
ChatGPT Now Understands Real-Time Video with Advanced Voice Mode"
ChatGPT video analysis, Meta's reasoning paper, Google's Trillium TPUs, and Cerebras CePO framework advancing LLMs and many more..

Reading Time: 7 minutes and 12 seconds
⚡In today’s Edition (12-Dec-2024):
🎥 ChatGPT adds real-time video analysis to voice mode for visual understanding
🏆 Meta realeased a brilliant paper having the potential to significantly boost LLM's reasoning power.
📡Google Cloud launched Trillium TPUs, with 4x faster AI training and 3x better inference throughput, powering Gemini 2.0
🛠️ Cerebras introduces CePO – a test time reasoning framework for Llama, and Llama3.3-70B + CePO outperforms Llama 3.1 405B and approaches GPT-4 & Sonnet 3.5
=================================
🗞️ Byte-Size Brief:
WebDev Arena launches open-source AI code testing platform with community rankings
Penn State unveils VisOnlyQA dataset showing 41% AI-human accuracy gap
=========================================
🤖 Top HuggingFace Models of the week
🎥 ChatGPT adds real-time video analysis to voice mode for visual understanding
🎯 The Brief
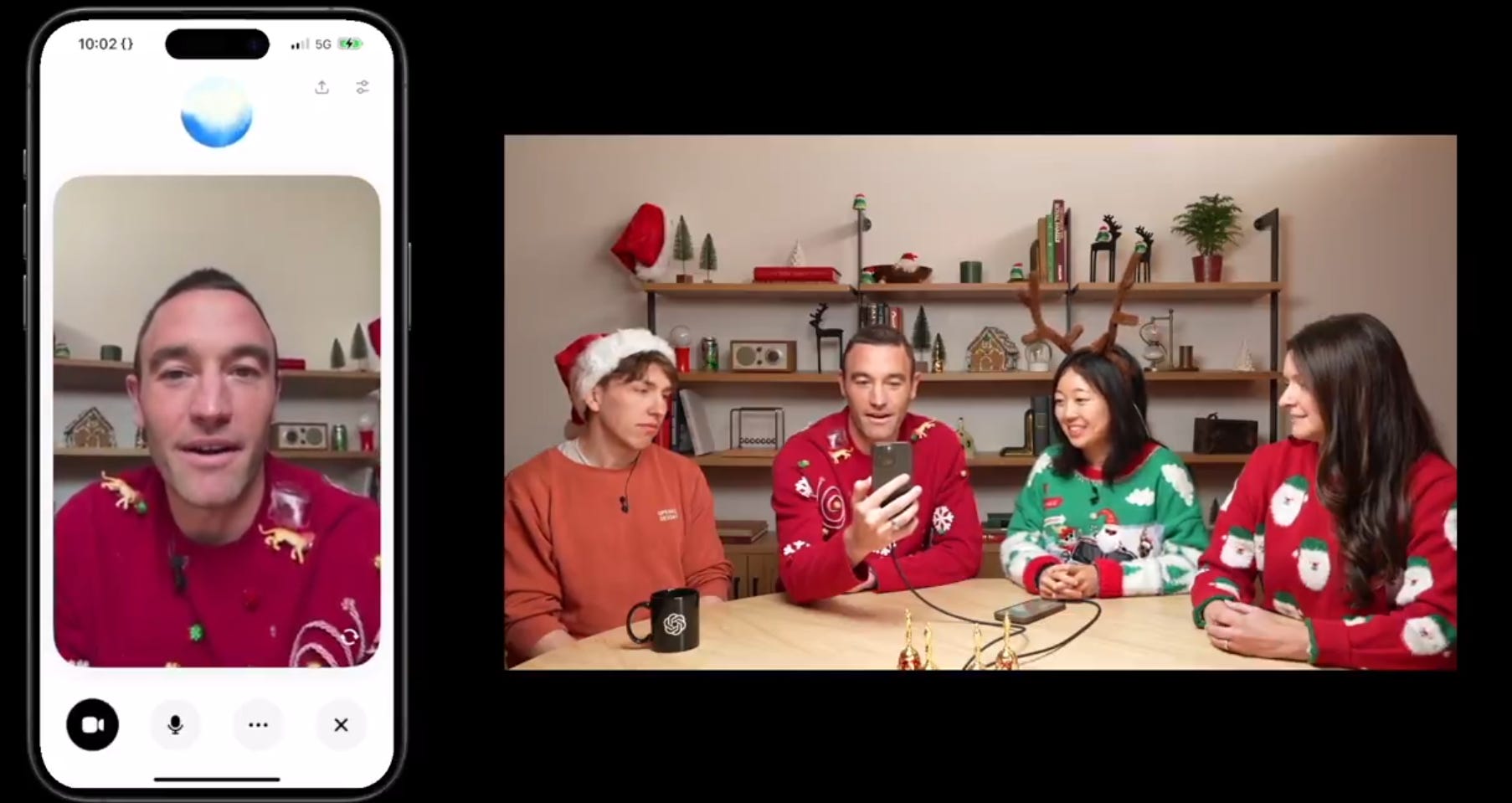
OpenAI releases real-time video capabilities in Advanced Voice Mode for ChatGPT, enabling visual analysis and screen sharing for Plus, Team, and Pro subscribers.
