycles.
Private credit raises the systemic risk because direct lenders have quadrupled AI and IT exposure in 5 years to about 15% of portfolios, while some retail-facing funds already face redemption pressure. AI can still deliver real productivity gains, but the financing stack now assumes that delivery arrives fast enough to support huge fixed costs.
BIS is warning that an AI-driven market selloff could quickly spill into credit, because stock losses and credit spreads have moved together in past stress episodes like 2008 and 2020.

Private credit has also become a bigger lender to smaller firms, and software borrowers are increasingly tied to multiple lenders, so an AI shock could spread through a less transparent credit system.
US imports of AI-enabling products from Asia have surged, while China’s share collapsed and supply shifted toward ASEAN, Taiwan, and Korea.

That supports the BIS point that the AI boom is tied to a huge hardware supply chain, so any shock to chips, power, trade routes, or financing can spread beyond tech stocks.
AI-related capex has exploded from a few hundred billion dollars in 2021 to a projected roughly $800B in 2026, with US hyperscalers driving most of the increase.

BIS is warning that this spending boom supports growth now, but it also creates crash risk if AI revenues fail to justify the buildout.
🗞️ A crazy blog, Chinese developers are buying Claude access through gray-market API transfer stations that can sell tokens at 5% to 10% of official prices while hiding the real user from Anthropic.

A transfer station is a middle server that takes a user’s prompt, sends it to Claude through overseas accounts, returns the answer, and collects payment through WeChat or Alipay.
The transfer station collects many Claude accounts through free credits, discounted accounts, shared subscriptions, overseas payment workarounds, fake verification, or sometimes stolen-card accounts. It connects all those accounts behind one proxy, so Chinese users do not talk to Anthropic directly and only pay the proxy in RMB.
The cheap price comes from account farming, free-credit abuse, resale of unused quota, subscription splitting, possible stolen cards, and a darker trade where user prompts and outputs become training data. So the price hugely cheap not because Anthropic is giving a discount; it is cheap because the transfer station lowers its own cost and creates extra hidden revenue.
The user thinks they are buying cheap inference, but the proxy may swap Opus for weaker models, inflate token use, or store private code, tool calls, reasoning traces, and business data. The proxy may store user prompts, code, outputs, and tool traces, then sell or reuse that data for model training.
This breaks a core assumption behind KYC, account bans, and abuse monitoring: the AI company sees the proxy, not the real person, so banning one account leaves the upstream supply chain alive.
🗞️ Sakana Fugu Technical Report

The idea is that intelligence is moving from the model to the system around it.
Fugu is an orchestrator reads the task, chooses which specialist model to use, and in the Ultra version can build small workflows where models critique, extend, or correct one another. Most multi-model systems use simple rules, like ask 3 models and vote, or always send coding to 1 model and math to another. Fugu is different because the manager is trained from data to learn which model is actually best for each kind of situation, including small details like “this looks like coding, but the hard part is debugging, so bring in the model that is better at debugging.”
The mechanism has 2 versions.
Regular Fugu is the fast version, where it reads the user’s request and quickly chooses 1 worker model from a pool, so the user experiences it like calling 1 model, but behind the scenes Fugu picked the model it thinks is best for that exact request. Fugu-Ultra is the slower but stronger version, where it can create a small workflow, such as asking 1 model to solve, another model to check, another model to solve from a different angle, and then choosing the best model to combine the answers.
The special part is that the workflow is not fixed before the task starts, because Fugu-Ultra can design a different teamwork pattern for each question.
The picture shows regular Fugu’s fast routing mechanism: it reads the user request, but does not answer it itself.

The key part is the “lightweight head,” a small extra decision layer attached to the language model. That layer looks at the model’s hidden state, meaning its internal summary of what the request is about.
Then it gives one score to each available worker model, and the highest score decides which outside LLM gets the task. The red diagonal marks a small tuning trick, where they adjust only a tiny part of the model’s internal weights so it gets better at choosing the right worker.
🗞️ JP Morgan Research: Chinese AI models are up to 50 times cheaper than their American counterparts on a per-token basis.

