
🚨 China’S Biggest Public AI Drop Since Deepseek, Baidu Open Sources Ernie, Beats Deepseek
Baidu open-sources Ernie, leapfrogging Deepseek, Microsoft’s Diagnostic Orchestrator tops 21 physicians at 85.5% accuracy, and Zuckerberg consolidates Meta’s AI forces into new Superintelligence Lab.
Read time: 7 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Jun-2025):
🚨 China’S Biggest Public AI Drop Since Deepseek Baidu Open Sources Ernie, Beats Deepseek
🏆 Microsoft claims its AI Diagnostic Orchestrator outperformed 21 doctors, got 85.5% of diagnoses right
🗞️ Byte-Size Briefs:
Mark Zuckerberg announces creation of Meta Superintelligence Labs. He folded every research, infrastructure, and product AI team into Meta Superintelligence Labs, or MSL.
🚨 China’S Biggest Public AI Drop Since Deepseek Baidu Open Sources Ernie, Beats Deepseek

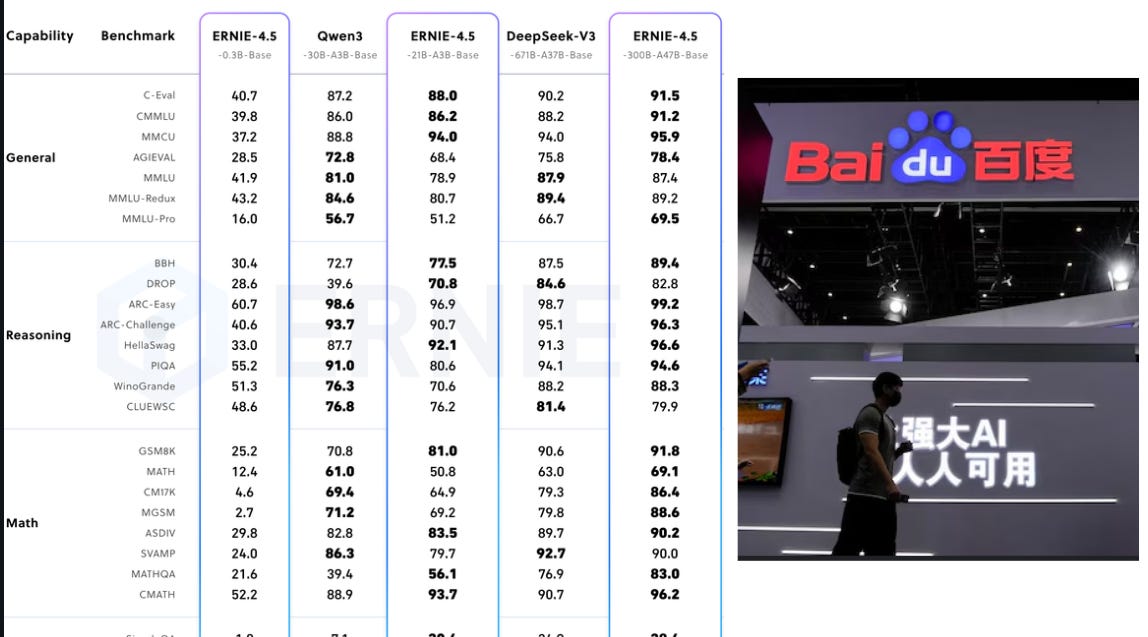
Baidu open source Ernie, 10 multimodal MoE variants
🔥 Surpasses DeepSeek-V3-671B-A37B-Base on 22 out of 28 benchmarks
🔓 All weights and code released under the commercially friendly Apache 2.0 license (available on huggingface) thinking mode and non-thinking modes available. Context Length of 131K tokens.
📊 The smaller ERNIE-4.5-21B-A3B-Base model, with approximately 70% of the parameters of Qwen3-30B, outperforms it on several math and reasoning benchmarks.
🧩 10 released variants range from 0.3B dense to 424B total parameters. Only 47B or 3B stay active params, thanks to mixture-of-experts routing.
🖼️ Vision-language versions add thinking and non-thinking modes, topping MathVista, MMMU and document-chart tasks while keeping strong perception skills
Architecture (See their very detailed Technical Report) :
A heterogeneous MoE layout sends text and image tokens to separate expert pools while shared experts learn cross-modal links, so the two media strengthen rather than hinder each other
The team shapes training around a new hybrid parallel plan that spreads different jobs across chips while a load balancer stops any node from sitting idle.