⚙️ The Details
→ The new feature allows users to point phones at objects for real-time visual analysis through ChatGPT. Screen sharing functionality enables ChatGPT to interpret device settings and assist with problems like math equations.
→ Access is restricted to to ChatGPT Plus, Team, or Pro for now. Enterprise and Edu subscribers (to ChatGPT Plus, Team, or Pro for now ) must wait until January. The feature is not available in EU, Switzerland, Iceland, Norway, and Liechtenstein.
→ Implementation requires tapping the voice icon near chat bar, followed by video icon for camera activation. Screen sharing is accessed through the three-dot menu.
→ Early testing revealed potential limitations, with ChatGPT showing accuracy in anatomical recognition but experiencing hallucinations with geometry problems.
→ In addition to Advance Voice Mode with vision, OpenAI on Thursday launched a festive “Santa Mode,” which adds Santa’s voice as a preset voice in ChatGPT. Users can find it by tapping or clicking the snowflake icon in the ChatGPT app next to the prompt bar.
⚡ The Impact
Competes directly with Google's Project Astra (released yesterday), advancing real-time AI visual analysis capabilities in conversational AI.
🏆 Meta realeased a brilliant paper having the potential to significantly boost LLM's reasoning power.

🎯 The Brief
Meta introduced Coconut (Chain of Continuous Thought), enabling LLMs to reason in continuous neural space without converting to language tokens, achieving 34.1% accuracy on GSM8k math problems versus 30% baseline.
⚙️ The Details
→ Coconut bypasses traditional language token generation, allowing LLMs to maintain thoughts in raw neural form between reasoning steps using special <bot> and <eot> tokens. The model preserves multiple reasoning paths simultaneously with associated probabilities.
So basically the paper propose not to force AI model to explain in English when it can think directly in neural patterns.
→Imagine if your brain could skip words and share thoughts directly - that's what this paper achieves for AI. By skipping the word-generation step, LLMs can explore multiple reasoning paths simultaneously.
→ Training uses progressive curriculum stages, starting with language-based Chain-of-Thought and gradually replacing steps with continuous thoughts. Performance shows 97% accuracy on logical reasoning tasks (ProsQA).
→ The continuous space enables parallel path exploration, similar to breadth-first search. Model can probe and interpret continuous thoughts, showing probabilities for different reasoning paths while maintaining ability to generate explanations when needed.
⚡ The Impact
Direct neural reasoning enhances LLM performance while preserving explainability and reducing computational overhead in complex tasks.
📡Google Cloud launched Trillium TPUs, with 4x faster AI training and 3x better inference throughput, powering Gemini 2.0
🎯 The Brief
Google Cloud announces Trillium, their 6th-gen TPU, delivering 4x faster training and 3x higher inference throughput than previous generation TPUs, enabling massive-scale AI model training and inference.