Especially Qwen, DeepSeek and Kimi, which pressures OpenAI and Anthropic pricing.
- From J.P. Morgan report titled "Semiquincententacles: the US grip on global markets at 250" found that
The report said Chinese firms accounted for over 45% of all traffic on the AI aggregation platform OpenRouter by April 2026, up from under 2%in late 2024.
Some other findings from the report.
- Enterprise AI tokens may become commoditized, because many business tasks do not need frontier models and can run on smaller open models.
- AI has driven 65%-80% of S&P 500 returns, profits and capex since ChatGPT, creating clear signs of investor overexcitement in semiconductors.
- NVIDIA still dominates AI accelerators, but custom chips from Google, Amazon, Microsoft and Meta are gaining because they can cut total cost by 30%-40%.
- China is catching up in AI, with better models, rising GPU self-sufficiency and possible chip-scaling workarounds despite export controls.
- Taiwan is the US AI system’s weak point, because TSMC supports much of the world’s advanced chip supply while Taiwan is highly exposed to energy and food blockades.
JPMorgan Asset Management strategist Michael Cembalest noted in the report that China is leveraging low-cost open-source strategies to accelerate AI adoption globally. By late February 2026, Chinese models processed roughly 5.3 trillion out of 8.7 trillion tokens consumed by the top 10 models on OpenRouter, with MiniMax, Moonshot AI, and Zhipu AI holding the top 3 spots.
🗞️ Deepseek AI published their new inference optimization method.

Proposes DSpark, a semi-parallel speculative decoding system that gave DeepSeek-V4 about 60% to 85% faster per-user generation at matched throughput.
The biggest idea in DSpark is that faster inference is not just about drafting more tokens, but about deciding which drafted tokens are worth checking. Speculative decoding already had the basic trick: a smaller draft model guesses several next tokens, then the real model checks them in 1 pass.
The problem is that long draft blocks often waste work, because later guesses are more likely to be wrong, and checking bad guesses still uses GPU capacity. DSpark’s breakthrough is to make this process selective: it drafts a block, scores how likely each prefix is to survive, then verifies only the part that is likely to pay off.
The mechanism has 2 linked parts: a strong parallel draft model makes many token guesses quickly, then a tiny Markov head adjusts each guess using the token right before it.
That small sequential piece matters because pure parallel drafting are fast, but their later tokens decay because each position guesses without knowing what the earlier sampled token actually was.
i.e. Fully parallel drafters guesses every position too independently, which can create bad token combinations later in the block. Then the confidence scheduler estimates how many drafted tokens should be checked for each request, based on both acceptance chance and current GPU load.
DSpark is a guess-and-check loop where the real model first creates token D, then DSpark uses D to guess E, F, G, and H quickly.