Inside each node, several experts run side by side, and a tight pipeline sends micro-batches forward without piling up activations. FP8 arithmetic and selective recomputation halve memory traffic and push pre-training speed sharply higher.
During inference the system lets multiple expert shards talk in parallel, then packs their weights into 4-bit or 2-bit blocks with a convolutional code trick that keeps outputs unchanged.
It also splits parameter storage from execution roles and swaps them on demand so every device stays useful, which raises throughput for mixture-of-experts models.
All of this sits on PaddlePaddle and keeps fast inference across many hardware types without special tuning.
Availability
Here’s the simples script to run it on your own machine.
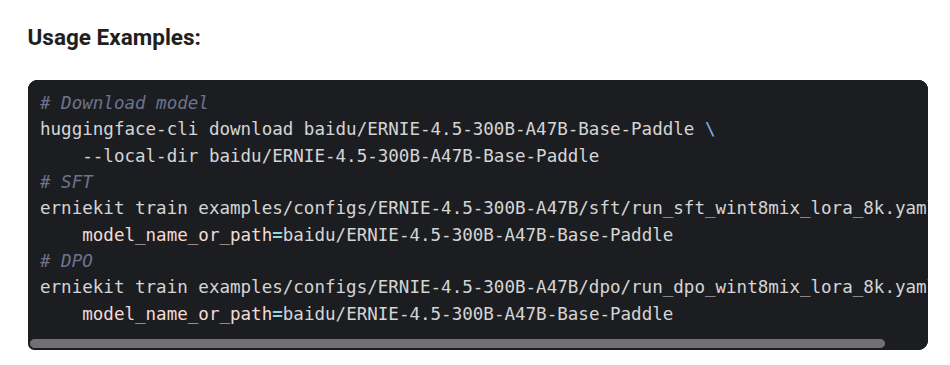
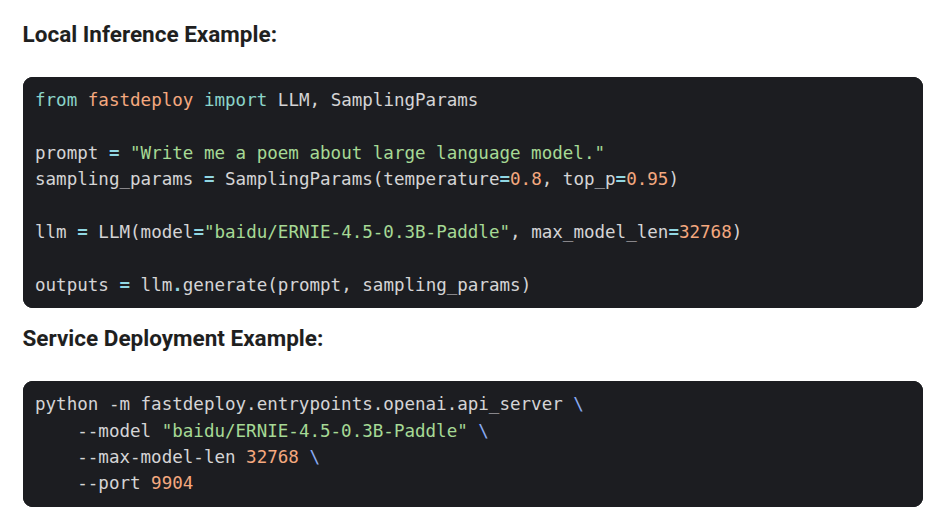
For more detailed examples, please refer to ERNIEKit repository.
The an open source Ernie potentially could be even more disruptive to both U.S. and Chinese competitors when it comes to the price equation.
🏆 Microsoft claims its AI Diagnostic Orchestrator outperformed 21 doctors, got 85.5% of diagnoses right

Microsoft’s new MAI-DxO (Microsoft AI Diagnostic Orchestrator ) AI orchestrator solves 85% of the toughest New England Journal of Medicine (NEJM) cases while ordering fewer tests, showing language-model teams can out-reason individual physicians. 💡
These cases are known for being particularly complex and usually involve teams of specialists.
MAI-DxO is a model-agnostic orchestrator that simulates a panel of virtual physicians. “MAI-DxO represents a new frontier in AI-driven clinical reasoning,” the Microsoft AI team said in a blog post. “By orchestrating the strengths of multiple large language models, we can emulate a virtual panel of physicians that collaborate to reach accurate diagnoses with efficiency and transparency.”