⚙️ The Details
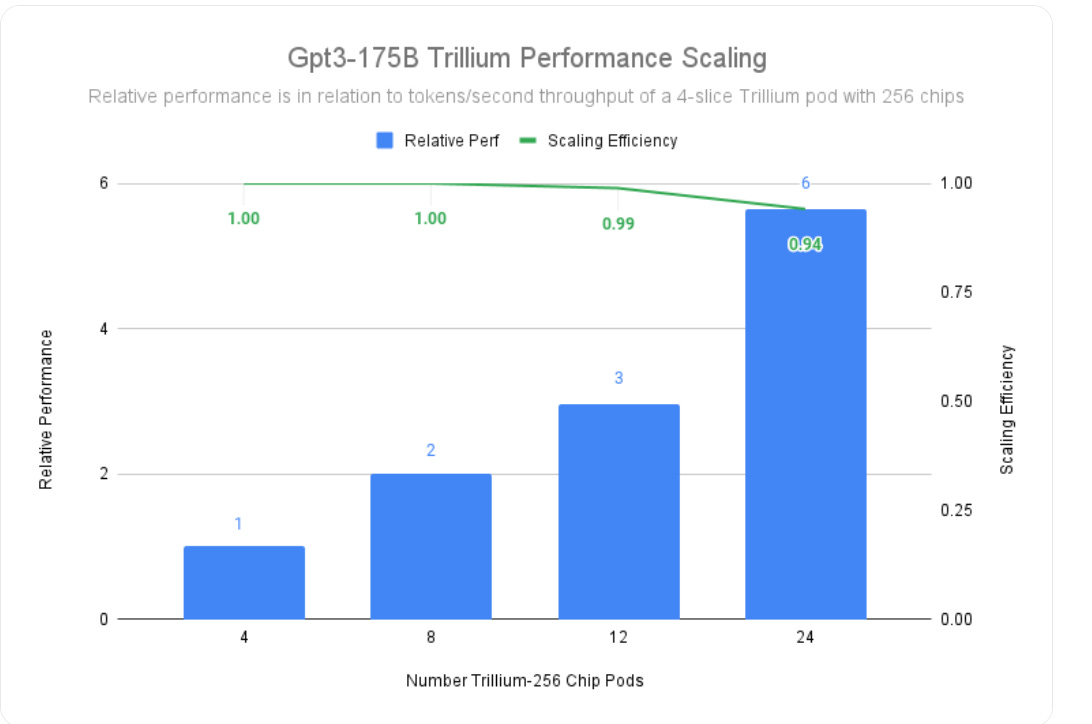
→ Trillium achieves 99% scaling efficiency with 12 pods (3072 chips) and 94% efficiency across 24 pods (6144 chips) for training gpt3-175b models. The system maintains exceptional performance through a 13 Petabits/sec bisectional bandwidth network.
→ For inference workloads, Trillium demonstrates 3.1x higher throughput for offline and 2.9x higher throughput for server inference on Stable Diffusion XL. Cost efficiency shows 27% reduction for offline and 22% reduction for server inference compared to TPU v5e.
→ The third-generation SparseCore technology delivers 2x improvement in embedding-intensive model performance and 5x improvement in DLRM DCNv2 performance, optimizing dynamic operations like scatter-gather and sparse segment operations.
⚡ The Impact
Trillium enables faster, more cost-effective AI model training and inference at unprecedented scale.
🛠️ Cerebras introduces CePO – a test time reasoning framework for Llama, and Llama3.3-70B + CePO outperforms Llama 3.1 405B and approaches GPT-4 & Sonnet 3.5
🎯 The Brief
Cerebras introduced CePO framework that enables Llama 3.3-70B to outperform Llama-405B on complex reasoning tasks with 100 tokens/second performance.
⚙️ The Details
→ CePO framework leverages three key insights: step-by-step reasoning, comparison-based verification, and structured output formats. The system employs a 4-stage pipeline for enhanced problem-solving.