The parallel block makes the guesses fast, while the small sequential block fixes the main weakness of parallel drafting by letting each guess know a little about the previous one. The scheduler is the key system idea: it does not verify every guessed token, it keeps only the prefix that looks worth the GPU cost.
Here it keeps E, F, and G, drops risky H, then the real model accepts E and F but rejects G and replaces it with G*. So the main point is that DSpark speeds up inference by combining faster guesses, slightly smarter guesses, and selective checking instead of blindly checking a fixed draft length.
🗞️ Meta just open-sourced a brain-to-text system that reaches 78% word accuracy without surgery.
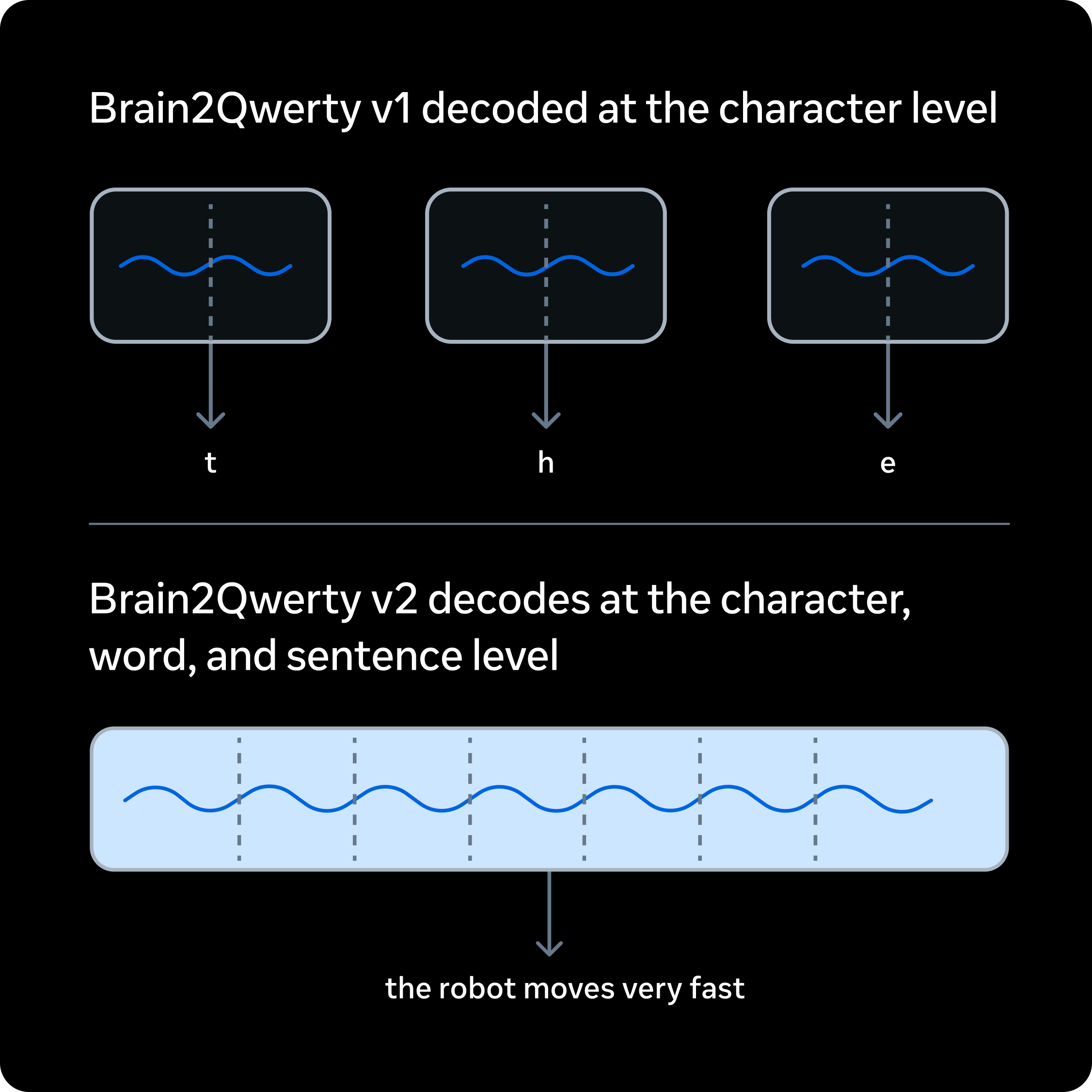
The system reads MEG signals from a helmet, not electrodes placed inside brain tissue. 9 volunteers typed about 22,000 sentences while researchers recorded 10 hours of neural activity each.
Brain2Qwerty v1 mostly mapped brain signals to single typed characters. It tries to recover characters, words, and full sentence meaning together. The system studies those brain signals and tries to turn them into the words you wanted to type.
61% average word accuracy across all participants
78% word accuracy for the top participant
50%+ of sentences decoded with no more than 1 word error
Performance improves as the data pile grows
Raw brain signals are messy because many mental and physical processes fire at once. Deep learning handles that mess by learning patterns directly from the original recordings.
A fine-tuned LLM then uses language context to repair likely word and sentence errors. This explains why the system beats earlier non-invasive methods reporting 8% word accuracy.
More than half of sentences from the strongest participant had one word error or less. Accuracy also improved as training data grew, suggesting more recordings may close more of the gap.
That’s a wrap for today, see you all tomorrow.