The orchestrator, which integrates models such as GPT, Claude, and Gemini, also offers configurable cost constraints, allowing it to balance diagnostic thoroughness with cost-effective care—an increasingly important metric as U.S. health spending nears 20% of GDP.
How exaclty the orchestrator work?
Think of MAI-DxO as a control layer that sits on top of any large language model such as GPT-4o, Claude-Opus, or Gemini-Ultra.
The layer spins up five specialist copies of the chosen model, naming them Hypothesis, Challenger, Test-Chooser, Checklist, and Stewardship agents. The specialists act like a discussion panel. Each one reads the same patient vignette, proposes a next step, and explains the reasoning behind that suggestion.
A lightweight planner then compares their ideas, checks projected cost, and decides which action to execute inside the Sequential Diagnosis Benchmark. New facts flow back to the panel, the debate restarts, and the loop continues until the planner judges that evidence is strong enough to lock in a diagnosis.
Because the planner never touches medical knowledge itself, it can swap the underlying model at runtime. The swap only changes how smart each agent sounds, not how the orchestration logic moves information, records costs, or stores the full reasoning trail.
In short, the orchestrator is a model-agnostic manager that turns one foundation model into a transparent, cost-aware virtual care team.
So what's so special about this❓
Complex medical cases still cause missed or delayed diagnoses and drive up costs.
🧩 Multiple-choice benchmarks hide real weaknesses in medical AI, because selecting a single answer from a list rewards memorization and ignores the step-by-step reasoning clinicians use.
USMLE style exams (i.e. the ones used till now for benchmarking medical LLMs) hand the entire patient scenario to the model in one block and ask for a single choice answer. A language model can match wording patterns it has seen during training and guess the right letter without tracing the kind of step-by-step logic that happens in clinic.
So to test the system, Microsoft created a new challenge called the Sequential Diagnosis Benchmark (SD Bench), based on 304 real NEJM cases. Its a Sequential Diagnosis Benchmark that feeds information bit by bit, just as a clinic visit unfolds.
The model first sees a brief vignette, then must pick the next question or test, pay a virtual cost, receive the result, and update its working diagnosis.
This loop repeats until the model decides it has enough evidence to state a final diagnosis that is scored against New England Journal of Medicine ground truth.
Because every action has a price, the benchmark also measures how many labs or scans the model orders, exposing wasteful or reckless behaviour.
The recorded chain of thoughts and spending shows exactly where the model hesitates or backtracks, detail that a one shot multiple choice score never reveals.
On this benchmark the MAI-DxO orchestrator raises accuracy and cuts testing cost, proving that stepwise evaluation highlights strengths and weaknesses that USMLE style quizzes hide.
Architecture

The above diagram maps how MAI-DxO turns any large language model into a virtual panel of 5 doctor agents that debate each patient case.
MAI-Dx sits inside the large cream rectangle in the middle of the figure, titled “MAI-Dx Orchestrator”. This rectangle encloses the ring of five colored agent icons that form the virtual doctor panel and the decision loop shown below them.
The panel first sees a short vignette from the Sequential Diagnosis Benchmark, then decides to ask a follow up question, order a test, or announce a diagnosis.
Each action carries a virtual cost, so after the test result arrives the panel runs a cost check and a logic review before choosing whether to keep investigating.
This loop repeats until the panel is satisfied, producing a final diagnosis plus a transparent record of every question, test, and dollar spent.
Because the orchestrator sits above the language model, the same workflow can run on o3, Claude, Gemini, or any future model with no code change.
By forcing gradual information flow, internal debate, and cost tracking, the system fixes blind spots in one shot multiple choice exams and achieves higher accuracy with fewer unnecessary tests.
Avaiability
SD Bench and MAI-DxO are research demonstrations only and are not currently available as public benchmarks or orchestrators. Microsoft are in the process of submitting this work for external peer review and are actively working with partners to explore the potential to release SDBench as a public benchmark.
🗞️ Byte-Size Briefs
Mark Zuckerberg announces creation of Meta Superintelligence Labs. He folded every research, infrastructure, and product AI team into Meta Superintelligence Labs, or MSL. It now holds FAIR, Llama engineering, and a frontier lab chasing superintelligence. Scale AI founder Alexandr Wang to become Chief AI Officer and ex-GitHub CEO Nat Friedman to run applied research.
The report also published then names of new joiners to this team, who have joined in the past few weeks. And from many sources, each of these new members are getting a massive $10mn+ package at the MSL.

That’s a wrap for today, see you all tomorrow.