🎯 Architecture
→ CePO breaks down complex problems into simple steps that the model can execute with high confidence
→ Instead of self-verification, it uses solution comparison to identify inconsistencies between multiple generated answers
→ The pipeline has four stages: plan generation, plan execution, result verification, and best response selection
Performance metrics
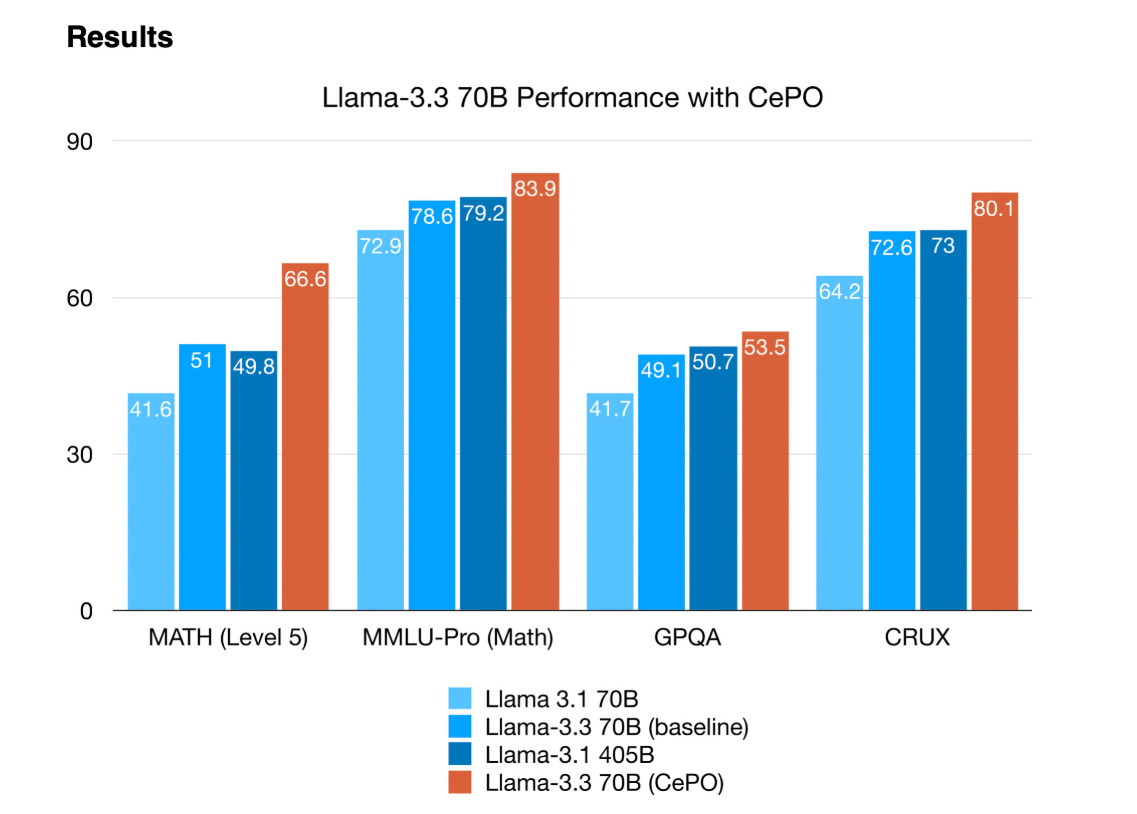
→ Performance metrics show significant gains: 83.9% on MMLU-Pro Math, 53.5% on GPQA, and 80.1% on CRUX. CePO surpasses traditional prompting methods like CoT with Reflection and Self-Consistency.
→ While consuming 10-20x more inference tokens than one-shot approaches, CePO maintains interactive speeds on Cerebras hardware, matching performance with GPT-4 Turbo and Claude 3.5 Sonnet.
⚡ The Impact
Test-time computation techniques boost LLM reasoning abilities without model retraining, democratizing advanced AI capabilities.
🗞️ Byte-Size Brief
WebDev Arena creates an interactive platform where developers can compare different AI models' coding abilities, contribute to performance rankings, and access the entire codebase freely.
Penn State researchers built VisOnlyQA to test if AI models can accurately read geometric shapes and numbers in scientific figures. The VisOnlyQA dataset tests AI's ability to perceive basic visual information in scientific figures, revealing significant gaps between human accuracy (95%) and AI performance (54%) on simple geometric tasks.
🤖 Top HuggingFace Models of the week
🤗 New linear models: QRWKV6-32B (RWKV6 based on Qwen2.5-32B)
🚀 Recursal AI converted Qwen 32B Instruct model into QRWKV6 architecture, replacing transformer attention with RWKV-V6 attention through a novel conversion process.
The model matches original 32B performance while delivering 1000x compute efficiency in inference.
→ Training completed in 8 hours using 16 AMD MI300X GPUs (192GB VRAM each). Currently working on Q-RWKV-6 72B, RWKV-7 32B and LLaMA-RWKV-7 70B variants.
→ The Linear attention mechanism proves highly efficient at scale, especially for long context processing
🔍 Key Highlights:
→ The conversion process enables transforming any QKV Attention model into RWKV variant without full retraining, significantly reducing compute costs
→ Model inherits language limitations from parent Qwen model, supporting ~30 languages versus RWKV's typical 100+ languages
→ Current context length limited to 16k due to compute constraints, though model shows stability beyond this window
→ Retains parent model's feedforward network architecture, creating incompatibility with existing RWKV inference code
🤗 xLSTM-7B
This xLSTM-7B was pre-trained on the DCLM and selected high-quality data for in a total of approx. 2.3 T tokens using the xlstm-jax framework.
The xLSTM paper released earlier this year, presented improvements to Long Short-Term Memory (LSTM) networks to make them competitive with modern Transformer architectures.
It extended LSTM with exponential gating and novel memory structures to enable better revision of storage decisions and increased memory capacity.
To use NX-AI/xLSTM-7b, first, install xlstm, which now uses the mlstm_kernels package for triton kernels. Then follow the model page guide.
pip install xlstm
pip install mlstm_kernels🤗 OpenGVLab/InternVL2_5-78B
→ The first open-source multimodal large language model (MLLM) to achieve >70% on MMMU, with 70.1% validation and 61.8% test scores, rivaling GPT-4o and Claude 3.5.
→ Uses a progressive scaling strategy that trains vision encoder first with smaller LLMs (20B) before scaling to larger ones (72B), reducing compute costs while maintaining performance.
→ Implements random JPEG compression (quality 75-100) and square averaging loss to handle real-world image degradation and balance gradient biases.
→ Features sizes from 1B to 78B parameters with the largest model using a 6B vision encoder and 72B LLM. Vision encoder trained on diverse data including multilingual OCR and mathematical charts.
→ Strong performance across benchmarks: 72.3% on MathVista, 95.1% on DocVQA, and 88.3% on MMBench-EN, demonstrating robust capabilities in specialized domains.
🤗 TRELLIS
TRELLIS is a breakthrough 3D generative model that enables high-quality 3D asset creation from text or images. It uses a novel Structured LATent (SLAT) representation that combines sparse 3D grid structures with dense multiview visual features to capture both geometry and appearance.
Key aspects: → Built using rectified flow transformers with 2B parameters trained on 500K diverse 3D objects
→ Supports multiple output formats including Radiance Fields, 3D Gaussians, and meshes through flexible decoding from the unified SLAT representation
→ Features powerful local editing capabilities allowing targeted modifications to specific regions of 3D assets
→ Demonstrates superior visual quality compared to existing methods at similar scale
→ Employs a two-stage pipeline: first generates sparse structure, then generates latent vectors for non-empty cells
🤗 TRELLISHunyuanVideo
It helps you generate high-quality videos from text or images.
→ HunyuanVideo features a 13B parameter architecture making it the largest open-source video generation model, with performance matching or exceeding closed-source alternatives.
→ The model uses a unique dual-stream to single-stream Transformer design - processing video and text tokens separately before fusing them for multimodal integration.
→ It leverages a decoder-only MLLM as text encoder instead of CLIP/T5, enhancing instruction following and visual-semantic alignment through zero-shot learning capabilities.
→ The architecture employs a 3D VAE with CausalConv3D achieving compression ratios of 4x temporal, 8x spatial and 16x channel dimensions for efficient training.
→ In human evaluations against models like Runway Gen-3 and Luma 1.6, HunyuanVideo achieved superior scores: 61.8% text alignment, 66.5% motion quality, 95.7% visual quality.